
%ignore_a_1%是一种基于二叉堆的比较排序算法,先构建最大堆再逐个将堆顶最大值与末尾元素交换并调整堆,最终实现升序排列。


堆排序是一种基于比较的排序算法,它利用了二叉堆这种数据结构来实现。二叉堆本质上是一个完全二叉树,并且满足堆的性质:父节点的值总是大于或等于(最大堆)或小于或等于(最小堆)其子节点的值。
堆排序的基本原理
堆排序主要分为两个阶段:
建堆:将无序数组构造成一个最大堆(升序排序时)或最小堆(降序排序时)。最大堆的根节点是当前堆中最大的元素。排序:反复将堆顶元素(最大值)与堆的最后一个元素交换,然后减少堆的大小,并对新的堆顶进行调整,使其重新满足堆的性质。
这个过程持续进行,直到整个数组有序。
关键操作:堆化(heapify)
堆排序的核心是heapify函数,它的作用是让某个子树满足堆的性质。通常从最后一个非叶子节点开始,自底向上进行堆化,构建初始堆。
立即学习“Python免费学习笔记(深入)”;
 bee餐饮点餐外卖小程序
bee餐饮点餐外卖小程序
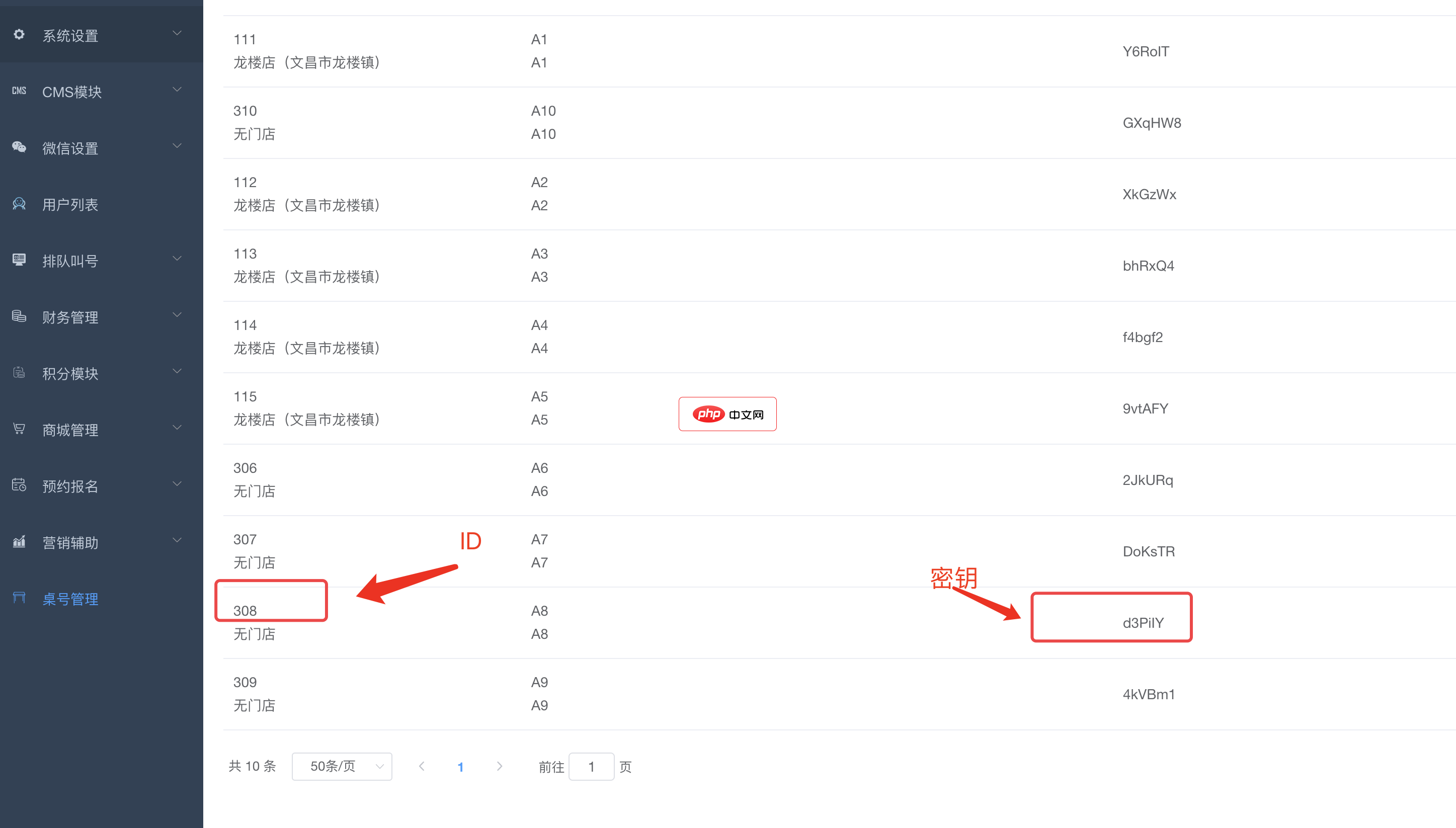
bee餐饮点餐外卖小程序是针对餐饮行业推出的一套完整的餐饮解决方案,实现了用户在线点餐下单、外卖、叫号排队、支付、配送等功能,完美的使餐饮行业更高效便捷!功能演示:1、桌号管理登录后台,左侧菜单 “桌号管理”,添加并管理你的桌号信息,添加以后在列表你将可以看到 ID 和 密钥,这两个数据用来生成桌子的二维码2、生成桌子二维码例如上面的ID为 308,密钥为 d3PiIY,那么现在去左侧菜单微信设置
 1 查看详情 例如:对于数组 [4, 10, 3, 5, 1],先将其看作完全二叉树,然后从下往上调整,最终形成最大堆 [10, 5, 3, 4, 1]。
1 查看详情 例如:对于数组 [4, 10, 3, 5, 1],先将其看作完全二叉树,然后从下往上调整,最终形成最大堆 [10, 5, 3, 4, 1]。
Python 实现示例
以下是一个用 Python 实现的堆排序代码:
def heapify(arr, n, i): largest = i left = 2 * i + 1 right = 2 * i + 2if left arr[largest]: largest = leftif right arr[largest]: largest = rightif largest != i: arr[i], arr[largest] = arr[largest], arr[i] heapify(arr, n, largest)def heap_sort(arr):n = len(arr)
# 构建最大堆for i in range(n // 2 - 1, -1, -1): heapify(arr, n, i)# 逐个提取元素for i in range(n - 1, 0, -1): arr[0], arr[i] = arr[i], arr[0] heapify(arr, i, 0)调用
heap_sort([64, 34, 25, 12, 22, 11, 90])后,数组会变为有序状态。堆排序的特点
时间复杂度:O(n log n),无论最好、最坏、平均情况都一样。空间复杂度:O(1),是原地排序算法。不稳定:相同元素的相对位置可能改变。
基本上就这些。堆排序虽然不如快排常用,但在某些限制内存或要求最坏情况性能稳定的场景中很有用。理解它有助于掌握优先队列和堆结构的应用。
以上就是python堆排序是什么?的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/917906.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 