

1、 同期对比分析是数据分析中的基础方法之一,主要用于比较相同时间段在不同年份之间的数据变化。
2、 上图所示为一种典型的月度统计报表样式,广泛应用于企业日常经营数据的汇总与展示。
3、 该类月报的实现逻辑与勤哲Excel服务器中“含本期累计”的日报类似,均需配置三条表间计算规则,以实现数据的自动联动和层级汇总。
4、 首先需要从数据库中提取所有产品的名称信息,作为报表维度基础。
5、 查询当月数据时,需通过行与列的交叉匹配方式定位具体数值。
6、 在获取去年同期数据的过程中,同样需要进行行列匹配操作,确保时间维度准确对应。
7、 相比之下,FineReport作为专业级报表工具,在同期比分析方面功能更为完善。其应用场景覆盖更广,能够满足复杂多变的数据分析需求,灵活性和扩展性优于传统Excel解决方案。
8、 FineReport通过将单元格绑定至数据字段来实现数据读取与动态展示。其独特的扩展机制支持单元格根据数据量自动生成多个实例。设计过程中,可通过层次化坐标精确定位任意扩展后的单元格,并调用相关联的数据记录。类似于Excel的操作体验,FineReport也支持多种扩展后计算功能,如自增编号、排名、占比、累计求和、同比及环比等。其中,同期比用于衡量当前周期与上一年相同周期的数据差异,常用于趋势判断与业绩评估。通过设置相应公式,可自动计算出同比增长率,帮助用户清晰掌握业务发展动态。此功能在财务报告、销售分析等领域应用普遍,显著增强了报表的数据表达能力。
9、 所谓同期比,即指将本年度各月份的数据与上年同一月份进行对比计算,反映同比增减情况。
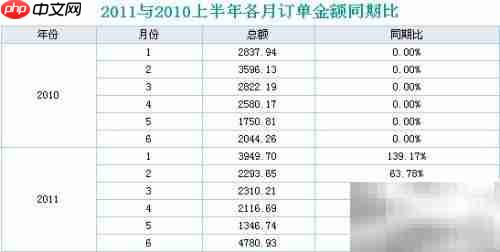
10、 进入报表设计界面
11、 打开路径 %FR_HOME%WebReportWEB-INF/reportlets/doc/AdvancedCacuate_Between_CellsProportion.cpt 的报表文件,确认其正常加载,以便开展后续编辑与数据验证工作。
12、 修改ds1数据集的SQL查询语句为:select strftime(%Y,订购日期) as 年份, strftime(%m,订购日期) as 月份,应付金额 from 订单,目的是提取每条订单的年份、月份以及应付金额,从而获得按年月划分的完整金额数据集。
 九歌
九歌
九歌–人工智能诗歌写作系统
 322 查看详情
322 查看详情 
13、 按以下结构调整报表布局:

14、 展示与去年同期相比的变化比率
15、 在D3单元格中输入公式:=IF(&A3>1,C3/C3,0),并设置月份单元格为其父格,使其随月份维度自动扩展。当&A3大于1(即非首年)时,执行当月数据与上年同期数据的比值运算;否则返回0。
16、 C3在此上下文中表示:基于当前A3单元格向上移动一行所对应的年份,在相同月份列下查找C3位置的数据值。由于引用逻辑一致,结果仍等于C3原始值。
17、 完成设置后保存文件,并进入预览模式查看实际效果。
18、 可参考系统内置模板文件:%FR_HOME%WebReportWEB-INF eportletsdocAdvancedCacuate_Between_CellsPeriodChain.cpt,该模板涵盖了单元格间跨期计算、环比分析等内容,适合学习其结构设计与公式实现方式。
19、 小结:关于相对层级中父格坐标的理解与应用
20、 内容说明如下:
21、 相对层级坐标定位机制是指:以当前单元格为原点,通过设定行和列的方向偏移量来锁定目标单元格的位置。该方法适用于动态表格处理,能保证在基准单元变动时,关联位置同步调整,保持逻辑一致性。
22、 父子格之间具有层级依存关系。例如D3的直接父格为B3,而B3的父格为A3,则A3即为D3的上级父格。若仅指定高级父格(如A3)的位置,未显式定义下级父格偏移量,则系统默认其相对于高级父格的偏移为+0,即自动沿用高级父格中对应子格的相对位置作为默认值。
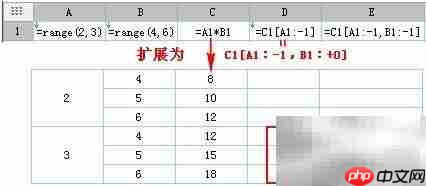
以上就是勤哲Excel同期比入门的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1006400.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















