
阿里巴巴通义实验室近日正式发布了 funaudio-asr —— 一款面向企业级应用场景的端到端语音识别大模型。该模型不仅具备出色的通用语音识别精度,更通过独创的 context 增强模块,有效应对工业落地中的“语义幻觉”、“多语种混杂”等核心挑战。
其核心技术亮点在于引入了创新性的“Context 模块”,显著提升了在高噪声环境下的识别稳定性与准确性。实测数据显示,模型的幻觉率从原先的78.5%大幅下降至10.7%,降幅接近70%,为行业树立了新的性能标杆。这一突破尤其适用于会议现场、交通枢纽等复杂声学场景。
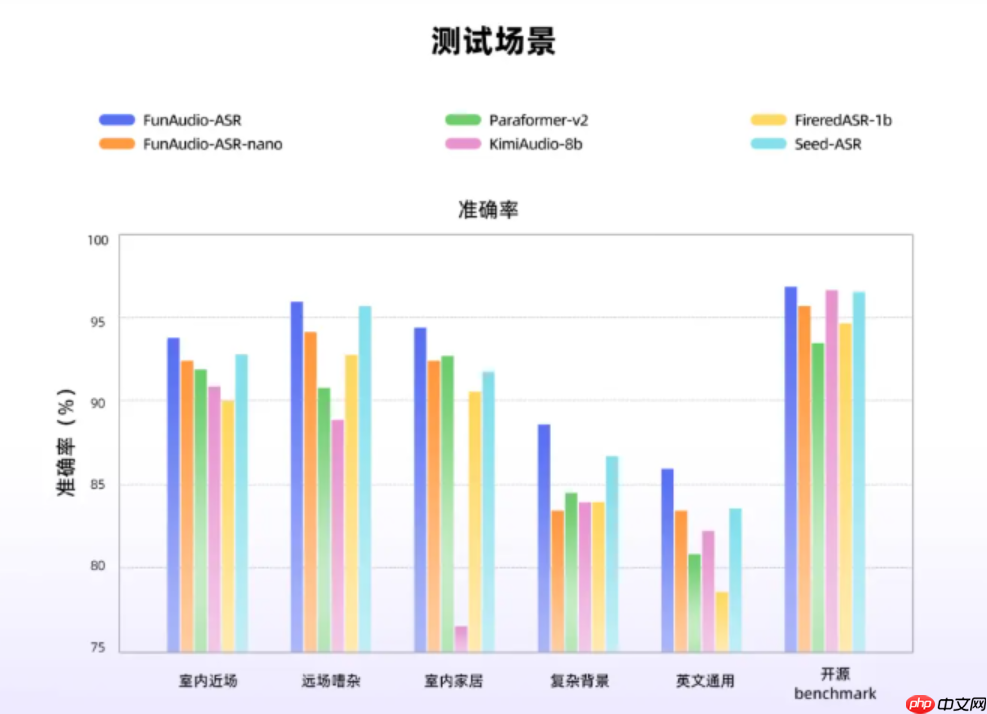
FunAudio-ASR 在训练过程中融合了数千万小时的真实音频数据,并深度整合大语言模型的语义理解能力,使其在远场拾音、背景嘈杂、多人交替发言等典型难题下,表现优于 Seed-ASR、KimiAudio-8B 等主流系统。用户因此可以获得更加清晰、连贯且精准的转录结果。
为满足多样化部署需求,阿里同步推出了轻量版模型 FunAudio-ASR-nano。该版本在保证识别质量的同时,大幅优化了计算资源消耗和推理延迟,特别适合边缘设备或资源受限环境下的快速部署,为企业及中小型开发团队提供了灵活高效的解决方案。

目前,FunAudio-ASR 已成功应用于钉钉“AI 听记”功能、在线视频会议系统以及 DingTalk A1 硬件设备中。同时,其开放 API 已上线阿里云百炼平台,开发者可便捷调用并集成至自有应用。对企业而言,这项技术将显著提升会议记录效率,强化信息捕捉能力,推动智能办公迈向新阶段。
以上就是阿里巴巴推出端到端语音识别大模型 FunAudio-ASR的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/101934.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























