
驱动人生是一款功能强大的电脑硬件驱动管理工具,其主要特点在于能够通过一键智能扫描,识别计算机中的各类硬件设备,并自动匹配、下载及安装最适合的驱动程序。这一功能大幅降低了用户手动搜索和更新驱动的复杂度,有效应对因驱动版本过旧、缺失或不兼容所引发的设备无法识别、运行卡顿、系统蓝屏等问题。此外,该软件还具备驱动备份、恢复、卸载等实用功能,同时整合了硬件信息查看、系统垃圾清理等辅助模块,全方位提升电脑的稳定性与运行效率,是用户进行驱动维护的理想选择。下面将详细介绍如何关闭驱动人生的自动检测功能,帮助用户按需使用该软件。
第一步
启动电脑并进入操作系统后,找到桌面上的驱动人生快捷图标,双击打开,进入软件主界面。
第二步
在主界面的右上角位置,找到菜单按钮(通常为三条横线或齿轮图标),点击以展开下拉菜单。
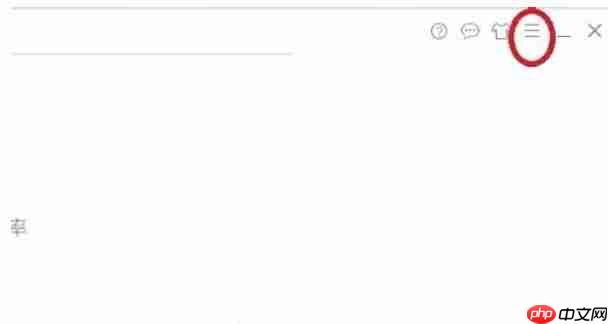
第三步
在弹出的菜单中,选择“设置”选项,进入软件的配置页面。
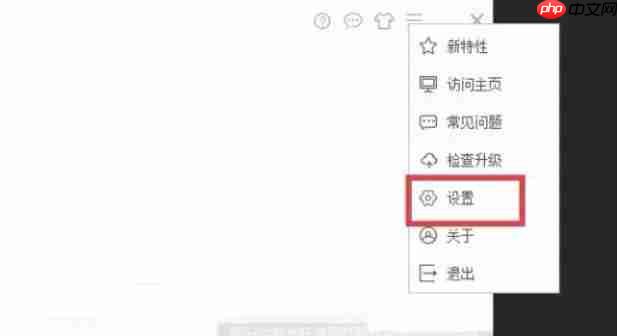
第四步
 Seede AI
Seede AI
AI 驱动的设计工具
 586 查看详情
586 查看详情 
在设置界面中,左侧列出了多个功能分类,点击“基本设置”进入相关选项。
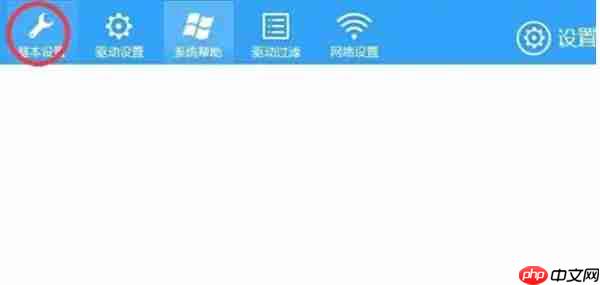
第五步
在基本设置区域中,向下滚动至“驱动体验”部分,找到“不自动检测”这一选项,并将其选中。
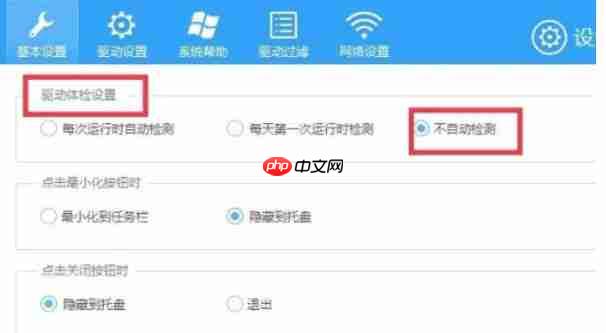
第六步
设置完成后,点击设置窗口右下角的“确定”按钮,保存更改。此后再次启动驱动人生时,将不再自动执行驱动检测。
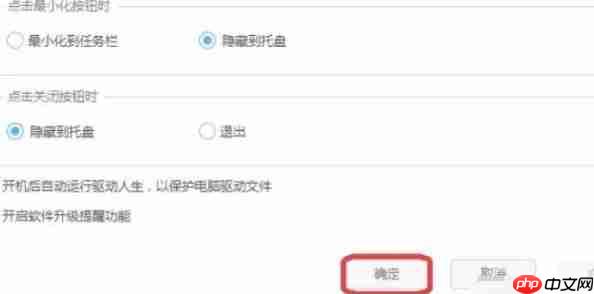
以上就是驱动人生怎么关闭自动检测-驱动人生关闭自动检测的方法的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1038953.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 























