ForkJoinPool通过工作窃取机制提升并行计算效率,其核心为分而治之算法,使用RecursiveTask拆分任务并合并结果,需合理设置阈值、避免阻塞操作,并可利用commonPool优化资源使用。

在Java中处理大规模并行计算时,ForkJoinPool 是一个非常高效的工具。它专为“分而治之”(divide-and-conquer)算法设计,能够充分利用多核CPU资源,提升计算密集型任务的执行效率。相比传统的线程池,ForkJoinPool 通过工作窃取(work-stealing)机制,让空闲线程从其他线程的任务队列中“窃取”任务,从而更均衡地分配负载。
理解ForkJoinPool的核心机制
ForkJoinPool 是 Java 7 引入的并发工具类,位于 java.util.concurrent 包中。它的核心思想是将一个大任务拆分成多个小任务(fork),然后并行执行这些小任务,最后合并结果(join)。
关键组件包括:
ForkJoinTask:表示可以被 ForkJoinPool 执行的任务,常用子类有 RecursiveTask(有返回值)和 RecursiveAction(无返回值)。工作窃取:每个线程维护自己的双端队列,任务被压入队尾。当某个线程完成自己的任务后,会从其他线程的队列头部“窃取”任务执行,减少线程等待时间。并行度控制:可通过构造函数设置并行级别,默认为 CPU 核心数减一(保留一个核心处理其他系统任务)。
使用RecursiveTask实现并行求和
以数组求和为例,展示如何利用 ForkJoinPool 提升性能。当数组很大时,递归拆分能显著加快处理速度。
立即学习“Java免费学习笔记(深入)”;
 Pic Copilot
Pic Copilot
AI时代的顶级电商设计师,轻松打造爆款产品图片
 158 查看详情
158 查看详情 
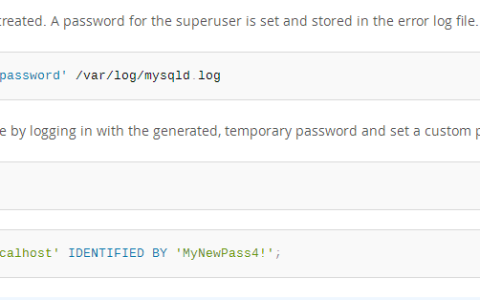
import java.util.concurrent.ForkJoinPool;import java.util.concurrent.RecursiveTask;public class SumTask extends RecursiveTask {private final long[] array;private final int start;private final int end;private static final int THRESHOLD = 1000; // 拆分阈值
public SumTask(long[] array, int start, int end) { this.array = array; this.start = start; this.end = end;}@Overrideprotected Long compute() { if (end - start <= THRESHOLD) { // 小任务直接计算 long sum = 0; for (int i = start; i < end; i++) { sum += array[i]; } return sum; } else { // 拆分为两个子任务 int mid = (start + end) / 2; SumTask left = new SumTask(array, start, mid); SumTask right = new SumTask(array, mid, end); left.fork(); // 异步提交左任务 long rightResult = right.compute(); // 当前线程执行右任务 long leftResult = left.join(); // 等待左任务结果 return leftResult + rightResult; }}public static void main(String[] args) { long[] data = new long[1_000_000]; for (int i = 0; i < data.length; i++) { data[i] = i; } ForkJoinPool pool = new ForkJoinPool(); SumTask task = new SumTask(data, 0, data.length); long result = pool.invoke(task); System.out.println("Sum: " + result); pool.shutdown();}}
在这个例子中,当任务规模小于阈值时直接计算,否则拆分。注意 fork() 提交任务但不阻塞,compute() 执行当前任务,join() 获取结果并等待完成。
优化技巧与注意事项
要真正发挥 ForkJoinPool 的优势,需注意以下几点:
合理设置拆分阈值:太小会导致任务过多,调度开销大;太大则无法充分利用并行性。一般根据数据量和任务复杂度调整,常见值在 500~5000 之间。避免阻塞操作:ForkJoinPool 的工作线程不适合执行 I/O 阻塞或长时间等待的任务,否则会拖慢整个池的效率。这类任务应使用专门的线程池(如 ThreadPoolExecutor)。优先使用默认公共池:Java 8 提供了 ForkJoinPool.commonPool(),可通过 CompletableFuture 默认使用它。对于通用并行流(parallelStream),底层也是基于 commonPool。监控并行度:可通过 getParallelism() 查看实际并行度,并结合系统负载调整。异常处理:任务中抛出的异常会被封装,调用 join() 或 get() 时会重新抛出,建议在 compute() 中做好 try-catch 处理。
基本上就这些。ForkJoinPool 不复杂但容易忽略细节,掌握好拆分策略和运行环境,就能有效提升计算性能。尤其适合递归结构、大数据集处理等场景。
以上就是在Java中如何使用ForkJoinPool优化并行计算_ForkJoinPool并行优化技巧说明的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1054992.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫