一、初识决策树
想象一个生活中的场景,我们去水果店买一个西瓜,该怎么判断一个西瓜是不是又甜又好的呢?我们可能会问自己一系列问题:
首先看看它的纹路清晰吗?如果“是”,那么它可能是个好瓜。如果“否“,那我们可能会问下一个问题:敲起来声音清脆吗? 如果“是”,那么它可能还是个不错的瓜。如果“否“,那我们很可能就不会买它了。
这个过程,就是你大脑中的一棵“决策树”。决策树算法,就是让计算机从数据中自动学习出这一系列问题和判断规则的方法。
二、什么是决策树
1. 核心思想
它的核心思想非常简单:通过提出一系列问题,对数据进行层层筛选,最终得到一个结论(分类或预测)。每一个问题都是关于某个特征的判断(例如:“纹路是否清晰?”),而每个答案都会引导我们走向下一个问题,直到得到最终答案。
2. 决策树的结构
一棵成熟的决策树包含以下部分:
根节点:代表第一个、也是最核心的问题(例如:“纹路清晰吗?”)。它包含所有的初始数据。内部节点:代表中间的问题(例如:“声音清脆吗?”)。叶节点:代表最终的决策结果(例如:“买”或“不买”)。分支:代表一个问题的可能答案(例如:“是”或“否”)。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

三、决策树的执行流程
1. 流程图
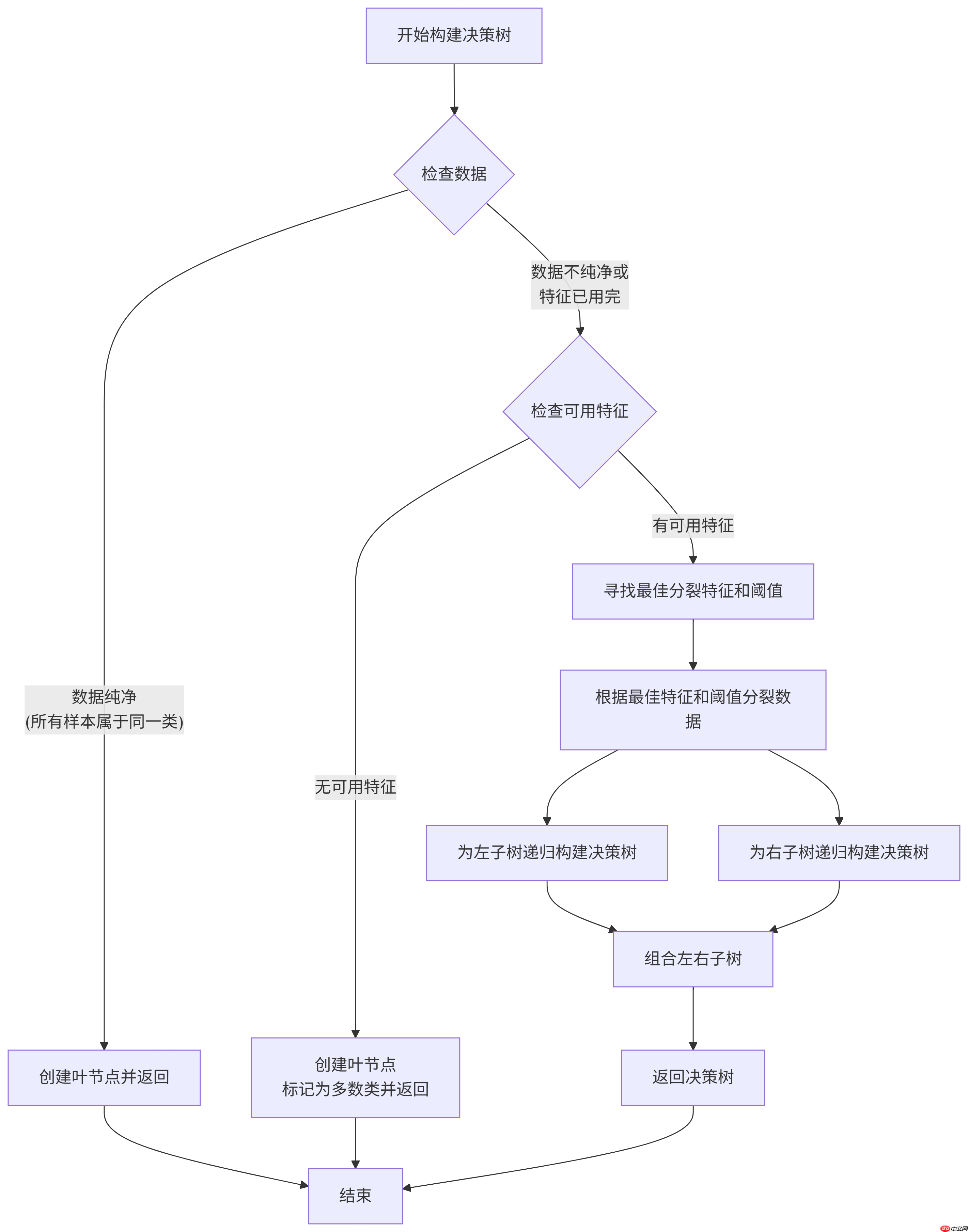
2. 构建过程
开始构建决策树:算法从根节点开始,包含所有训练样本。检查数据: 如果当前节点的所有样本属于同一类别,则创建一个叶节点并返回如果数据不纯净或还有特征可用,继续下一步检查可用特征: 如果没有更多特征可用于分裂,创建一个叶节点并标记为多数类如果有可用特征,继续下一步寻找最佳分裂特征和阈值: 计算所有可能特征和阈值的信息增益/基尼不纯度减少量选择能够最大程度减少不纯度的特征和阈值根据最佳特征和阈值分裂数据: 将当前节点的数据分成两个子集左子集:特征值 ≤ 阈值的样本右子集:特征值 > 阈值的样本递归构建子树: 对左子集递归调用决策树构建算法对右子集递归调用决策树构建算法组合子树:将左右子树组合到当前节点下返回决策树:返回构建完成的决策树
四、怎么理解决策树
现在我们来解决最关键的问题:计算机如何从一堆数据中自动找出最好的提问顺序?
1. 关键问题:根据哪个特征进行分裂?
假设我们有一个西瓜数据集,包含很多西瓜的特征(纹路、根蒂、声音、触感…)和标签(好瓜/坏瓜)。 在根节点,我们有所有数据。算法需要决定:第一个问题应该问什么? 是问“纹路清晰吗?”还是“声音清脆吗?”?
选择的标准是:哪个特征能最好地把数据分开,使得分裂后的子集尽可能纯净。所谓纯净,就是同一个子集里的西瓜尽可能都是好瓜,或者都是坏瓜。
2. 衡量标准:“不纯度”的度量
我们如何量化“纯度”呢?科学家们设计了几种指标来衡量“不纯度”:
信息熵:熵越高,表示数据越混乱,不纯度越高。基尼不纯度: 计算一个随机选中的样本被错误分类的概率。基尼不纯度越高,数据越不纯。
3. 核心概念:信息增益
决策树算法通过计算信息增益来决定用什么特征分裂。
信息增益 = 分裂前的不纯度 – 分裂后的不纯度
信息增益越大,说明这个特征分裂后,数据的纯度提升得越多,这个特征就越应该被用来做分裂。
简单比喻:
分裂前:一筐混在一起的红豆和绿豆,此时纯度不高。用筛子A分裂:分成了两堆,一堆大部分是红豆,另一堆大部分是绿豆,此时纯度显著提升,信息增益大。用筛子B分裂:分成了两堆,但每一堆还是红豆绿豆混合,此时纯度没什么变化,信息增益小。显然,筛子A是更好的选择。在决策树中,算法会尝试所有筛子(特征),找到那个筛得最干净的,即信息增益最大的。
4. 核心算法
ID3: 使用信息增益作为分裂标准。缺点:倾向于选择取值多的特征。C4.5: ID3的改进版,使用信息增益率作为标准,克服了ID3的缺点。CART: 最常用的算法,既可分类也可回归。分类时使用基尼不纯度,回归时使用平方误差。
5. 停止条件
不能无限地分下去,否则每个叶节点可能只有一个样本(过拟合)。停止条件包括:
节点中的样本全部属于同一类别(已经100%纯了)。没有更多的特征可供分裂。树达到了预设的最大深度。节点中样本数少于某个阈值(再分下去意义不大)。
五、构建决策树
理论深奥让人难以琢磨,我们来点实际的。用经典的scikit-learn库,建一棵决策树,细细的分析一下里面的每个步骤;
1. 示例代码
import pandas as pdimport numpy as npfrom sklearn import treefrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_scoreimport matplotlib.pyplot as pltimport matplotlib.font_manager as fmfrom io import StringIOimport pydotplusfrom IPython.display import Image # 1. 设置中文字体支持# 尝试使用系统中已有的中文字体plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans', 'Arial Unicode MS', 'Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题 # 2. 创建示例数据集(使用鸢尾花数据集,但用中文重命名)iris = load_iris()X = iris.datay = iris.target # 创建中文特征名称和类别名称chinese_feature_names = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']chinese_class_names = ['山鸢尾', '变色鸢尾', '维吉尼亚鸢尾'] # 3. 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42) # 4. 创建并训练决策树模型clf = tree.DecisionTreeClassifier( criterion='gini', # 使用基尼不纯度 max_depth=3, # 限制树深度,防止过拟合 min_samples_split=2, # 节点最小分裂样本数 min_samples_leaf=1, # 叶节点最小样本数 random_state=42 # 随机种子,确保结果可重现)clf.fit(X_train, y_train) # 5. 评估模型y_pred = clf.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print(f"模型准确率: {accuracy:.2%}") # 6. 可视化决策树 - 方法1:使用Matplotlib(简单但不支持中文特征名)plt.figure(figsize=(20, 12))tree.plot_tree( clf, feature_names=chinese_feature_names, # 使用中文特征名 class_names=chinese_class_names, # 使用中文类别名 filled=True, # 填充颜色表示类别 rounded=True, # 圆角节点 proportion=True, # 显示比例而非样本数 precision=2 # 数值精度)plt.title("决策树可视化 - 鸢尾花分类", fontsize=16)plt.savefig('decision_tree_chinese.png', dpi=300, bbox_inches='tight')plt.show()2. 结果展示
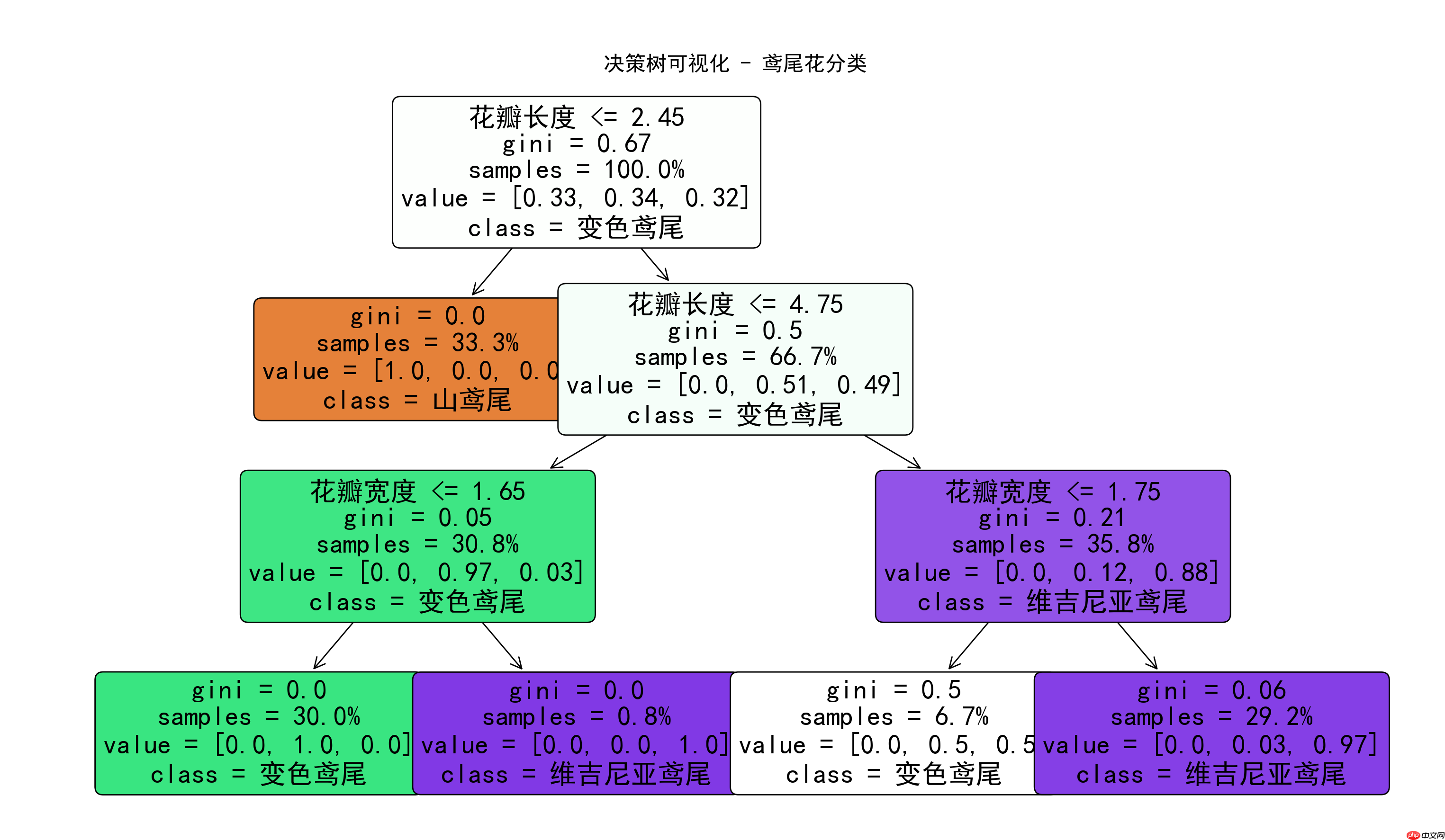
3. 决策的基础:鸢尾花分类
这是一个鸢尾花分类的决策过程,首先简单描述一下鸢尾花分类的基础知识,鸢尾花分类是一个经典的机器学习入门问题,也是一个多类别分类任务。其目标是根据一朵鸢尾花的花瓣和花萼的测量数据,自动判断它属于三个品种中的哪一种。
接下来这些很重要,很重要,很重要!
3.1 三种鸢尾花
Iris Setosa:山鸢尾,最容易识别,花瓣短而宽,花萼较大。Iris Versicolor:变色鸢尾,介于另外两种之间,颜色多变。Iris Virginica:维吉尼亚鸢尾,最大最壮观,花瓣和花萼尺寸都最大。
3.2 数据集的构成
整个数据集就是一个大表格,有150行(代表150朵不同的花)和5列。
品种 (标签)
花萼长度
花萼宽度
花瓣长度
花瓣宽度
Iris-setosa
5.1
3.5
1.4
0.2
Iris-versicolor
7.0
3.2
4.7
1.4
Iris-virginica
6.3
3.3
6.0
2.5
…
 Revid AI
Revid AI
AI短视频生成平台
 96 查看详情
96 查看详情 
…
…
…
数据集包含150个样本,每个样本有4个特征和1个标签:
4个特征(预测依据): sepal length (cm) – 花萼长度 sepal width (cm) – 花萼宽度 petal length (cm) – 花瓣长度 petal width (cm) – 花瓣宽度1个标签(预测目标): species – 品种(0: Setosa, 1: Versicolor, 2: Virginica)
3.3 经典的鸢尾花数据集
它之所以成为经典,是因为它具备了一个完美教学数据集的所有特点:
简单易懂:问题本身非常直观,不需要专业知识。维度适中:4个特征不多不少,易于可视化和理解,又能体现多维度分析的价值。清晰可分离:Setosa与其他两种花线性可分,Versicolor和Virginica之间存在重叠但仍有明显模式,提供了一个从易到难的学习过程。干净完整:数据经过精心整理,没有缺失值或异常值,让学生可以专注于算法本身。免费开源:被内置在几乎所有机器学习库中(如scikit-learn),易于获取和使用。
4. 数据分析
看到这个图,首先要明白这是在决策鸢尾花具体是属于哪一种类型,每一层都有几个值:花瓣长度、gini、samples、value、class,其中:
gini:基尼不纯度值,衡量随机抽取两个样本,它们属于不同类别的概率,越小表示节点纯度越高,分类效果越好samples:当前节点包含的样本数量value:样本在三类鸢尾花中的分布class:当前节点的预测类别
先了解概念,在了解具体的公式和推导值;
4.1 第一步:判断“花瓣长度
此处非常有意思,2.45是怎么来的,是固定的还是随机抽取的,首先这不是随意的,而是通过严密的数学计算和优化选择得出的结果:
从最直观理解,数据分布的角度,花瓣长度的数据分布一般在:
Setosa的花瓣长度分布: 1.0 – 2.0 cmVersicolor的花瓣长度分布: 3.0 – 5.1 cm Virginica的花瓣长度分布: 4.5 – 6.9 cm
由上得知可以看到:
Setosa的花瓣长度完全与其他两种花不重叠2.45cm正好落在Setosa的最大值(2.0cm)和Versicolor的最小值(3.0cm)之间
这个点能够完美地将Setosa从其他两种花中分离出来
其次,最有依据的是基于准确的数学方法,最佳分裂点(先了解,后面会细讲):
在花瓣长度上,2.45cm附近的阈值能产生最低的gini值,即数据纯度越高(先了解,后面会细讲)花瓣长度特征的整体区分效果最好
4.2 samples(样本总量)100%
这个很好理解,此时抽取的是所有样本,所有数量为100%。
4.3 value = [0.33, 0.34, 0.32]
value表示的是每个样本在三类鸢尾花中的分布,这里也比较有趣味性了,按常理来说应该都是均分,都应该是0.3333,为什么会有差异呢,与训练集和测试集的分布有关系,这个比例会随着你划分训练集和测试集的方式不同而发生微小的变化。
简单看看这个变化的过程:
4.3.1 数据的初始状态:理论上应该是固定的
鸢尾花数据集本身有150个样本,每个品种(Setosa, Versicolor, Virginica)各50个。因此,在整个数据集中,每个类别的比例是精确的:
value = [50/150, 50/150, 50/150] = [0.333…, 0.333…, 0.333…]
所以,如果你在根节点看到 value = [0.33, 0.34, 0.32] 而不是完美的 [0.333, 0.333, 0.333],这已经暗示了我们没有使用全部150个样本。
4.3.2 为什么我们看到的不是固定值?—— 训练集与测试集的划分
在机器学习中,我们不会用全部数据来训练模型。为了评估模型的真实性能,我们通常会将数据划分为训练集和测试集。
训练集:用于“教导”模型,让它学习规律。测试集:用于“考试”,评估模型在未见过的数据上的表现。
最常用的划分比例是 80% 的数据用于训练,20% 用于测试。
关键点就在这里:150 * 0.8 = 120。现在,训练集只剩下120个样本。原来每个类别有50个,但在随机抽取80%后,每个类别在训练集中的数量几乎是 50 * 0.8 = 40,但不会那么精确。
可能Setosa被抽走了39个,Versicolor被抽走了41个,Virginica被抽走了40个。那么在根节点,比例就变成了 [39/120, 41/120, 40/120] = [0.325, 0.341, 0.333]。当这些值被四舍五入到小数点后两位显示时,就可能出现 [0.33, 0.34, 0.32] 或 [0.32, 0.34, 0.33] 等各种组合。
4.3.3 random_state 参数的作用
您可能注意到了上面代码中的 random_state=42。这个参数控制了随机抽样的“种子”。
如果设置 random_state:每次运行代码,划分结果都是一样的。因此 value 的值也是固定的。42 只是一个常用例子,你可以用任何数字。如果不设置 random_state:每次运行代码,都会进行一次新的随机划分。因此每次看到的 value 值都可能略有不同。
所以,value 的值是“固定”还是“变化”,完全取决于你的代码配置。
4.3.4 抽取的流程
下面这张图展示了数据如何从原始全集被随机划分到训练集,从而导致节点中类别比例发生微小变化的过程:
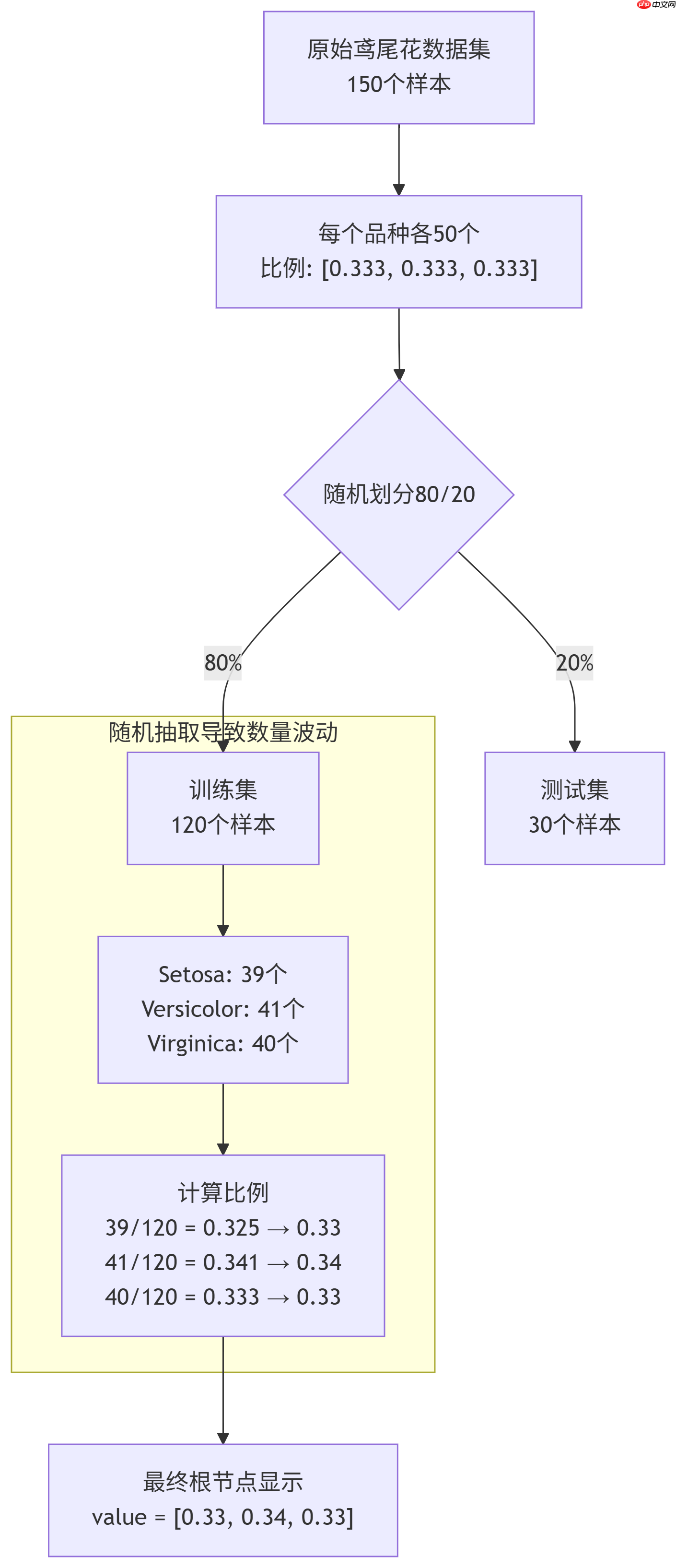
所以,看到的 [0.33, 0.34, 0.32] 是一个在随机划分训练集后,各类别比例的正常、微小的波动表现,并不意味着数据或代码有问题。
4.4 gini = 0.67
gini值计算的公式:
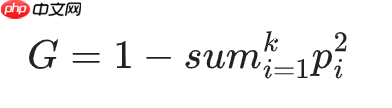
其中:
k为类别总数(鸢尾花分类中 ) Pi为第i类样本占比
根节点参数:
value = [0.33, 0.34, 0.32](三类鸢尾花样本占比)G = 1 – (0.33的平方 + 0.43的平方 + 0.32的平方)= 1 – (0.1089+0.1156+0.1024) = 1 – 0.3269 = 0.6731结果四舍五入后与图示根节点的0.67高度吻合
4.5 class = 变色鸢尾
对应的占比,中间的Iris Versicolor变色鸢尾比例为0.34居多,所以当前的预测类别偏重于变色鸢尾。
4.6 花瓣长度
4.6.1 结果成立
如果结果成立则走第二次的左侧节点,直接判定为山鸢尾,流程结束。
强化值计算:
value = [1,0, 0 ,0], 由于此节点一句明确是山鸢尾类型了,所有只有山鸢尾的样本数,并为100%即1,其他则为0gini = 0.0 -> 计算方式:1 – (1.0*1.0+0*0+0*0) = 1-1 = 0samples =33.3% 从第一层的样本比例继承class = 山鸢尾,100%的山鸢尾类型选择了
4.6.2 如果结果不成立
如果结果成立则走第二次的右侧节点,继续下一步的决策,调整判断参数,判断“花瓣长度samples = 66.7%,由于已经排除了不是山鸢尾类型,所以此时的样本比例为1-33.3%=66.7%value = [0.0, 0.51, 0.49],同样排除了山鸢尾类型,第一个样本为0,第二个参考第一层的 0.34/(0.34 + 0.32) = 0.5151,第三个样本参考 0.32/(0.34 + 0.32) = 0.4848gini = 0.5 -> 计算方式:1 – (0*0+0.51*0.51+0.49*0.49) = 1-0.5002 = 0.5class = 变色鸢尾,比例相对最高的类型
按照这样的思路,逐步分析决策,最终匹配到最适合的类型;如果还是有疑问,可以从根节点开始,跟着它的条件一步步走,看看模型是如何根据花的尺寸来分类的。这就像看到了模型的“思考过程”,非常直观!
六、决策树的优缺点
1. 优点
极其直观,易于解释:这是它最大的优点!你可以把它展示给任何人,即使不懂技术也能理解。这在医疗、金融等领域非常重要。需要很少的数据预处理:不需要对数据进行标准化或归一化。可以处理各种数据:既能处理数字(如花瓣长度),也能处理类别(如颜色红/绿/蓝)。
2. 缺点
容易过拟合:如果不加控制,树会长得非常复杂,完美记忆训练数据中的每一个细节(包括噪声),但在新数据上表现很差。这就像死记硬背了考题答案,但不会举一反三的学生。
七、 总结
决策树是机器学习中最基础、最直观的算法之一:
通过计算信息增益(或基尼不纯度减少),选择最能区分数据的特征来提问。使用scikit-learn库几行代码就能实现,并且可以可视化,非常利于理解和解释。理解决策树是学习机器学习非常好的一步,它不仅是一个强大的工具,其思想也是很多更复杂算法(如随机森林、梯度提升树)的基石。希望这篇基础的讲解能帮你帮你初步理解决策树,在这个基础上,后面我们讲一下决策树的基础分裂点是怎么一步步计算出来的!
以上就是构建AI智能体:决策树的核心机制(一):刨根问底鸢尾花分类中的参数推理计算的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1056486.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫