
5 月 15 日消息,华为 nova 12 Ultra 星耀版手机官宣 5 月 17 日 10:08 开售,目前该机价格已在华为商城公布:
 绘蛙AI修图
绘蛙AI修图
绘蛙平台AI修图工具,支持手脚修复、商品重绘、AI扩图、AI换色
 285 查看详情
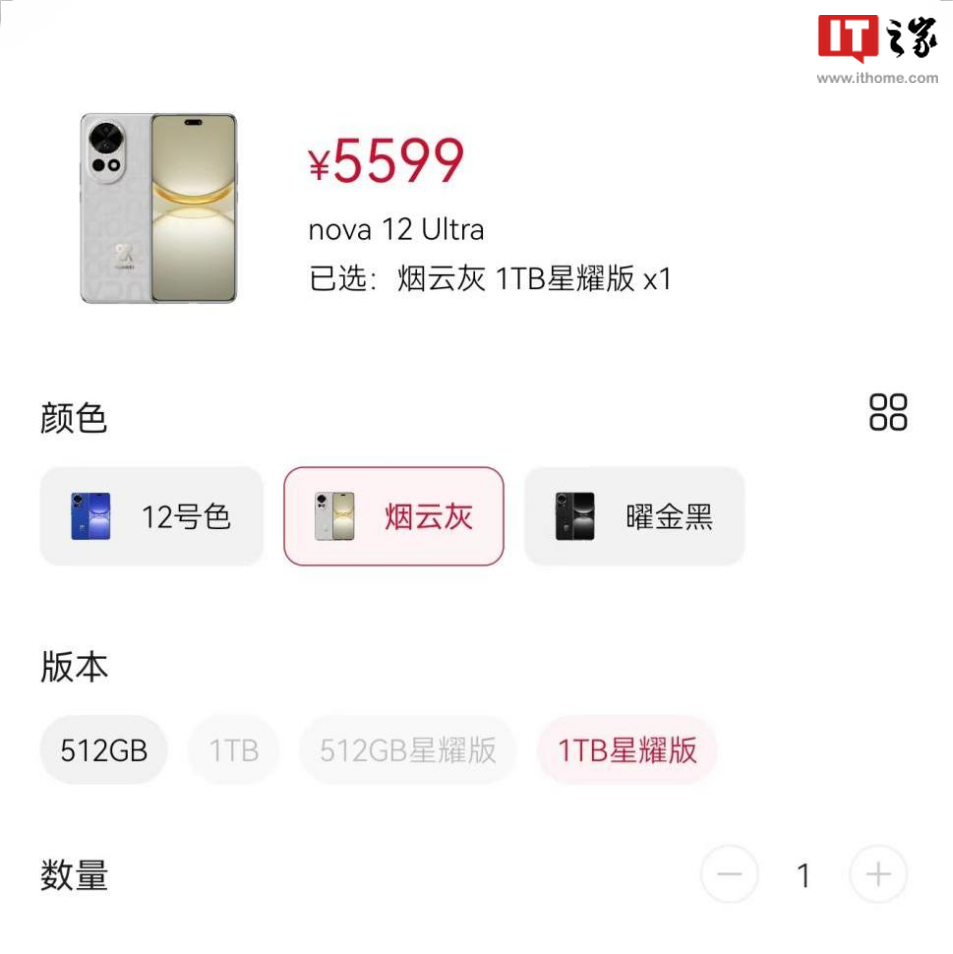
285 查看详情  华为 nova12 Ultra 星耀版存储版本售价信息512GB4799 元1 TB5599 元
华为 nova12 Ultra 星耀版存储版本售价信息512GB4799 元1 TB5599 元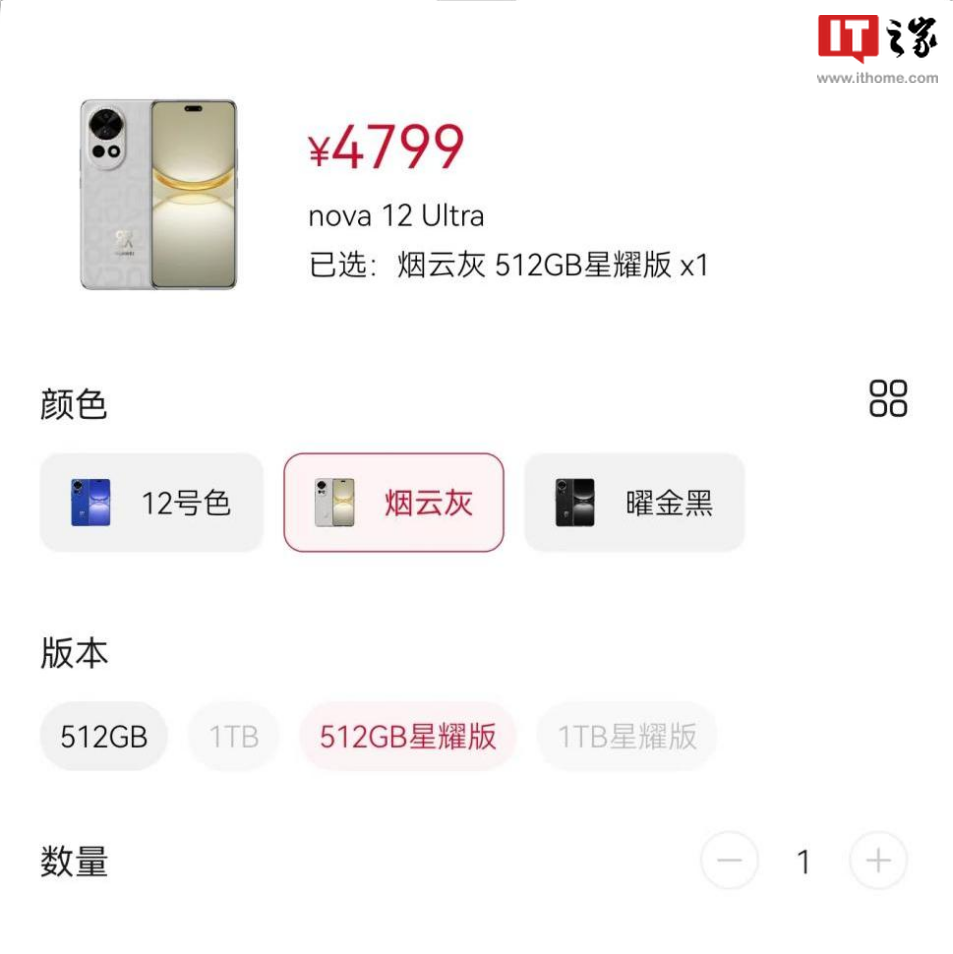
 注意到,华为 nova12 Ultra 星耀版拥有三种配色,后盖印有 nova 系列标志性的字母图案。据博主 @看山的叔叔 爆料,华为 nova12 Ultra 星耀版手机整体外观、配置与原版 nova 12 Ultra 基本一致,仅在充电器和保护壳上有所区别。
注意到,华为 nova12 Ultra 星耀版拥有三种配色,后盖印有 nova 系列标志性的字母图案。据博主 @看山的叔叔 爆料,华为 nova12 Ultra 星耀版手机整体外观、配置与原版 nova 12 Ultra 基本一致,仅在充电器和保护壳上有所区别。 华为 nova 12 Ultra 支持双向北斗卫星消息,配备 6.78 英寸 2776×1224 OLED 双挖孔等深四曲屏,支持 120Hz 刷新率、300Hz 触控采样率、2160Hz 高频 PWM 调光,配备第二代昆仑玻璃盖板。该机支持隔空手势和智感支付,采用麒麟 9000SL 处理器。
华为 nova 12 Ultra 支持双向北斗卫星消息,配备 6.78 英寸 2776×1224 OLED 双挖孔等深四曲屏,支持 120Hz 刷新率、300Hz 触控采样率、2160Hz 高频 PWM 调光,配备第二代昆仑玻璃盖板。该机支持隔空手势和智感支付,采用麒麟 9000SL 处理器。
以上就是4799 元起,华为 nova12 Ultra 星耀版手机售价公布的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1065273.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















