在进行网站搭建时,整站下载%ign%ignore_a_1%re_a_1%具有很高的实用性,尤其适用于模仿企业官网或批量采集某站点的所有图片资源。如果依靠手动方式一张张下载,工作量极为庞大,特别是面对成千上万张图片时,不仅耗时费力,甚至可能一整天都无法完成任务。而借助整站下载器,仅需几分钟即可将目标网站完整保存至本地,显著提升工作效率。不过,不少新手用户对这类工具的使用方法尚不熟悉。下面将逐步讲解整站下载器的操作流程,帮助用户快速上手,轻松实现对网站内容的全面抓取与本地存储,让获取网页资源变得更加高效便捷。
1、 打开整站下载软件后,主操作界面会自动显示,如图所示。
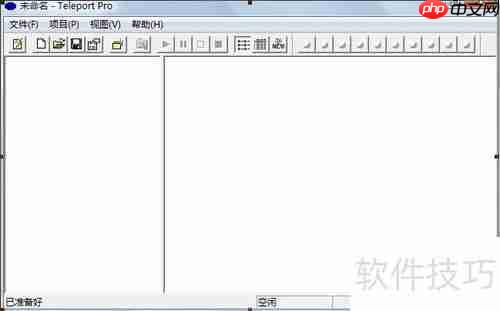
2、 点击菜单栏中的“项目”选项,选择“添加开始网址”,此时会弹出配置窗口,用于输入需要抓取的网站地址,界面如下图所示。
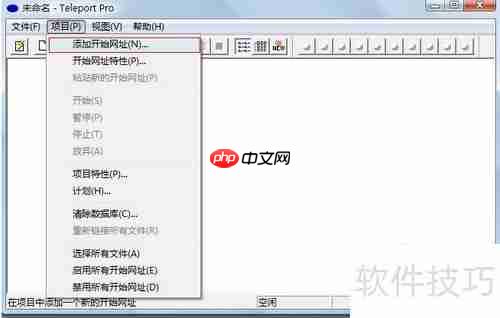
3、 在地址输入框中填入目标网站的完整URL,并将“搜索页面最多到”设置为一个较大的数值(例如10),以便工具能够深入抓取多层级页面内容,其他参数可保持默认设置。
4、 点击工具栏上的“项目特性”快捷按钮,打开项目属性设置窗口。切换至“取回文件”选项卡,勾选“仅下载以下指定类型和大小的文件”选项,然后点击其右侧的“添加”按钮。在弹出的类型选择对话框中,选择“图片”相关类别,即可实现只下载网站内的图片资源。通过相同方式,也可添加其他所需文件格式,满足个性化下载需求。具体操作可参考下图。
 某地板超炫企业网站1.1
某地板超炫企业网站1.1
1、演示:以截图为准 2、程序说明 程序试用后台:http://你的域名/admin/login.asp 后台登陆帐号:admin 密码:admin123 说明: 这个是基于asp+access的企业网站源码,数据库已设有有防下载,网站更安全 要修改网站,自定义你自己要的页面,和美化页面都是你自己完成,网站源码程序完整,后台功能强大。 调试运行环境:要安装IIS服务器(IIS的安装和配置,安装好
 0 查看详情
0 查看详情 

5、 点击主界面的“开始”按钮,系统将提示选择保存路径。选择合适的本地文件夹并确认后,下载任务即刻启动并自动执行。

6、 通过上述简单步骤,便可高效完成整个网站的下载工作,操作便捷,功能强大,极大简化了网页资源的采集过程。
以上就是正确使用网站整站下载器的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1068831.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫