
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 绘蛙AI视频
绘蛙AI视频
绘蛙推出的AI模特视频生成%ignore_a_1%
 82 查看详情
82 查看详情 
omniavatar是一款由浙江大学和阿里巴巴集团联合研发的音频驱动全身视频生成模型。该模型能够根据输入的音频和文本提示,生成逼真且自然的全身动画视频,人物动作与音频高度同步,表情生动多样。omniavatar采用像素级多级音频嵌入策略和lora训练方法,显著提升了唇部同步精度和全身动作的自然度,同时支持人物与物体交互、背景控制以及情绪调节等功能,适用于播客、互动视频、虚拟场景等多种应用场景。
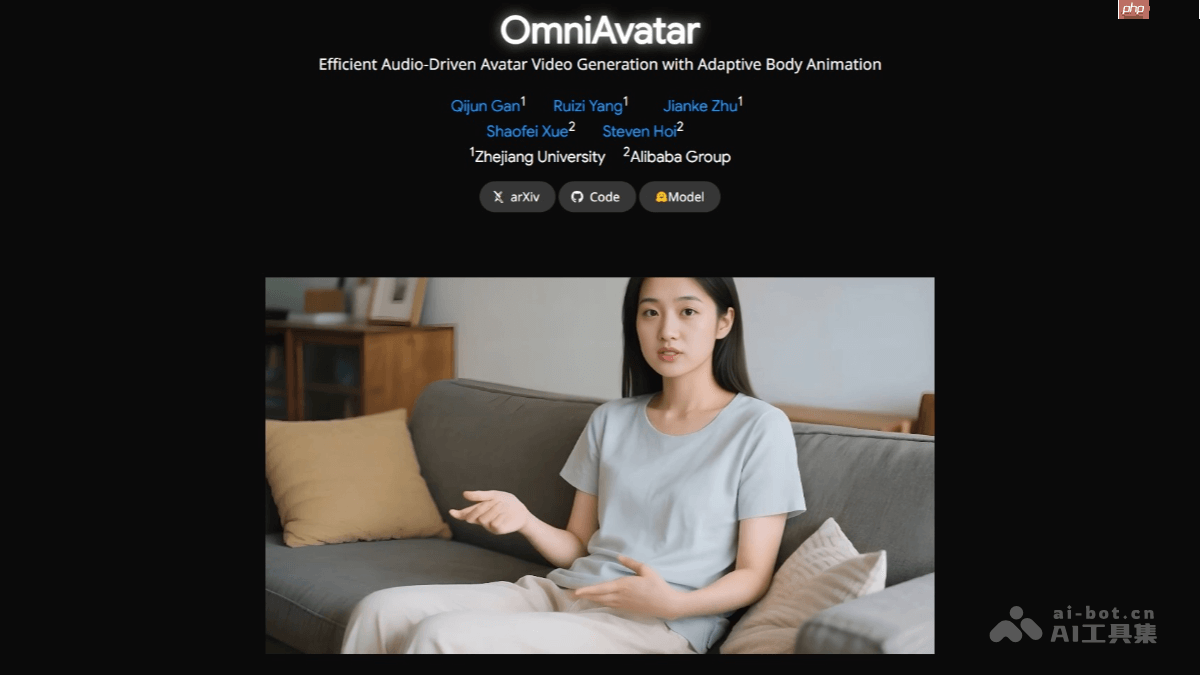 OmniAvatar的核心功能
OmniAvatar的核心功能
自然唇部同步:实现音频与唇部动作的高度同步,在复杂环境下也能保持精准表现。全身动画生成:可生成流畅自然的全身动作,使人物形象更具真实感。文本控制能力:通过文本提示对视频内容进行精细控制,涵盖人物动作、背景设置、情绪变化等,满足个性化生成需求。人与物体交互:支持人物与环境中物体的互动,如抓取物品、操作设备等,拓宽了使用场景。背景可控性:可根据文本描述更换背景,适应多样化的场景需求。情绪表达控制:通过文本指令控制人物的情绪状态,例如喜悦、悲伤、愤怒等,增强视频的表现力与感染力。
OmniAvatar的技术机制
像素级多级音频嵌入技术:将音频特征深入映射到潜在空间,并在像素层面嵌入,使音频更自然地影响全身动作生成,从而提升唇部同步精度和动作自然度。LoRA微调方法:采用低秩适应(LoRA)技术对预训练模型进行高效微调,通过引入低秩矩阵减少参数量,既保留原有模型能力,又提高训练效率和生成质量。长视频生成方案:为实现长时间视频的连贯生成,OmniAvatar采用参考图像嵌入与帧重叠策略,确保人物身份一致性和时间连续性,避免画面突变。扩散模型基础架构:基于扩散模型构建视频生成框架,通过逐步去噪生成高质量视频内容,尤其擅长处理长序列数据。Transformer结构融合:在扩散模型基础上集成Transformer架构,以更好地捕捉视频中的长期依赖关系和语义一致性,进一步提升视频质量和连贯性。
OmniAvatar的相关资源
官方网站:https://www.php.cn/link/45967c732254e9fc1e4ecb653b5f38cbGitHub代码库:https://www.php.cn/link/ecacd215c0e820d5407b32369cd33b9bHuggingFace模型页面:https://www.php.cn/link/2bc16f61719c604450e92d898ed19585论文链接(arXiv):https://www.php.cn/link/572df10598320f1d4b3b5944e22bebe7
OmniAvatar的应用领域
虚拟内容创作:可用于制作播客、虚拟博主等内容,降低人力成本,丰富视觉呈现方式。社交互动平台:在虚拟社交场景中提供个性化的虚拟角色,实现自然的表情与动作交流。教育与培训:创建虚拟教师或讲师形象,依据语音讲解教学内容,提升学习趣味性与参与度。广告与营销:打造定制化虚拟代言人,根据品牌需求设定形象与行为,实现高效传播。游戏与虚拟现实:快速生成具有自然动作与表情的角色,丰富游戏内容,增强沉浸式体验的真实感。
以上就是OmniAvatar— 浙大联合阿里推出的音频驱动全身视频生成模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/108896.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















