
mtvcrafter 是由中国科学院深圳先进技术研究院计算机视觉与模式识别实验室、中国电信人工智能研究所等多个研究机构共同开发的一款创新的人体图像动画框架,专注于从原始3d运动序列生成高质量动画。该框架通过引入4d运动标记化(4dmot)技术,直接对3d运动数据进行建模,从而绕过了传统方法中依赖2d渲染姿态图像的限制。此外,mtvcrafter 还采用了运动感知视频扩散transformer(mv-dit),利用独特的4d运动注意力机制和位置编码,以4d运动标记作为动画生成的上下文信息。在 tiktok 基准测试中,mtvcrafter 的 fid-vid 得分为6.98,较第二名提升了65%,显示了其卓越的泛化性能和稳定性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
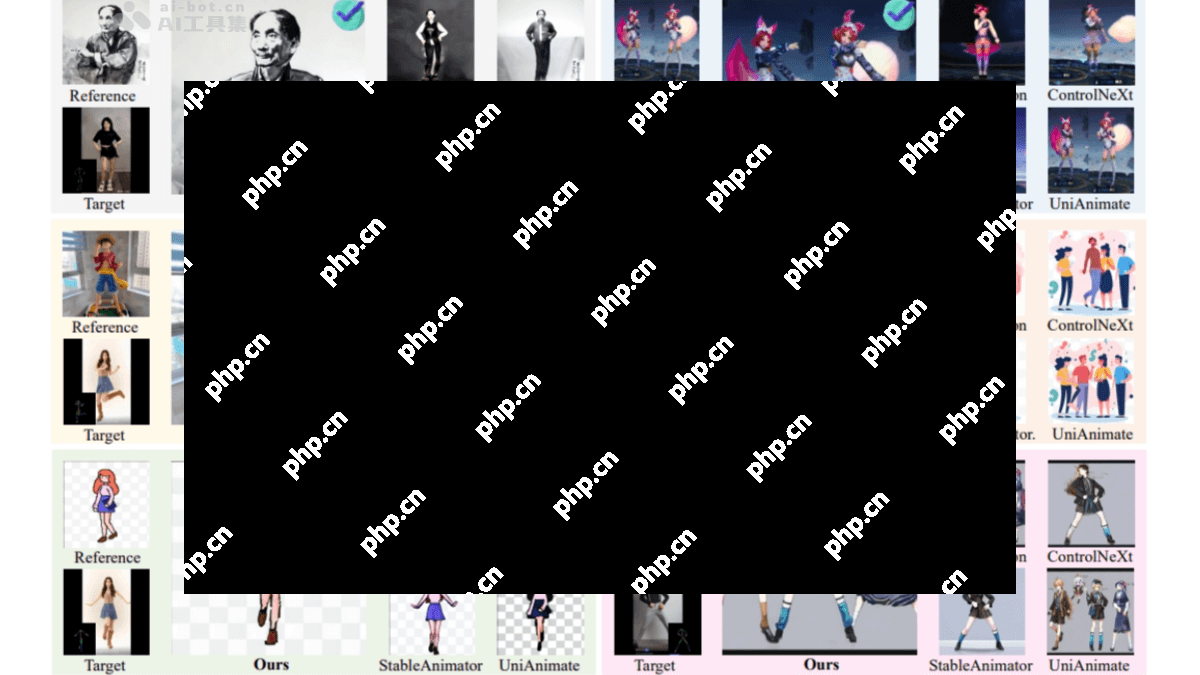
MTVCrafter 的核心功能
高质量动画生成:能够直接处理3D运动序列,生成高度逼真、流畅且自然的人体动画视频。广泛的泛化能力:不仅限于已知运动类型,还能适应全新的运动场景及不同角色设定,包括单人与多人、全身与局部动画,并兼容多种艺术风格(如卡通、像素风、水墨画以及写实风格)。精准的运动调控:借助4D运动标记化与运动注意力机制,确保每一帧动画都符合预期,保持动作连贯性和准确性。身份特征保留:在生成过程中始终保持源图像的身份特性,防止出现身份漂移或失真现象。
技术实现细节
4D运动标记化器(4DMoT):采用编码器-解码器架构,结合2D卷积神经网络和残差模块来捕捉时间和空间上的变化,同时运用向量量化器将连续运动特征转换成离散化的标记形式,这些标记统一存储以便后续使用。运动感知视频扩散Transformer(MV-DiT):构建了一种专门针对4D运动数据设计的注意力模型,它能将运动标记与视觉元素相结合,通过4D旋转位置编码恢复丢失的空间时间关联。此外,还引入了分类器自由引导策略,结合无条件和有条件生成的学习结果,进一步优化输出质量并扩大适用范围。最后,采用简单的重复拼接方法整合参考图片与噪声视频潜在变量,保证最终成品的身份一致性。
获取途径
GitHub链接:https://www.php.cn/link/dfead17f4721422bc9e1eaf97556b4a0学术论文链接:https://www.php.cn/link/4eed5c7364331eec1dff54ecd7811999
实际应用领域
虚拟人物创建:可用于打造虚拟主持人、客户服务代表或者明星偶像等数字形象。虚拟试衣间:结合顾客的真实照片与服饰设计,提供动态试穿体验,改善线上购物感受。增强现实体验:为VR/AR平台生成与用户互动相符的虚拟角色动画,营造更真实的交互环境。电影后期制作:加速高品质角色动画生产流程,减少成本投入,提高视觉效果。社交平台创意工具:允许用户将自己的头像融入到各种动作片段中,激发更多有趣的内容创作灵感。
以上就是MTVCrafter— 中科院联合中国电信等机构推出的人像动画生成框架的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/127051.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























