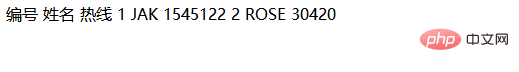本文旨在提供一种使用正则表达式(Regex)统计字符串中,特定单词在另一个特定单词出现后的次数的方法。通过结合 preg_match 和 preg_match_all 函数,可以有效地定位目标单词并统计其出现次数,避免了不必要的匹配,确保结果的准确性。本文将提供详细的代码示例和解释,帮助读者理解和应用该技术。
在处理文本数据时,经常需要统计特定模式的出现次数。一个常见的需求是统计某个单词在另一个单词出现后的次数。例如,在一个HTML文档中,统计hello在world之后出现的次数。以下提供一种基于PHP的解决方案,使用正则表达式实现此功能。
核心思路
定位起始单词: 使用 preg_match 函数找到起始单词(例如 world)及其之后的所有内容。统计目标单词: 在找到的起始单词之后的内容中,使用 preg_match_all 函数统计目标单词(例如 hello)的出现次数。
代码示例
代码解释
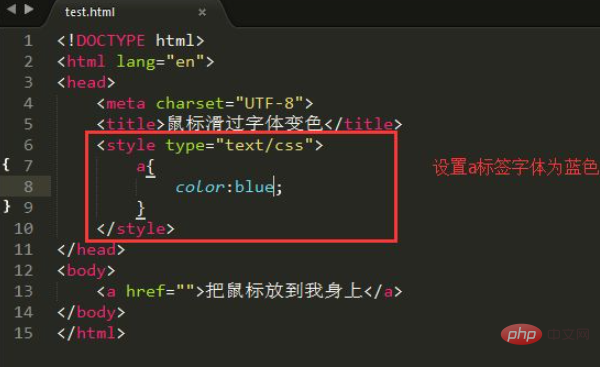
$str: 包含需要分析的文本字符串。preg_match(‘/”world”.*/s’, $str, $out): 使用 preg_match 函数查找字符串中第一次出现”world”的位置。/”world”.*/s: 这是一个正则表达式。”world”: 匹配字面字符串 “world”。.*: 匹配任何字符(除了换行符)零次或多次。/s: s 修饰符使点(.)也能匹配换行符。$out: 一个数组,用于存储匹配的结果。 $out[0] 包含匹配到的完整字符串。preg_match_all(‘/bhellob/’, $out[0]): 使用 preg_match_all 函数在 $out[0] 中统计 “hello” 出现的次数。/bhellob/: 这是一个正则表达式。b: 匹配单词边界,确保只匹配完整的单词 “hello”,而不是 “hello” 作为另一个单词的一部分。hello: 匹配字面字符串 “hello”。echo preg_match_all(‘/bhellob/’, $out[0]): 输出匹配到的次数。
注意事项
正则表达式的灵活性非常高,可以根据实际需求进行调整。例如,如果 world 周围的引号不是固定的,可以将正则表达式修改为 /world.*/s。b 单词边界在处理英文单词时非常有用,可以避免匹配到 helloworld 这样的字符串。如果需要匹配中文词语,可能需要使用其他方式来定义单词边界。/s 修饰符非常重要,它可以让 . 匹配换行符,从而确保可以跨越多行进行匹配。确保理解正则表达式的含义,避免出现意外的匹配结果。可以使用在线正则表达式测试工具(例如 https://www.php.cn/link/d76803aaf883a0a289d3b4075901d298)来测试正则表达式的正确性。
总结
本文介绍了一种使用正则表达式在PHP中统计特定单词在另一个特定单词之后出现的次数的方法。通过结合 preg_match 和 preg_match_all 函数,可以有效地解决这类问题。在实际应用中,可以根据具体需求调整正则表达式,以适应不同的文本数据。掌握这种方法可以帮助开发者更有效地处理文本数据,提取有用的信息。
以上就是统计特定单词在另一个特定单词出现后的次数的详细内容,更多请关注php中文网其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1274167.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫