
微软近日推出了一款名为“rstar2-agent”的开源模型,这是一个拥有140亿参数的数学推理模型,凭借更智能而非冗长的思维过程,实现了与6710亿参数的deepseek-r1模型相媲美的性能表现。
该模型具备自主规划、逻辑推理以及调用代码工具的能力,能够高效地探索、验证并反思复杂问题的解决方案。其卓越能力源于三大关键技术突破:GRPO-RoC算法、可扩展且高效的强化学习(RL)基础设施,以及从非推理SFT起步的渐进式Agent训练策略。
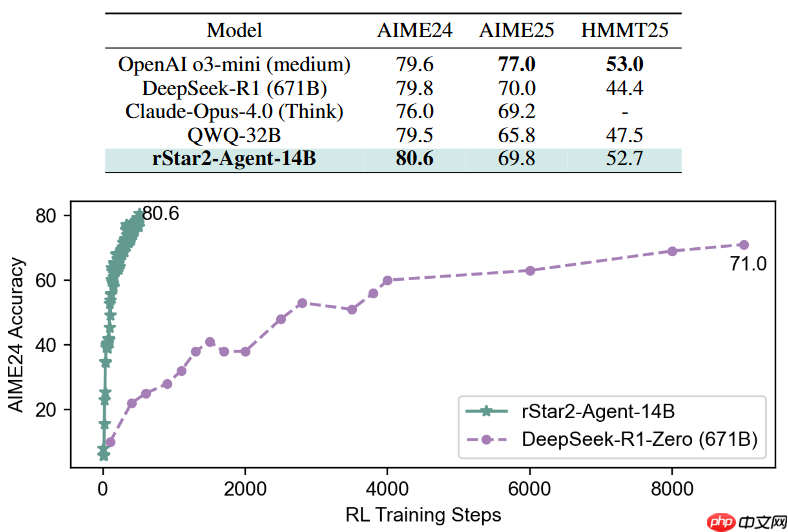
rStar2-Agent的核心理念是“更聪明地思考”,而非延长推理链长度。通过纯智能体式的强化学习训练,其在多项任务上的表现已接近甚至超越超大规模模型,如671B参数的DeepSeek-R1。
该模型能够自主进行任务规划、逻辑推导,并灵活运用编程工具,从而高效完成对复杂问题的求解、验证与自我修正。
GRPO-RoC算法:引入创新的“正确时重采样”推理机制,优化了对编码工具的使用效率。该方法选择性保留高质量的成功推理路径,同时完整保留失败案例用于学习,从而实现更短但更高效的推理过程;高效可扩展的RL基础设施:支持高吞吐量的工具调用执行,显著降低智能体在强化学习推演中的资源消耗,使得仅用64块MI300X GPU即可完成大规模训练;渐进式Agent训练方案:起始于非推理型SFT模型,通过多阶段强化学习逐步提升能力。每一阶段均采用受限的最大响应长度,并逐步提高训练数据的难度,确保稳定收敛。
基于上述技术,rStar2-Agent仅用一周时间、经过510步的强化学习训练,就将一个14B参数的预训练模型提升至行业领先水平。在AIME24和AIME25两个权威数学评测集上,分别取得了80.6%和69.8%的平均通过率,响应更简洁却超越了参数量高达6710亿的DeepSeek-R1。
此外,rStar2-Agent-14B在数学之外的任务中也展现出出色的泛化能力,包括指令对齐、科学推理以及智能体工具调用等多样化场景。
开源地址:https://www.php.cn/link/b1946b34ce976b3f223d5afc2052e89d
以上就是微软发布开源数学推理模型 rStar2-Agent的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/130301.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























