clickh%ignore_a_1%use与elasticsearch、hdfs等采用主从架构的分布式系统不同,它采用的是多主(无中心)架构。集群中的每个节点角色相同,客户端可通过任意节点访问并获得一致的结果。
ClickHouse通过分片技术进行数据的横向分割,分片依赖于集群,每个集群包含1到多个分片,每个分片对应ClickHouse的一个服务节点。分片数量的上限受节点数量的限制(一个分片只能对应一个服务节点)。
然而,ClickHouse与其他分布式系统不同,它没有高度自动化的分片功能。ClickHouse引入了本地表和分布式表的概念;本地表相当于一个数据分片。分布式表则是一张逻辑表,不存储数据,充当本地表的访问代理,类似于分库中间件。通过分布式表,可以代理访问多个数据分片,从而实现分布式查询。当然,数据分发也可以在应用层实现。
ClickHouse同样支持数据副本,其副本概念与Elasticsearch类似,但在ClickHouse中,分片是逻辑概念,物理上由副本承载。
ClickHouse的数据副本通常通过ReplicatedMergeTree系列复制表引擎实现,副本间通过ZooKeeper实现数据一致性。此外,分布式表可以同时负责分片和副本的数据写入。
以四节点实现多分片和双副本为例:
方案一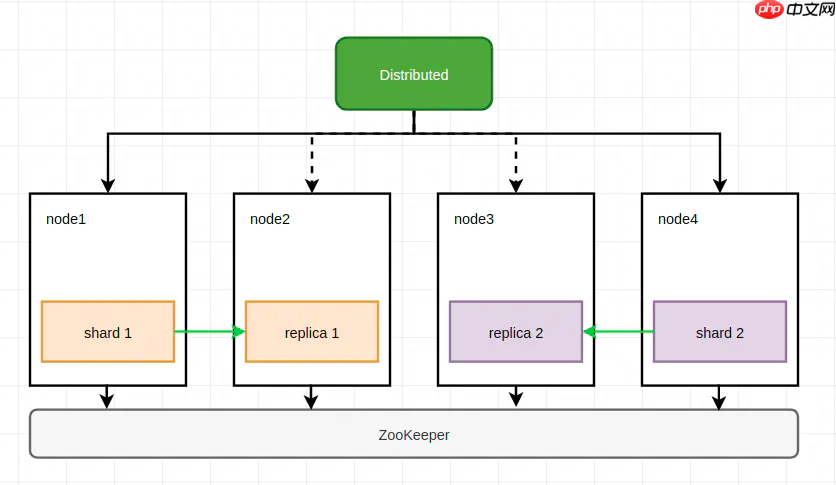 (上图中shard作为主副本)在每个节点上创建一个数据表,作为一个数据分片,使用ReplicatedMergeTree表引擎实现数据副本,而分布表作为数据写入和查询的入口。这是最常见的集群实现方式。
(上图中shard作为主副本)在每个节点上创建一个数据表,作为一个数据分片,使用ReplicatedMergeTree表引擎实现数据副本,而分布表作为数据写入和查询的入口。这是最常见的集群实现方式。
方案二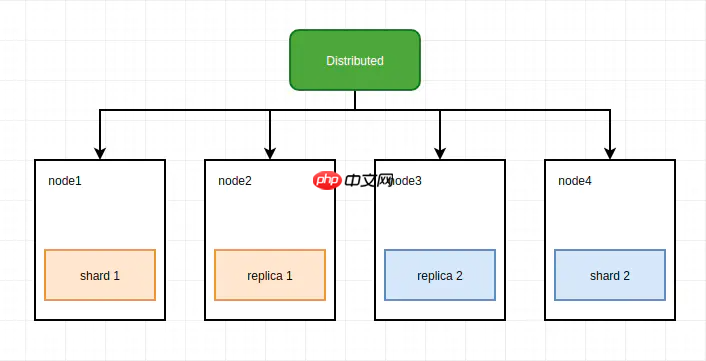 在每个节点上创建一个数据表,作为一个数据分片,分布表同时负责分片和副本的数据写入工作。
在每个节点上创建一个数据表,作为一个数据分片,分布表同时负责分片和副本的数据写入工作。
这种实现方案下,不需要使用复制表,但分布表节点需要同时负责分片和副本的数据写入工作,可能成为写入的单点瓶颈。
方案三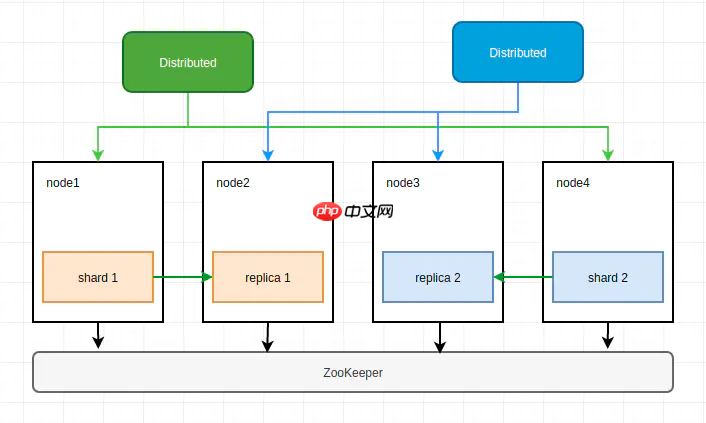 在每个节点上创建一个数据表,作为一个数据分片,同时创建两个分布表,每个分布表只管理一半的数据。
在每个节点上创建一个数据表,作为一个数据分片,同时创建两个分布表,每个分布表只管理一半的数据。
副本的实现仍需借助ReplicatedMergeTree类表引擎。
方案四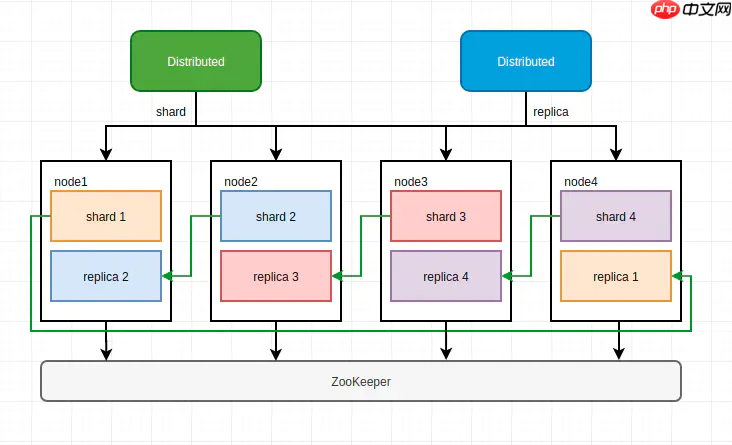 在每个节点上创建两个数据表,同一数据分片的两个副本位于不同节点上,每个分布式表管理一般的数据。
在每个节点上创建两个数据表,同一数据分片的两个副本位于不同节点上,每个分布式表管理一般的数据。
这种方案可以在较少的节点上实现数据分布与冗余,但部署上略显复杂。
ClickHouse的分片与副本功能完全依赖配置文件实现,无法自动管理,因此在集群规模较大时,运维成本较高。数据副本依赖ZooKeeper实现同步,当数据量较大时,ZooKeeper可能会成为瓶颈。如果资源充足,建议使用方案一,主副本和副副本位于不同节点,以更好地实现读写分离与负载均衡。如果资源不足,可以使用方案四,每个节点承载两个副本,但部署方式上略复杂。
原文链接?:https://www.jianshu.com/p/f1fa7e5cb67f
以上就是常见ClickHouse集群部署架构的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/13061.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫