
PHP中使用正则表达式主要依赖PCRE库和preg_系列函数,通过定界符、修饰符和元字符实现字符串的匹配、查找、替换与分割,结合捕获组、非捕获组及反向引用可高效提取和处理数据,处理多字节字符时需添加u修饰符以支持UTF-8编码。

PHP中使用正则表达式,主要是通过内置的
preg_
系列函数来实现文本模式的匹配、查找、替换、分割等操作。它的核心在于掌握正则表达式本身的语法规则,以及如何将这些规则应用到PHP的函数中,从而实现对复杂字符串的灵活处理。
解决方案
在PHP中,处理正则表达式主要依赖于PCRE(Perl Compatible Regular Expressions)库,并通过一系列以
preg_
开头的函数来调用。我个人在处理字符串时,尤其是一些复杂的日志分析、数据清洗或者表单验证,
preg_match
和
preg_replace
几乎是我的首选,它们提供了一种远超
str_replace
或
substr
的强大模式匹配能力。
首先,你需要定义一个正则表达式模式。这个模式通常由定界符包围,例如
/pattern/
。
1. 匹配与查找:
preg_match()
和
preg_match_all()
立即学习“PHP免费学习笔记(深入)”;
preg_match(string $pattern, string $subject, array &$matches = null, int $flags = 0, int $offset = 0)
: 用于执行一个正则表达式匹配。如果找到匹配项,它返回
1
;未找到则返回
0
;发生错误则返回
false
。
$matches
数组会存储所有捕获到的匹配项。
$text = "我的电话是 138-1234-5678,她的电话是 139-8765-4321。";$pattern = '/(d{3}-d{4}-d{4})/'; // 匹配电话号码if (preg_match($pattern, $text, $matches)) { echo "找到第一个电话号码: " . $matches[1] . "n"; // $matches[0] 包含完整匹配的字符串 // $matches[1] 包含第一个捕获组的内容}
preg_match_all(string $pattern, string $subject, array &$matches, int $flags = PREG_PATTERN_ORDER, int $offset = 0)
: 用于在字符串中查找所有匹配项。它返回找到的完整匹配(或其子模式)的次数。
$text = "我的电话是 138-1234-5678,她的电话是 139-8765-4321。";$pattern = '/(d{3}-d{4}-d{4})/';preg_match_all($pattern, $text, $allMatches);echo "所有电话号码:n";foreach ($allMatches[1] as $phone) { echo $phone . "n";}// $allMatches[0] 是所有完整匹配的数组// $allMatches[1] 是所有第一个捕获组的数组
2. 替换:
preg_replace()
preg_replace(string|array $pattern, string|array $replacement, string|array $subject, int $limit = -1, int &$count = null)
: 执行正则表达式的搜索和替换。这是我最常用到的功能之一,比如清理用户输入、格式化文本等。
$text = "Hello, World! This is a test string.";$pattern = '/(World|test)/';$replacement = 'PHP';$newText = preg_replace($pattern, $replacement, $text);echo "替换后的文本: " . $newText . "n"; // 输出: Hello, PHP! This is a PHP string.// 结合反向引用$name = "Doe, John";$pattern = '/(w+), (w+)/'; // 匹配 "姓, 名"$replacement = '$2 $1'; // 替换成 "名 姓"$formattedName = preg_replace($pattern, $replacement, $name);echo "格式化后的名字: " . $formattedName . "n"; // 输出: John Doe
3. 分割:
preg_split()
preg_split(string $pattern, string $subject, int $limit = -1, int $flags = 0)
: 通过正则表达式将字符串分割成数组。
$csvLine = "apple,banana , orange;grape";$pattern = '/[,;]s*/'; // 匹配逗号或分号,后面跟着零个或多个空格$fruits = preg_split($pattern, $csvLine);print_r($fruits);/*Array( [0] => apple [1] => banana [2] => orange [3] => grape)*/
这些函数构成了PHP正则表达式使用的核心,理解它们如何与正则表达式语法结合,是高效处理字符串的关键。
PHP正则表达式的定界符、修饰符与常用元字符解析:避坑指南
在使用PHP正则表达式时,理解定界符、修饰符(也叫模式修正符)和各种元字符是基础,也是我个人在初期学习时常犯错的地方。
定界符 (Delimiters)正则表达式模式必须被定界符包围。最常见的是斜杠
/
,但你也可以选择其他字符,比如
#
、
~
、
!
等,只要它不出现在你的模式内部。
为什么需要定界符? 它告诉PHP哪里是模式的开始,哪里是模式的结束,以及模式后面可能跟的修饰符。
避坑点: 如果你的模式本身包含定界符,比如你要匹配URL路径中的斜杠
/
,那么最好换一个定界符,比如
#
。否则,你就需要对模式中的斜杠进行转义(
/
),这会增加模式的复杂性和可读性。我刚开始学的时候,老是忘记这个,导致一堆报错或者匹配失败。
// 匹配 /path/to/resource// 错误示范(需要转义,但容易混淆):// $pattern = '//path/to/resource/';// 推荐做法(更换定界符):$pattern = '#/path/to/resource#';// 或者$pattern = '~^/user/(d+)/profile$~'; // 匹配 /user/123/profile
修饰符 (Modifiers/Flags)这些是紧跟在模式定界符后面的单个字母,用于改变匹配行为。
i
(PCRE_CASELESS): 忽略大小写。
preg_match('/php/i', 'PHP is great', $matches); // 匹配成功
s
(PCRE_DOTALL): 使
.
(点号)元字符匹配任何字符,包括换行符。默认情况下,
.
不匹配换行符。
$text = "Line 1nLine 2";preg_match('/Line.Line/s', $text, $matches); // 匹配成功
m
(PCRE_MULTILINE): 多行模式。使
^
和
$
元字符匹配行的开头和结尾,而不仅仅是字符串的开头和结尾。
$text = "Line 1nLine 2";preg_match_all('/^Line/m', $text, $matches); // 匹配两行
U
(PCRE_UNGREEDY): 使量词变为非贪婪模式。默认情况下,量词是贪婪的,会尽可能多地匹配。
$html = "TextMore Text";// 贪婪模式 (默认): 匹配整个...preg_match('/.*/', $html, $matches);echo $matches[0] . "n"; // 输出:TextMore Text// 非贪婪模式: 只匹配第一个...preg_match('/.*?/U', $html, $matches); // 或者直接用 `.*?`echo $matches[0] . "n"; // 输出:TextMore Text
U(PCRE_UTF8): 处理UTF-8编码的字符串。这是处理多字节字符(如中文、表情符号)时非常重要的修饰符,我会在后面的章节详细说明。
常用元字符 (Metacharacters)这些特殊字符赋予正则表达式强大的匹配能力。
.: 匹配除换行符以外的任何单个字符(除非使用
s修饰符)。*``**: 匹配前一个字符零次或多次。
+: 匹配前一个字符一次或多次。
?: 匹配前一个字符零次或一次(使其可选)。
{n}: 匹配前一个字符恰好
n次。
{n,}: 匹配前一个字符至少
n次。
{n,m}: 匹配前一个字符
n到
m次。
[]: 字符集合。匹配方括号中的任何一个字符。
[abc]匹配 ‘a’, ‘b’, 或 ‘c’。
[0-9]匹配任何数字。
[a-zA-Z]匹配任何英文字母。
[^]: 否定字符集合。匹配方括号中列出的字符以外的任何字符。
[^0-9]匹配任何非数字字符。
(): 捕获组。将一部分模式组合在一起,并捕获匹配的内容。
|: 或。匹配
|左边或右边的模式。
cat|dog匹配 ‘cat’ 或 ‘dog’。
^: 匹配字符串的开头(或行的开头,如果使用
m修饰符)。
$: 匹配字符串的结尾(或行的结尾,如果使用
m修饰符)。
: 转义字符。用于转义元字符,使其作为普通字符匹配。例如,
.匹配点号本身,而不是任何字符。
d: 匹配任何数字字符(等同于
[0-9])。
d: 匹配任何非数字字符(等同于
[^0-9])。
w: 匹配任何字母、数字或下划线字符(等同于
[a-zA-Z0-9_])。
w: 匹配任何非字母、数字或下划线字符。
s: 匹配任何空白字符(空格、制表符、换行符等)。
s: 匹配任何非空白字符。
b: 单词边界。匹配一个单词的开始或结束。
b: 非单词边界。
理解并熟练运用这些元字符,是编写高效、准确正则表达式的关键。我记得有一次,在处理一个日志文件时,需要提取特定错误码,如果不是对
d+和
b这种组合运用得当,匹配结果就会非常混乱。
PHP正则表达式中的捕获组、非捕获组与反向引用:提取数据的利器
在实际开发中,我们不仅仅是想知道一个模式是否匹配,更重要的是从匹配的文本中提取出我们需要的数据。这时候,捕获组、非捕获组和反向引用就显得尤为重要。它们是正则表达式中非常强大的特性,我个人在处理复杂数据提取任务时,几乎离不开它们。
捕获组
()(Capturing Groups)使用圆括号
()将正则表达式的一部分括起来,就创建了一个捕获组。捕获组的作用有两个:
分组:将多个字符或模式视为一个整体,可以对其应用量词或进行逻辑操作。捕获:将匹配到的内容存储起来,以便后续使用(比如在
preg_match的
$matches数组中,或者在
preg_replace的替换字符串中)。
当你使用
preg_match或
preg_match_all时,
$matches数组的结构是这样的:
$matches[0]:包含整个正则表达式匹配到的完整字符串。
$matches[1]:包含第一个捕获组匹配到的内容。
$matches[2]:包含第二个捕获组匹配到的内容,以此类推。
示例:提取日期和时间假设我们有一个日志条目:”2023-10-27 14:35:01 – User login successful.”,我们想提取日期和时间。
$logEntry = "2023-10-27 14:35:01 - User login successful.";$pattern = '/^(d{4}-d{2}-d{2})s+(d{2}:d{2}:d{2})/'; // 两个捕获组,分别捕获日期和时间if (preg_match($pattern, $logEntry, $matches)) { echo "日期: " . $matches[1] . "n"; // 输出: 2023-10-27 echo "时间: " . $matches[2] . "n"; // 输出: 14:35:01}这里,
(d{4}-d{2}-d{2})是第一个捕获组,
(d{2}:d{2}:d{2})是第二个。
非捕获组
(?:...)(Non-Capturing Groups)有时候我们只是想将一部分模式组合起来,但又不需要捕获它的内容,这时就可以使用非捕获组
(?:...)。
作用: 仅仅是分组,不占用
$matches数组的索引,也不会增加捕获组的处理开销。这对于优化性能和保持
$matches数组结构简洁很有用。
示例:分组但不捕获假设我们要匹配 “cat” 或 “dog”,后面跟着 “food”,但我们只关心 “food” 前面的动物。
$text = "I like cat food and dog food.";$pattern = '/(?:cat|dog) food/'; // (?:cat|dog) 是非捕获组preg_match_all($pattern, $text, $matches);print_r($matches);/*Array( [0] => Array ( [0] => cat food [1] => dog food ))*/// 注意:$matches 中只有 $matches[0],没有 $matches[1] 来捕获 'cat' 或 'dog'。// 如果用捕获组,则会有 $matches[1]// $pattern_capture = '/(cat|dog) food/';// preg_match_all($pattern_capture, $text, $matches_capture);// print_r($matches_capture);/*Array( [0] => Array ( [0] => cat food [1] => dog food ) [1] => Array ( [0] => cat [1] => dog ))*/可以看到,使用非捕获组后,
$matches数组中就只剩下完整的匹配项了。
反向引用
n或
$n(Backreferences)反向引用允许你在正则表达式的模式中或者替换字符串中引用前面捕获组匹配到的内容。
在模式中引用:使用
1,
2, … 来引用前面第N个捕获组匹配到的内容。在替换字符串中引用:使用
$1,
$2, … 来引用前面第N个捕获组匹配到的内容。
示例:模式中的反向引用匹配重复的单词,比如 “hello hello”。
$text = "This is a test test string with repeated words.";$pattern = '/b(w+)s+1b/i'; // 1 引用第一个捕获组 (w+) 的内容if (preg_match($pattern, $text, $matches)) { echo "找到重复单词: " . $matches[1] . "n"; // 输出: test}这里
1确保了第二个单词和第一个捕获组匹配到的单词完全相同。
示例:替换字符串中的反向引用我记得有一次需要把
firstname lastname格式的名字换成
lastname, firstname,反向引用简直是神来之笔。
$name = "John Doe";$pattern = '/(w+)s+(w+)/'; // 第一个捕获组是名,第二个是姓$replacement = '$2, $1'; // 使用 $2 (姓) 和 $1 (名) 进行替换$formattedName = preg_replace($pattern, $replacement, $name);echo "格式化后的名字: " . $formattedName . "n"; // 输出: Doe, John反向引用在数据格式转换、字符串重排等方面提供了极大的便利和灵活性。掌握这些概念,能让你在处理复杂文本数据时事半功倍。
PHP正则表达式处理多字节字符串与Unicode:编码问题与解决方案
在处理包含中文、日文、韩文或其他Unicode字符的字符串时,PHP的正则表达式如果不加注意,很容易遇到编码问题。我曾经在一个处理用户评论的系统里,因为没加
U修饰符,导致一些包含表情符号或者特殊字符的文本匹配出错,排查了很久才发现是编码问题。
编码问题背景PHP的
preg_系列函数底层依赖PCRE库。默认情况下,PCRE库是按照字节(byte)来处理字符串的。对于单字节编码(如ASCII或ISO-8859-1),这通常不是问题。然而,对于UTF-8等多字节编码,一个字符可能由多个字节组成。
问题1:
.(点号)元字符:在默认模式下,
.会匹配任何一个字节,而不是一个完整的Unicode字符。这意味着一个中文字符(通常占3
以上就是PHP正则表达式怎么用_正则表达式匹配详细教程的详细内容,更多请关注php中文网其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1320846.html赞 (0)打赏微信扫一扫
支付宝扫一扫
关于作者


相关推荐
-
学会从头开始学习CSS,掌握制作基本网页框架的技巧
从零开始学习CSS,掌握网页基本框架制作技巧 前言: 在现今互联网时代,网页设计和开发是一个非常重要的技能。而学习CSS(层叠样式表)是掌握网页设计的关键之一。CSS不仅可以为网页添加样式和布局,还可以为用户呈现独特且具有吸引力的页面效果。在本文中,我将为您介绍一些基本的CSS知识,以及一些常用的代…
-
揭秘Web标准涵盖的语言:了解网页开发必备的语言范围
在当今数字时代,互联网成为了人们生活中不可或缺的一部分。作为互联网的基本构成单位,网页承载着我们获取和分享信息的重要任务。而网页开发作为一门独特的技术,离不开一些必备的语言。本文将揭秘Web标准涵盖的语言,让我们一起了解网页开发所需的语言范围。 首先,HTML(HyperText Markup La…
-
揭开Web开发的语言之谜:了解构建网页所需的语言有哪些?
Web标准中的语言大揭秘:掌握网页开发所需的语言有哪些? 随着互联网的快速发展,网页开发已经成为人们重要的职业之一。而要成为一名优秀的网页开发者,掌握网页开发所需的语言是必不可少的。本文将为大家揭示Web标准中的语言大揭秘,介绍网页开发所需的主要语言。 HTML(超文本标记语言)HTML是网页开发的…
-
常用的网页开发语言:了解Web标准的要点
了解Web标准的语言要点:常见的哪些语言应用在网页开发中? 随着互联网的不断发展,网页已经成为人们获取信息和交流的重要途径。而要实现一个高质量、易用的网页,离不开一种被广泛接受的Web标准。Web标准的制定和应用,涉及到多种语言和技术,本文将介绍常见的几种语言在网页开发中的应用。 首先,HTML(H…
-
网页开发中常见的Web标准语言有哪些?
探索Web标准语言的世界:网页开发中常用的语言有哪些? 在现代社会中,互联网的普及程度越来越高,网页已成为人们获取资讯、娱乐、交流的重要途径。而网页的开发离不开各种编程语言的应用和支持。在这个虚拟世界的网络,有许多被广泛应用的标准化语言,用于为用户提供优质的网页体验。本文将探索网页开发中常用的语言,…
-
深入探究Web标准语言的范围,涵盖了哪些语言?
Web标准是指互联网上的各个网页所需遵循的一系列规范,确保网页在不同的浏览器和设备上能够正确地显示和运行。这些标准包括HTML、CSS和JavaScript等语言。本文将深入解析Web标准涵盖的语言范围。 首先,HTML(HyperText Markup Language)是构建网页的基础语言。它使…
-
CSS 超链接属性解析:text-decoration 和 color
CSS 超链接属性解析:text-decoration 和 color 超链接是网页中常用的元素之一,它能够在不同页面之间建立连接。为了使超链接在页面中有明显的标识和吸引力,CSS 提供了一些属性来调整超链接的样式。本文将重点介绍 text-decoration 和 color 这两个与超链接相关的…
-
看看这些前端面试题,带你搞定高频知识点(一)




每天10道题,100天后,搞定所有前端面试的高频知识点,加油!!!,在看文章的同时,希望不要直接看答案,先思考一下自己会不会,如果会,自己的答案是什么?想过之后再与答案比对,是不是会更好一点,当然如果你有比我更好的答案,欢迎评论区留言,一起探讨技术之美。 面试官:给定一个元素,如何实现水平垂直居中?…
-
看看这些前端面试题,带你搞定高频知识点(二)




每天10道题,100天后,搞定所有前端面试的高频知识点,加油!!!,在看文章的同时,希望不要直接看答案,先思考一下自己会不会,如果会,自己的答案是什么?想过之后再与答案比对,是不是会更好一点,当然如果你有比我更好的答案,欢迎评论区留言,一起探讨技术之美。 面试官:页面导入样式时,使用 link 和 …
-
看看这些前端面试题,带你搞定高频知识点(三)




每天10道题,100天后,搞定所有前端面试的高频知识点,加油!!!,在看文章的同时,希望不要直接看答案,先思考一下自己会不会,如果会,自己的答案是什么?想过之后再与答案比对,是不是会更好一点,当然如果你有比我更好的答案,欢迎评论区留言,一起探讨技术之美。 面试官:清除浮动有哪些方式? 我:呃~,浮动…
-
看看这些前端面试题,带你搞定高频知识点(四)




每天10道题,100天后,搞定所有前端面试的高频知识点,加油!!!,在看文章的同时,希望不要直接看答案,先思考一下自己会不会,如果会,自己的答案是什么?想过之后再与答案比对,是不是会更好一点,当然如果你有比我更好的答案,欢迎评论区留言,一起探讨技术之美。 面试官:请你谈一下自适应(适配)的方案 我:…
-
看看这些前端面试题,带你搞定高频知识点(五)




每天10道题,100天后,搞定所有前端面试的高频知识点,加油!!!,在看文章的同时,希望不要直接看答案,先思考一下自己会不会,如果会,自己的答案是什么?想过之后再与答案比对,是不是会更好一点,当然如果你有比我更好的答案,欢迎评论区留言,一起探讨技术之美。 面试官:css 如何实现左侧固定 300px…
-
HTML+CSS+JS实现雪花飘扬(代码分享)




使用html+css+js如何实现下雪特效?下面本篇文章给大家分享一个html+css+js实现雪花飘扬的示例,希望对大家有所帮助。 很多南方的小伙伴可能没怎么见过或者从来没见过下雪,今天我给大家带来一个小Demo,模拟了下雪场景,首先让我们看一下运行效果 可以点击看看在线运行:http://hai…
-
分享20个首页流行布局样式,总有一款适合你!




本篇文章给大家分享20个首页流行布局样式,总有一款适合你,快来收藏试试吧,希望对大家有所帮助! 有时我们会在网站上遇到一些内容布局问题,如文字对齐、图片设计与内容和谐、为文章选择合适的字体……在今天的文章中,介绍一些设计精美的创意布局,let‘s 开始。 代号 001 源码…
-
css如何让div悬浮于另一个div上

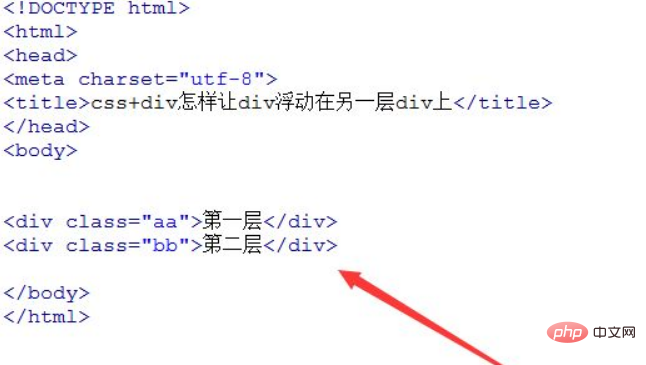
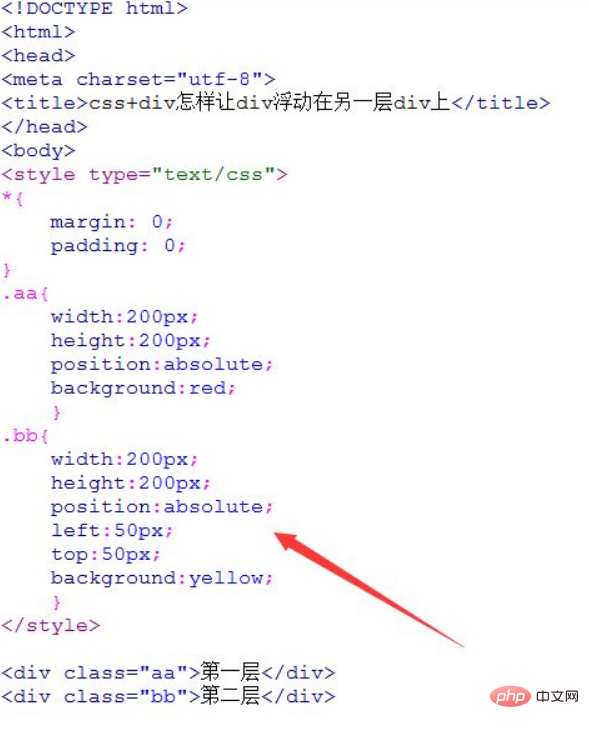

让div悬浮于另一个div上的方法:1、给两个div元素添加“position:absolute”绝对定位样式;2、给其中一个div元素添加“{top:距离页面顶部距离;left:距离页面左侧距离;}”样式使其浮动在另一个div元素上即可。 本教程操作环境:windows7系统、CSS3&&…
-
css怎样实现字母不到一行就换行
css字母不到一行就换行的方法:1、给元素添加“word-break:break-word;”样式,使其以单词为单位换行;2、给元素添加“word-break:break-all;”样式,使其以字母为单位换行。 本教程操作环境:windows7系统、CSS3&&HTML5版、Dell…
-
css里怎样设置字体大小和字体颜色
在css中,可以使用“font-size”和color属性设置字体大小和字体颜色,只需要给字体元素添加“{font-size: 字体大小值;color: 颜色值;}”样式即可。 本教程操作环境:windows7系统、CSS3&&HTML5版、Dell G3电脑。 css里设置字体大小…
-
css边框变圆角边框怎么写
写法:1、给边框添加“border-radius:圆角值;”样式统一设置圆角大小;2、添加“border-top-left-radius:圆角值;”、“border-top-right-radius:圆角值;”等样式分别设置四角圆角大小。 本教程操作环境:windows7系统、CSS3&&a…
-
css如何使鼠标悬停变色

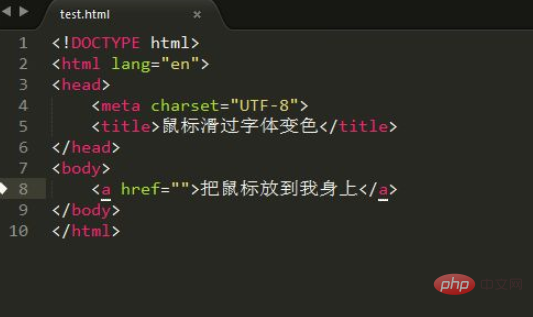
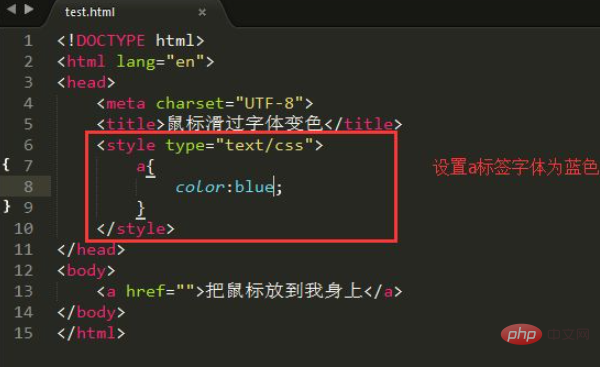
在css中,可以通过hover选择器和color属性实现鼠标悬停变色的效果,hover选择器用于选择鼠标指针浮动在上面的元素,color属性用于设置悬停时的颜色;语法“:hover{color:悬停颜色;}”。 本教程操作环境:windows7系统、CSS3&&HTML5版、Dell…
-
手把手教你使用css制作表格边框设置效果(附代码)


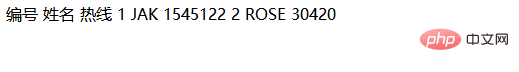

之前的文章《一招教你使用css3制作按钮添加动态效果(代码分享)》中,给大家介绍了怎么使用css3制作按钮添加动态效果。下面本篇文章给大家介绍怎么使用css制作表格边框设置效果,我们一起看看怎么做。 网页中常常有这样的表格布局边框,给大家分享一下看效果图看完效果,我们来研究一下是怎么实现呢,给大家用…











