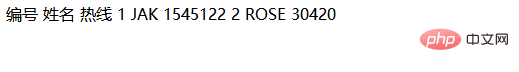本文探讨了在php中高效查找和修改html字符串内特定内容(如电话号码)的方法。它介绍了两种主要途径:一是将php的`preg_`系列函数与`domdocument`及xpath结合使用;二是更直接地利用`preg_match_all`和`preg_replace`配合正则表达式来提取或替换html标签间的文本。这些方案为html内容操作提供了不依赖xpath原生正则表达式功能的强大替代方案。
在处理HTML文档时,我们经常需要查找并修改特定的文本内容,例如从网页中提取或移除电话号码。虽然XPath是解析HTML和XML的强大工具,但其原生对正则表达式的支持有限。本文将介绍两种在PHP中实现HTML内容正则查找与替换的有效方案,作为XPath的补充或替代。
方案一:通过PHP函数扩展XPath
DOMDocument和DOMXPath是PHP内置的XML/HTML解析器,提供了强大的文档遍历和查询能力。虽然XPath本身不支持直接在表达式中使用PCRE(Perl Compatible Regular Expressions),但DOMXPath::registerPHPFunctions()方法允许我们在XPath表达式中调用自定义的PHP函数,从而间接实现正则表达式匹配。
实现思路:
加载HTML: 使用DOMDocument加载HTML字符串。创建XPath实例: 创建DOMXPath对象。注册PHP函数: 使用registerPHPFunctions()注册一个PHP函数,该函数内部可以调用preg_match、preg_replace等正则函数。编写XPath表达式: 在XPath表达式中调用已注册的PHP函数来对节点内容进行正则匹配或筛选。
代码示例(概念性):
立即学习“PHP免费学习笔记(深入)”;
<?php$htmlCode = <<<HTML(xxx) xxxx xxxx
xxxxxxxxxx
xxxxx xxxx
HTML;$dom = new DOMDocument;// LIBXML_HTML_NOIMPLIED 和 LIBXML_HTML_NODEFDTD 用于防止自动添加不必要的HTML/BODY标签$dom->loadHTML($htmlCode, LIBXML_HTML_NOIMPLIED | LIBXML_HTML_NODEFDTD);$xpath = new DOMXPath($dom);// 注册一个PHP函数,例如用于判断字符串是否匹配电话号码$xpath->registerPHPFunctions('my_preg_match');function my_preg_match($haystack, $pattern) { return (bool) preg_match($pattern, $haystack);}// 示例XPath查询:查找内容匹配电话号码的文本节点// 注意:此处的XPath表达式仅为示意,实际应用中需要更复杂的逻辑来处理文本节点// 例如://text()[my_preg_match(., '/^(?d{3})?[s-]?d{3,4}[s-]?d{4}$/')]// 实际操作中,直接处理文本内容通常比在XPath中通过函数复杂// 更多关于此方法的详细信息可参考相关文档。echo "通过XPath结合PHP函数进行正则匹配的思路,实际操作中需根据具体场景构建XPath表达式。n";?>这种方法的优势在于能够利用DOMDocument的结构化解析能力,对特定节点进行操作。然而,其实现相对复杂,并且对于简单的文本查找替换,可能存在过度设计的风险。
方案二:直接使用PHP正则表达式处理HTML字符串
对于目标内容(如纯文本电话号码)位于标签内部,且HTML结构相对简单、可预测的情况,直接使用PHP的preg_match_all和preg_replace函数配合正则表达式,是一种更为直接和高效的方法。
1. 匹配HTML标签内部文本
要提取HTML标签内部的文本内容,我们可以使用正向后行断言和正向前行断言的组合。
核心正则表达式: /(?)(.*?)(?=
(?):这是一个正向后行断言(Positive Lookbehind),它匹配紧跟在>字符之后的位置,但>本身不包含在匹配结果中。(.*?):这是一个非贪婪匹配模式。它匹配任意字符(.)零次或多次(*),但尽可能少地匹配(?)。这确保它只匹配到下一个>或(?=m 修饰符:表示多行模式,允许^和$匹配每一行的开头和结尾(在本例中主要为了确保换行符不影响.*?的匹配)。
代码示例:使用 preg_match_all 提取标签内文本
<?php$htmlCode = '(xxx) xxxx xxxx
xxxxxxxxxx
xxxxx xxxx
';$regex = '/(?)(.*?)(?=2. 替换HTML标签内部文本
preg_replace函数可以直接对匹配到的模式进行替换。根据需求,我们可以替换所有标签内的文本,或者编写更精确的正则表达式来有针对性地替换特定内容(如电话号码)。
代码示例:通用文本替换
以下示例将替换所有HTML标签内的文本为指定字符串:
<?php$htmlCode = '(xxx) xxxx xxxx
xxxxxxxxxx
xxxxx xxxx
';// 匹配所有标签内文本的正则表达式$regexAllContent = '/(?)(.*?)(?=代码示例:有针对性地替换电话号码
为了更精确地替换HTML中的电话号码,我们需要一个能识别电话号码模式的正则表达式。以下是一个根据示例HTML中电话号码格式构建的相对宽泛的正则表达式。
<?php$htmlCode = '(xxx) xxxx xxxx
xxxxxxxxxx
xxxxx xxxx
';// 匹配示例中电话号码格式的正则表达式// 考虑 (xxx) xxxx xxxx, xxxxxxxxxx, (xxx) x xxx xxxx, xxxxx xxxx 等多种格式// 实际使用时需根据具体的电话号码格式进行调整和优化$phoneRegex = '/((d{3})s?d{3,4}s?d{4})|(d{10,11})|((d{3})sdsd{3}sd{4})|(d{5}sd{4})/m';$replacementForPhone = '[电话号码已移除]'; // 替换为指定字符串$htmlWithPhonesReplaced = preg_replace($phoneRegex, $replacementForPhone, $htmlCode);echo "n替换电话号码后的HTML:n";echo $htmlWithPhonesReplaced;?>注意事项与最佳实践
正则表达式处理HTML的局限性: 尽管正则表达式在特定场景下处理HTML非常有效,但它不适合解析复杂的、嵌套的或格式不规范的HTML。HTML是一种非正则语言,使用正则表达式解析它可能导致意外结果和维护困难。对于复杂的HTML解析任务,应优先使用DOMDocument、Simple HTML DOM Parser等专用的HTML解析库。适用场景: 本教程中直接使用正则表达式的方法更适用于目标文本位于明确的标签内部,且HTML结构相对扁平、可预测的情况。例如,从已知结构的HTML片段中提取或替换特定数据。电话号码正则的精确性: 实际应用中,电话号码的格式多种多样(带区号、国际码、不同分隔符等)。上述提供的电话号码正则表达式仅为示例,您需要根据实际需求编写更鲁棒、更精确的正则表达式来匹配目标格式。安全考虑: 在处理用户提交或外部来源的HTML时,务必进行输入验证和清理,以防止XSS(跨站脚本攻击)等安全漏洞。移除敏感信息(如电话号码)后,也应确保替换内容不会引入新的安全风险。
总结
在PHP中处理HTML内容时,当XPath的原生正则表达式支持不足时,我们可以采用两种主要策略:一是通过DOMXPath::registerPHPFunctions()方法扩展XPath,使其能够调用PHP的正则函数;二是直接利用PHP的preg_match_all和preg_replace函数配合精心构造的正则表达式,对HTML字符串进行直接操作。
对于
以上就是PHP中HTML内容正则查找与替换:替代XPath的方案的详细内容,更多请关注php中文网其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1334233.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫