本文深入探讨了在php中处理html内容时,如何有效地进行文本模式匹配与修改,特别是针对xpath在正则表达式支持上的局限性。文章介绍了两种主要方法:直接对html字符串使用php内置的正则表达式函数(如`preg_match_all`和`preg_replace`),以及结合`domdocument`进行结构化解析后再应用正则表达式,并提供了详细的代码示例和最佳实践建议,旨在帮助开发者高效、安全地操作html中的特定文本内容。
PHP中HTML内容正则匹配与修改:替代XPath的策略
在Web开发中,从HTML页面中提取或修改特定格式的文本(例如电话号码、邮箱地址等)是常见的需求。虽然XPath是处理XML/HTML文档结构的强大工具,但其对正则表达式的支持相对有限。本文将探讨在PHP中,如何在不完全依赖XPath内置正则功能的情况下,实现对HTML内容的精确正则匹配与修改。
1. 直接使用正则表达式处理HTML字符串
对于结构相对简单或对性能有较高要求的场景,可以直接将HTML内容作为字符串,然后使用PHP内置的preg_*系列函数进行正则表达式匹配和替换。这种方法直接、高效,但需要注意的是,正则表达式并非设计用于解析复杂的HTML结构,不当使用可能导致意外结果。
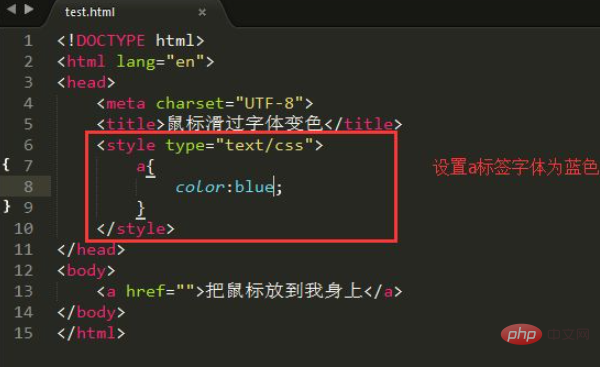
核心正则模式解析
为了匹配HTML标签内部的文本内容,一个常用的正则表达式模式是 (?)(.*?)(?=
(?):这是一个正向后行断言,它确保匹配的内容前面紧跟着一个 > 字符,但 > 本身不包含在匹配结果中。.*?:这是一个非贪婪匹配模式,. 匹配除换行符外的任何字符,* 表示匹配零次或多次,? 使其变为非贪婪模式,即尽可能少地匹配字符。(?=正向前行断言,它确保匹配的内容后面紧跟着一个
结合起来,这个模式的目的是精确捕获所有HTML标签之间的文本内容。
立即学习“PHP免费学习笔记(深入)”;
示例1:提取HTML标签内的文本内容
以下示例演示如何使用preg_match_all函数从HTML字符串中提取所有标签内的文本。
<?php$htmlContent = <<<HTML(xxx) xxxx xxxx
xxxxxxxxxx
xxxxx xxxx
HTML;$regex = '/(?)(.*?)(?=输出示例:
提取到的文本内容: - (xxx) xxxx xxxx - xxxxxxxxxx - (xxx) x xxx xxxx - xxxxx xxxx
示例2:替换HTML标签内的文本内容
如果目标是替换HTML标签内的特定文本,可以使用preg_replace函数。
<?php$htmlContent = <<<HTML(xxx) xxxx xxxx
xxxxxxxxxx
xxxxx xxxx
HTML;$regex = '/(?)(.*?)(?=输出示例:
替换后的内容
替换后的内容
替换后的内容
针对电话号码的更精确正则表达式建议
上述示例中的正则表达式 (?)(.*?)(?=
匹配 (xxx) xxxx xxxx 或 xxxxxxxxxx 格式:/(?d{3})?[s-]?d{3,4}[s-]?d{4}/这个模式可以匹配多种常见的电话号码格式,包括带括号、空格或短横线的。
结合起来,如果你想替换HTML中所有电话号码,可以先用DOMDocument提取文本节点,然后对每个文本节点应用电话号码的正则表达式。
2. 结合DOMDocument与PHP正则表达式(更健壮的方案)
直接对HTML字符串使用正则表达式虽然简便,但存在潜在风险,尤其是在HTML结构复杂、嵌套或不规范时,正则表达式可能无法正确解析,甚至导致页面结构损坏。更推荐的方案是使用PHP的DOMDocument类来解析HTML,然后对提取出的文本节点应用正则表达式。
优势
结构感知: DOMDocument能够正确解析HTML的树形结构,避免了正则表达式直接处理HTML标签可能引入的歧义。健壮性: 能够更好地处理不规范的HTML(尽管需要LIBXML_HTML_NOIMPLIED|LIBXML_HTML_NODEFDTD等选项)。精确控制: 可以精确地选择要操作的元素或文本节点。
实施步骤
加载HTML: 使用DOMDocument加载HTML字符串。创建DOMXPath对象: 用于通过XPath表达式选择特定的节点。遍历或选择节点: 使用XPath选择包含目标文本的元素或直接选择文本节点。提取文本内容: 获取节点的nodeValue。应用正则表达式: 对提取的文本内容使用preg_match_all或preg_replace。更新节点: 如果进行了替换操作,将修改后的文本重新设置回节点的nodeValue。
代码示例:使用DOMDocument和正则表达式替换电话号码
<?php$htmlContent = <<<HTML联系电话:(123) 4567 8901
客服热线:13812345678
公司前台:021-9876-5432
HTML;// 1. 加载HTML$dom = new DOMDocument;// LIBXML_HTML_NOIMPLIED 和 LIBXML_HTML_NODEFDTD 可以帮助处理片段HTML,避免自动添加$dom->loadHTML($htmlContent, LIBXML_HTML_NOIMPLIED | LIBXML_HTML_NODEFDTD);// 2. 创建DOMXPath对象$xpath = new DOMXPath($dom);// 3. 定义电话号码的正则表达式// 匹配多种格式的电话号码$phoneRegex = '/(?:(?d{3})?[s-]?d{3,4}[s-]?d{4}|d{10,11})/'; $replacement = '[电话号码已隐藏]'; // 替换文本// 4. 遍历所有文本节点// XPath表达式 //text() 可以选择文档中的所有文本节点$textNodes = $xpath->query('//text()');foreach ($textNodes as $textNode) { $originalText = $textNode->nodeValue; // 5. 对文本内容应用正则表达式进行替换 $modifiedText = preg_replace($phoneRegex, $replacement, $originalText); // 6. 如果文本有修改,则更新节点 if ($modifiedText !== $originalText) { $textNode->nodeValue = $modifiedText; }}// 输出修改后的HTMLecho $dom->saveHTML();?>输出示例:
联系电话:[电话号码已隐藏]
客服热线:[电话号码已隐藏]
公司前台:[电话号码已隐藏]
关于 registerPHPFunctions
DOMXPath类提供了 registerPHPFunctions() 方法,允许在XPath表达式中直接调用PHP函数。虽然这听起来可以解决XPath正则的局限性,但它通常用于更复杂的逻辑判断或数据转换,而不是直接在XPath表达式中执行文本内容的preg_replace。对于文本内容的正则匹配和替换,如上所示,在PHP代码中获取节点内容后直接使用preg_*函数通常更为直观和灵活。
注意事项与最佳实践
优先使用DOM解析: 除非有非常明确的理由和严格的HTML结构保证,否则应始终优先使用DOMDocument或类似的HTML解析库来处理HTML内容,而不是直接对HTML字符串使用正则表达式。精确的正则表达式: 设计正则表达式时,力求精确匹配目标模式,避免过度匹配或误匹配。对于电话号码、邮箱等敏感信息,更精确的模式可以防止意外修改。错误处理: 在处理外部或用户生成的HTML时,考虑DOMDocument加载失败的情况,并进行相应的错误处理。性能考量: 对于极大的HTML文件,直接字符串正则可能在某些情况下更快,但以牺牲健壮性和安全性为代价。在大多数Web应用场景中,DOMDocument的性能开销是可接受的。
总结
在PHP中处理HTML内容的正则表达式匹配与修改时,开发者有多种选择。直接对HTML字符串使用preg_*函数适合简单、局部的文本操作,但存在结构解析的风险。更推荐且健壮的方法是结合DOMDocument进行结构化解析,然后对提取的文本节点应用PHP的正则表达式功能。这种组合方式能够充分利用DOM的结构感知能力和正则表达式的模式匹配能力,实现对HTML内容的高效、安全操作。
以上就是PHP中HTML内容正则匹配与修改:替代XPath的策略的详细内容,更多请关注php中文网其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1334630.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫