
%ign%ignore_a_1%re_a_1% 正式发布全新语音模型 gpt-realtime,这是一款专为语音ai智能体设计的多模态模型,具备生成高度自然流畅语音的能力,可精准复现人类丰富的语调变化、情感表达及语速节奏。该模型支持图像理解,并能将视觉信息与语音或文本对话无缝融合,广泛适用于客服、教育、金融、医疗等场景中的语音智能体构建。
GPT-realtime 采用端到端的音频处理架构,直接对音频输入进行解析并生成回应,大幅降低响应延迟。此次更新推出了两种全新风格的语音——Marin 与 Cedar,同时对原有8种语音音色完成了全面优化升级。
据 OpenAI 介绍,该模型展现出更强的理解能力,尤其在母语语音识别方面表现更优。它能够识别非语言信号(如笑声)、实现句中语码切换,并根据情境调整语气风格(例如“简洁专业”或“亲切体贴”)。
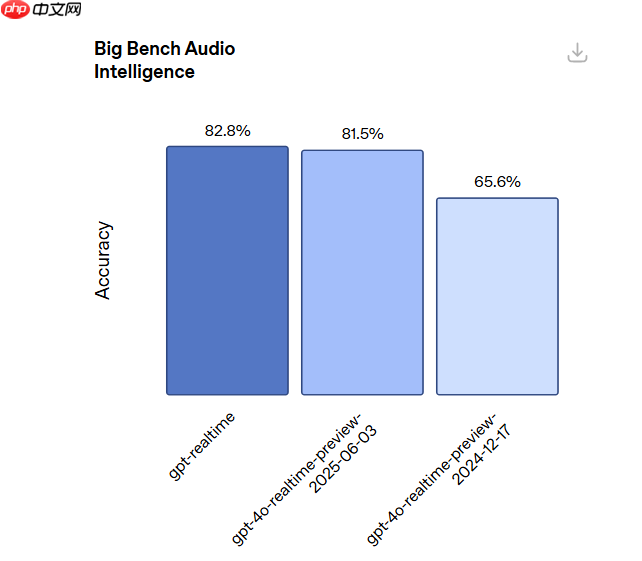
内部测试显示,GPT-realtime 在识别多种语言(包括西班牙语、中文、日语和法语)中的字母数字序列(如电话号码、车辆识别码等)任务中,准确率显著提升。在 Big Bench Audio 基准测试中,其推理能力得分达到 82.8%,远高于2024年12月发布的前一版本(65.6%)。
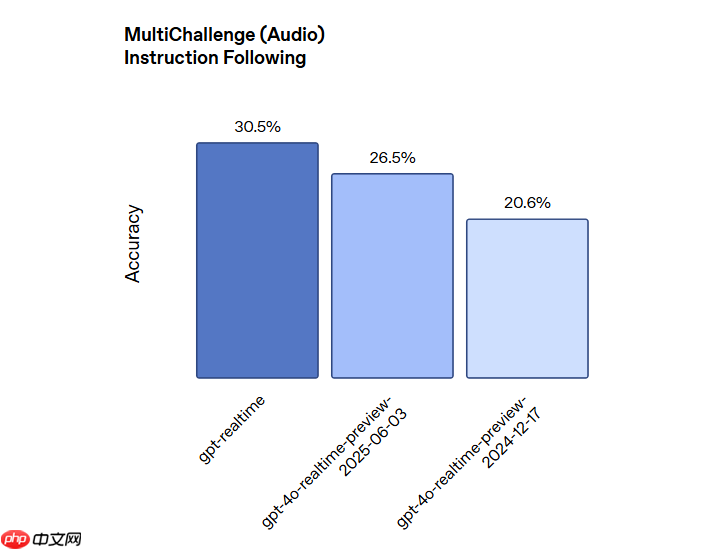
在衡量指令遵循能力的 MultiChallenge 音频基准测试中,gpt-realtime 得分为 30.5%,相较上一代模型的 20.6% 实现了明显进步。
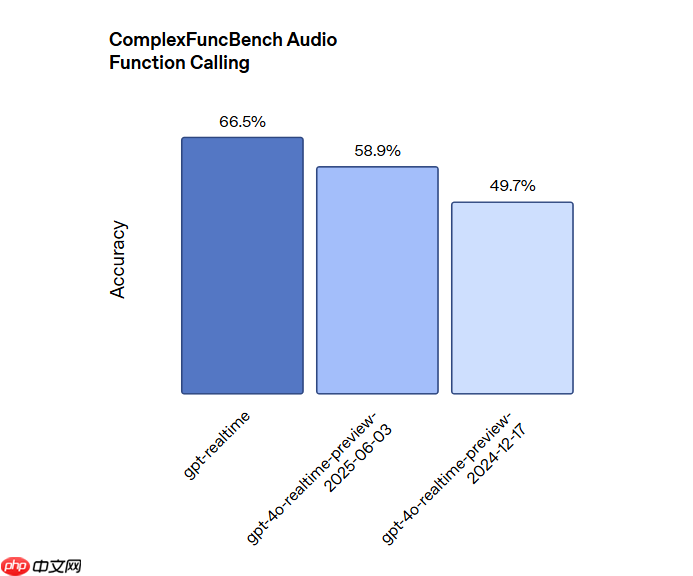
此外,GPT-realtime 增强了函数调用功能,新增对图像输入的支持,使得对话可基于视觉内容展开。多项API改进也让集成更加便捷,为开发者提供了更高的灵活性与可扩展性。
值得一提的是,本次模型的研发团队中包括两位95后华人研究员 Beichen Li 和 Liyu Chen。其中,Beichen Li 毕业于麻省理工学院(MIT),主要研究方向聚焦于计算机图形学与机器学习的交叉领域。
以上就是OpenAI 发布 GPT-realtime 语音对话模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/134503.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























