
探索性数据分析是一种流行的分析数据集并直观地呈现您的发现的方法。它有助于提供对数据集和结构的最大程度的洞察。这将探索性数据分析视为一种理解数据各个方面的技术。
为了更好地理解数据,必须确保数据干净、没有冗余、没有缺失值,甚至没有 null 值。
探索性数据分析的类型
主要分为三种:
单变量:这是您在任意时间查看一个变量(列)的地方。它有助于人们更多地了解变量的性质,被称为最简单的 eda 类型。
双变量:这是一起查看两个变量的地方。它有助于人们理解变量 a 和 b 之间的关系,无论它们是独立的还是相关的。
多变量:这涉及一次查看三个或更多变量。它被认为是“高级”二元变量。
方法
图形:这涉及通过图形和图表等视觉表示来探索数据。常见的可视化包括箱线图、条形图、散点图和热图。
非图形:这是通过统计技术完成的。使用的指标包括平均值、中位数、众数、标准差和百分位数。
探索性数据分析工具
一些最常用的 eda 工具包括
python:一种面向对象的编程语言,用于连接现有组件并识别缺失值
r:一种用于统计计算的开源编程语言
步骤
理解数据 – 查看您正在使用什么类型的数据;列数、行数和数据类型。 清理数据 – 这涉及处理缺失值、缺失行和 null 值等不规则行为。 分析 – 分析变量之间的关系。
使用 python 的 eda 示例
本示例使用的数据集是 iris 数据集 – 可以在此处获取
使用 pandas 库加载数据。
df = pd.read_csv(io.bytesio(uploaded['iris.csv']))df.head()
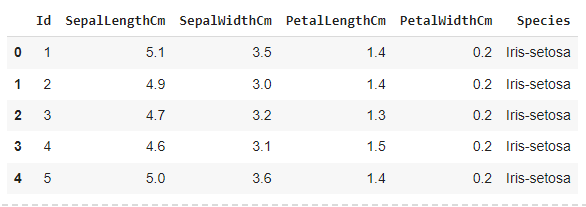
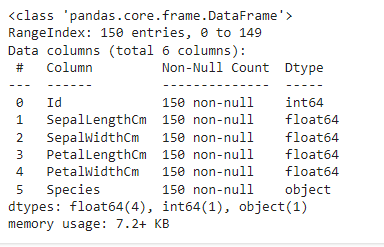
识别数据类型df.info()
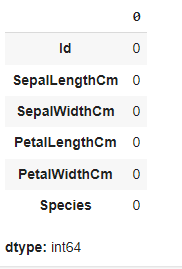
清理数据,例如检查 null 值df.isnull().sum()
对数据进行非图形分析以提供变量信息df.describe()

图形分析显示变量相关性或独立性
df.plot(kind='scatter', x='SepalLengthCm', y='SepalWidthCm') ;plt.show()

以上就是了解您的数据:探索性数据分析的要点的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1348830.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















