在上一篇博客中,我们了解了如何使用 2 个插件 apoc 和图形数据科学库 – gds 在本地安装和设置 neo4j。在这篇博客中,我将获取一个玩具数据集(电子商务网站中的产品)并将其存储在 neo4j 中。
为 neo4j 分配足够的内存
在开始加载数据之前,如果您的用例中有大量数据,请确保为 neo4j 分配了足够的内存。为此:
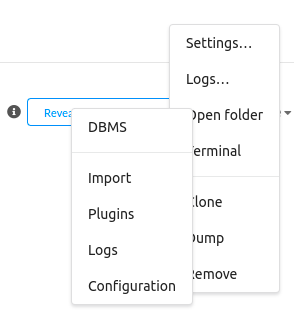
点击打开右侧的三个点

点击打开文件夹-> 配置
点击neo4j.conf
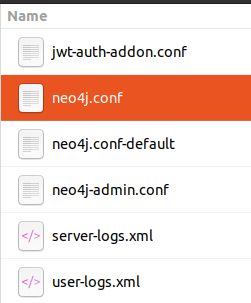
在neo4j.conf中搜索heap,取消第77、78行的注释,并将256m更改为2048m,这样可以确保为neo4j中的数据存储分配2048mb。

创建节点
图有两个主要组成部分:节点和关系,让我们先创建节点,然后再建立关系。
我正在使用的数据在这里 – data
使用这里提供的requirements.txt来创建一个python虚拟环境-requirements.txt
让我们定义各种函数来推送数据。
导入必要的库
import pandas as pdfrom neo4j import graphdatabasefrom openai import openai
我们将使用 openai 来生成嵌入
client = openai(api_key="")product_data_df = pd.read_csv('../data/product_data.csv')
生成嵌入
def get_embedding(text): """ used to generate embeddings using openai embeddings model :param text: str - text that needs to be converted to embeddings :return: embedding """ model = "text-embedding-3-small" text = text.replace("n", " ") return client.embeddings.create(input=[text], model=model).data[0].embedding
根据我们的数据集,我们可以有两个唯一的节点标签,category:产品类别,product:产品名称。让我们创建类别标签,neo4j 提供了一种称为属性的东西,您可以将它们想象为特定节点的元数据。这里 name 和 embedding 是属性。因此,我们将类别名称及其相应的嵌入存储在数据库中。
def create_category(product_data_df): """ used to generate queries for creating category nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for category """ cat_query = """create (a:category {name: '%s', embedding: %s})""" distinct_category = product_data_df['category'].unique() query_list = [] for category in distinct_category: embedding = get_embedding(category) query_list.append(cat_query % (category, embedding)) return query_list
类似地,我们可以创建产品节点,这里的属性是name,description,price,warranty_period,available_stock,review_ rating,product_release_date,embedding
def create_product(product_data_df): """ used to generate queries for creating product nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for product """ product_query = """create (a:product {name: '%s', description: '%s', price: %d, warranty_period: %d, available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})""" query_list = [] for idx, row in product_data_df.iterrows(): embedding = get_embedding(row['product name'] + " - " + row['description']) query_list.append(product_query % (row['product name'], row['description'], int(row['price (inr)']), int(row['warranty period (years)']), int(row['stock']), float(row['review rating']), str(row['product release date']), embedding)) return query_list
现在让我们创建另一个函数来执行上述两个函数生成的查询。适当更新您的用户名和密码。
def execute_bulk_query(query_list): """ executes queries is a list one by one :param query_list: list - list of cypher queries :return: none """ url = "bolt://localhost:7687" auth = ("neo4j", "neo4j@123") with graphdatabase.driver(url, auth=auth) as driver: with driver.session() as session: for query in query_list: try: session.run(query) except exception as error: print(f"error in executing query - {query}, error - {error}")
完整代码
import pandas as pdfrom neo4j import graphdatabasefrom openai import openaiclient = openai(api_key="")product_data_df = pd.read_csv('../data/product_data.csv')def preprocessing(df, columns_to_replace): """ used to preprocess certain column in dataframe :param df: pandas dataframe - data :param columns_to_replace: list - column name list :return: df: pandas dataframe - processed data """ df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s")) df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", "")) return dfdef get_embedding(text): """ used to generate embeddings using openai embeddings model :param text: str - text that needs to be converted to embeddings :return: embedding """ model = "text-embedding-3-small" text = text.replace("n", " ") return client.embeddings.create(input=[text], model=model).data[0].embeddingdef create_category(product_data_df): """ used to generate queries for creating category nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for category """ cat_query = """create (a:category {name: '%s', embedding: %s})""" distinct_category = product_data_df['category'].unique() query_list = [] for category in distinct_category: embedding = get_embedding(category) query_list.append(cat_query % (category, embedding)) return query_listdef create_product(product_data_df): """ used to generate queries for creating product nodes in neo4j :param product_data_df: pandas dataframe - data :return: query_list: list - list containing all create node queries for product """ product_query = """create (a:product {name: '%s', description: '%s', price: %d, warranty_period: %d, available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})""" query_list = [] for idx, row in product_data_df.iterrows(): embedding = get_embedding(row['product name'] + " - " + row['description']) query_list.append(product_query % (row['product name'], row['description'], int(row['price (inr)']), int(row['warranty period (years)']), int(row['stock']), float(row['review rating']), str(row['product release date']), embedding)) return query_listdef execute_bulk_query(query_list): """ executes queries is a list one by one :param query_list: list - list of cypher queries :return: none """ url = "bolt://localhost:7687" auth = ("neo4j", "neo4j@123") with graphdatabase.driver(url, auth=auth) as driver: with driver.session() as session: for query in query_list: try: session.run(query) except exception as error: print(f"error in executing query - {query}, error - {error}")# preprocessingproduct_data_df = preprocessing(product_data_df, ['product name', 'description'])# create categoryquery_list = create_category(product_data_df)execute_bulk_query(query_list)# create productquery_list = create_product(product_data_df)execute_bulk_query(query_list)
建立关系
我们将在 category 和 product 之间创建关系,该关系的名称为 category_contains_product
from neo4j import GraphDatabaseimport pandas as pdproduct_data_df = pd.read_csv('../data/product_data.csv')def preprocessing(df, columns_to_replace): """ Used to preprocess certain column in dataframe :param df: pandas dataframe - data :param columns_to_replace: list - column name list :return: df: pandas dataframe - processed data """ df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s")) df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", "")) return dfdef create_category_food_relationship_query(product_data_df): """ Used to create relationship between category and products :param product_data_df: dataframe - data :return: query_list: list - cypher queries """ query = """MATCH (c:Category {name: '%s'}), (p:Product {name: '%s'}) CREATE (c)-[:CATEGORY_CONTAINS_PRODUCT]->(p)""" query_list = [] for idx, row in product_data_df.iterrows(): query_list.append(query % (row['Category'], row['Product Name'])) return query_listdef execute_bulk_query(query_list): """ Executes queries is a list one by one :param query_list: list - list of cypher queries :return: None """ url = "bolt://localhost:7687" auth = ("neo4j", "neo4j@123") with GraphDatabase.driver(url, auth=auth) as driver: with driver.session() as session: for query in query_list: try: session.run(query) except Exception as error: print(f"Error in executing query - {query}, Error - {error}")# PREPROCESSINGproduct_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])# CATEGORY - FOOD RELATIONSHIPquery_list = create_category_food_relationship_query(product_data_df)execute_bulk_query(query_list)
通过使用 match 查询来匹配已经创建的节点,我们在它们之间建立关系。
可视化创建的节点
将鼠标悬停在
open图标上,然后单击neo4j浏览器以可视化我们创建的节点。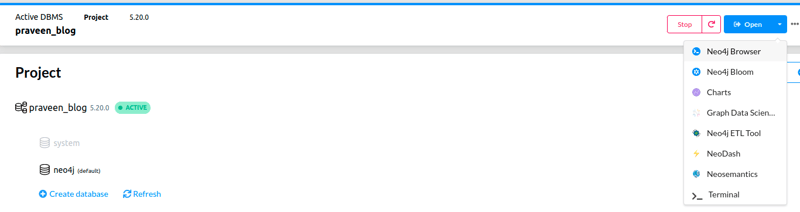
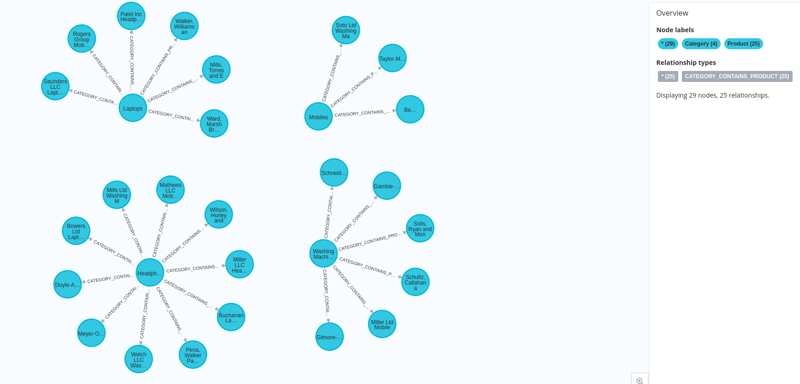
我们的数据连同它们的嵌入一起加载到 neo4j 中。
在接下来的博客中,我们将看到如何使用 python 构建图形查询引擎并使用获取的数据进行增强生成。
希望这有帮助…再见!
linkedin – https://www.linkedin.com/in/praveenr2998/
github – https://github.com/praveenr2998/creating-lightweight-rag-systems-with-graphs/tree/main/push_data_to_db
以上就是将数据加载到 Neo4j 中的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1349268.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫