
问题
很难说 atlassian jira 是最受欢迎的问题跟踪器和项目管理解决方案之一。你可以喜欢它,也可以讨厌它,但如果你被某家公司聘用为软件工程师,那么很有可能会遇到 jira。
如果您正在从事的项目非常活跃,可能会有数千个各种类型的 jira 问题。如果您领导着一个工程师团队,您可能会对分析工具感兴趣,这些工具可以帮助您根据 jira 中存储的数据了解项目中发生的情况。 jira 集成了一些报告工具以及第三方插件。但其中大多数都是非常基本的。例如,很难找到相当灵活的“预测”工具。
项目越大,您对集成报告工具的满意度就越低。在某些时候,您最终将使用 api 来提取、操作和可视化数据。在过去 15 年的 jira 使用过程中,我看到了围绕该领域的数十个采用各种编程语言的此类脚本和服务。
许多日常任务可能需要一次性数据分析,因此每次都编写服务并没有什么回报。您可以将 jira 视为数据源并使用典型的数据分析工具带。例如,您可以使用 jupyter,获取项目中最近的错误列表,准备“特征”列表(对分析有价值的属性),利用 pandas 计算统计数据,并尝试使用 scikit-learn 预测趋势。在这篇文章中,我想解释一下如何做到这一点。
准备
jira api 访问
这里我们要说的是云版jira。但如果您使用的是自托管版本,主要概念几乎是相同的。
首先,我们需要创建一个密钥来通过 rest api 访问 jira。为此,请转到配置文件管理 – https://id.atlassian.com/manage-profile/profile-and-visibility 如果选择“安全”选项卡,您将找到“创建和管理 api 令牌”链接:
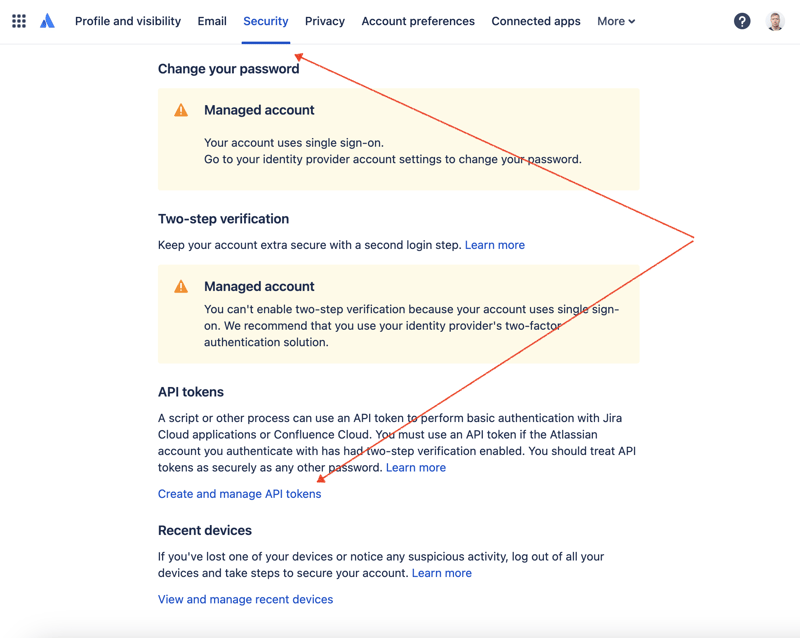
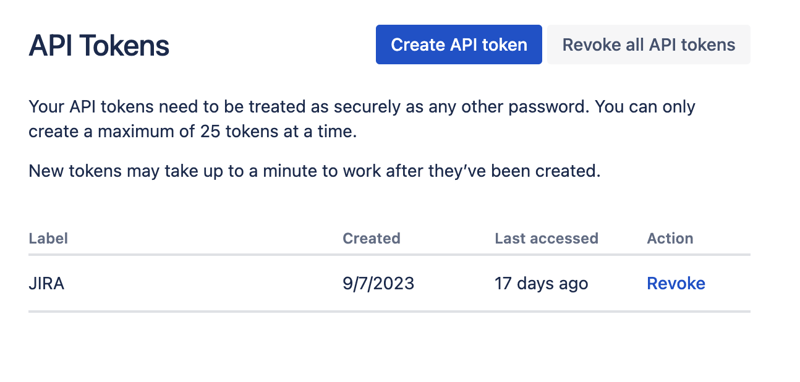
在此处创建一个新的 api 令牌并安全地存储它。我们稍后会使用这个令牌。
jupyter 笔记本
处理数据集最方便的方法之一是使用 jupyter。如果您不熟悉这个工具,请不要担心。我将展示如何使用它来解决我们的问题。对于本地实验,我喜欢使用 jetbrains 的 dataspell,但也有免费的在线服务。 kaggle 是数据科学家中最知名的服务之一。但是,他们的笔记本不允许您建立外部连接以通过 api 访问 jira。另一项非常受欢迎的服务是 google 的 colab。它允许您进行远程连接并安装额外的 python 模块。
jira 有一个非常易于使用的 rest api。您可以使用您最喜欢的 http 请求方式进行 api 调用并手动解析响应。然而,我们将利用一个优秀且非常流行的 jira 模块来实现此目的。
实际使用的工具
数据分析
让我们结合所有部分来提出解决方案。
进入google colab界面并创建一个新笔记本。创建笔记本后,我们需要将之前获得的 jira 凭据存储为“秘密”。单击左侧工具栏中的“密钥”图标打开相应的对话框并添加两个具有以下名称的“秘密”:jira_user 和 jira_password。在屏幕底部,您可以看到如何访问这些“秘密”:
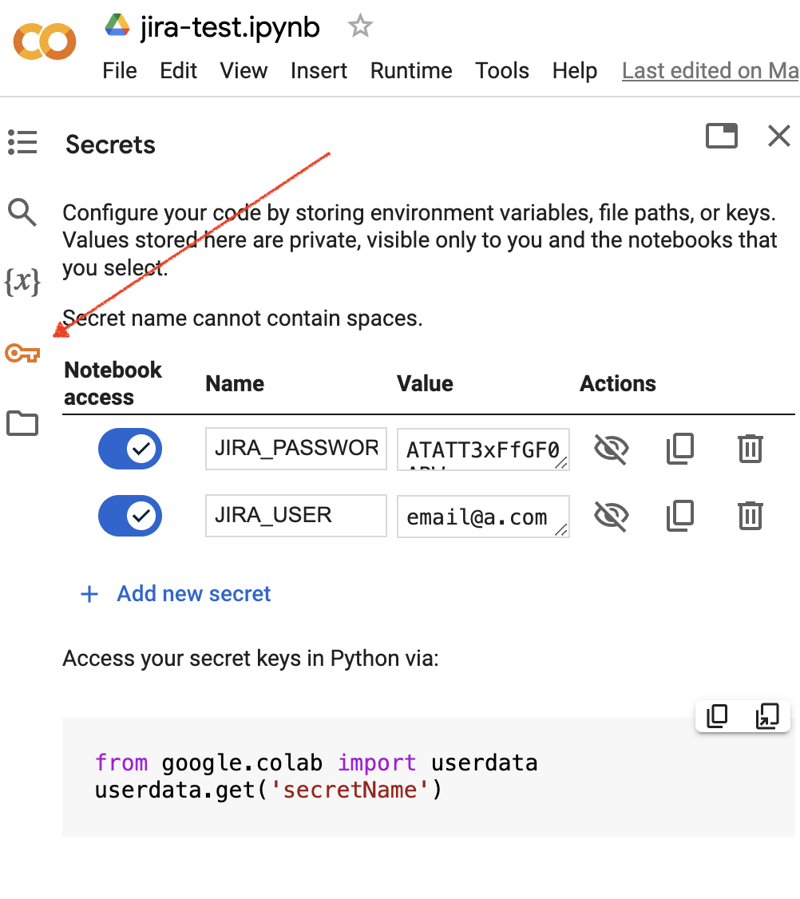
接下来是安装额外的 python 模块以进行 jira 集成。我们可以通过在笔记本单元范围内执行 shell 命令来做到这一点:
!pip install jira
输出应如下所示:
collecting jira downloading jira-3.8.0-py3-none-any.whl (77 kb) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 77.5/77.5 kb 1.3 mb/s eta 0:00:00requirement already satisfied: defusedxml in /usr/local/lib/python3.10/dist-packages (from jira) (0.7.1)...installing collected packages: requests-toolbelt, jirasuccessfully installed jira-3.8.0 requests-toolbelt-1.0.0
我们需要获取“秘密”/凭证:
from google.colab import userdatajira_url = 'https://******.atlassian.net'jira_user = userdata.get('jira_user')jira_password = userdata.get('jira_password')
并验证与 jira cloud 的连接:
from jira import jirajira = jira(jira_url, basic_auth=(jira_user, jira_password))projects = jira.projects()projects
如果连接正常并且凭据有效,您应该会看到一个非空的项目列表:
[, , ,...
这样我们就可以从 jira 连接并获取数据了。下一步是获取一些数据以使用 pandas 进行分析。让我们尝试获取某个项目在过去几周内已解决问题的列表:
jira_filter = 19762issues = jira.search_issues( f'filter={jira_filter}', maxresults=false, fields='summary,issuetype,assignee,reporter,aggregatetimespent',)
我们需要将数据集转换为pandas数据框:
import pandas as pddf = pd.dataframe([{ 'key': issue.key, 'assignee': issue.fields.assignee and issue.fields.assignee.displayname or issue.fields.reporter.displayname, 'time': issue.fields.aggregatetimespent, 'summary': issue.fields.summary,} for issue in issues])df.set_index('key', inplace=true)df
输出可能如下所示:
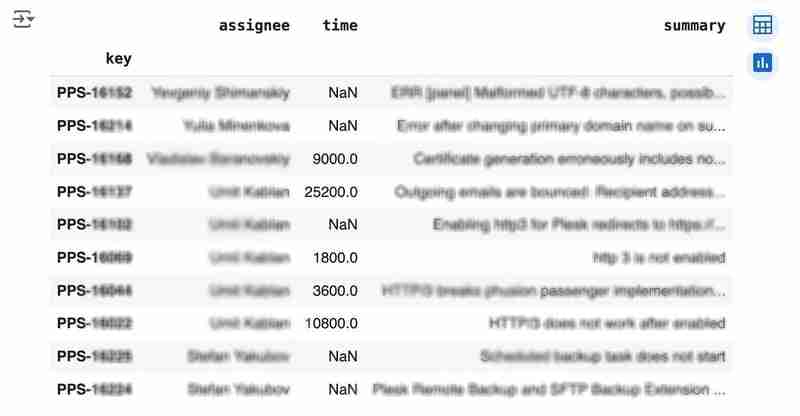
我们想分析一下解决问题通常需要多长时间。人都是不理想的,所以有时他们会忘记记录工作。如果您尝试使用 jira 内置工具分析此类数据,则会带来麻烦。但我们用pandas做一些调整并不是问题。例如,我们可以将“时间”字段从秒转换为小时,并用中值替换缺失的值(注意,如果有很多间隙,dropna 可能更合适):
df['time'].fillna(df['time'].median(), inplace=true)df['time'] = df['time'] / 3600
我们可以轻松地可视化分布以找出异常情况:
df['time'].plot.bar(xlabel='', xticks=[])
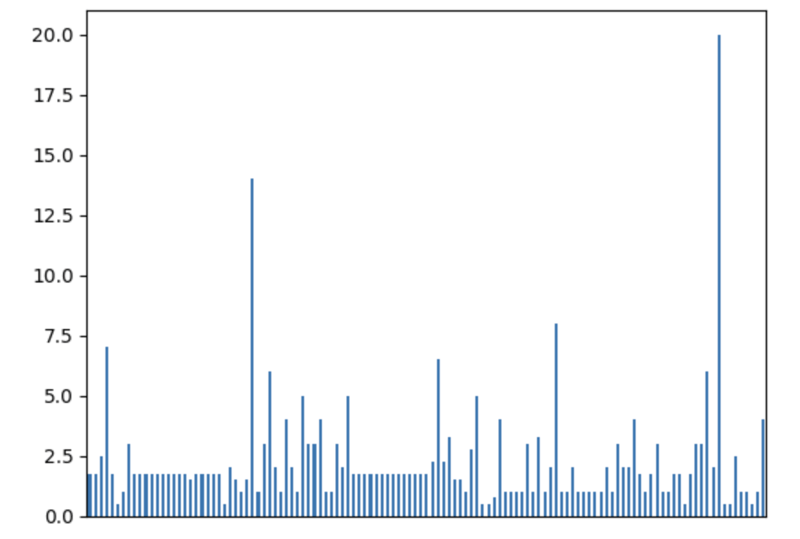
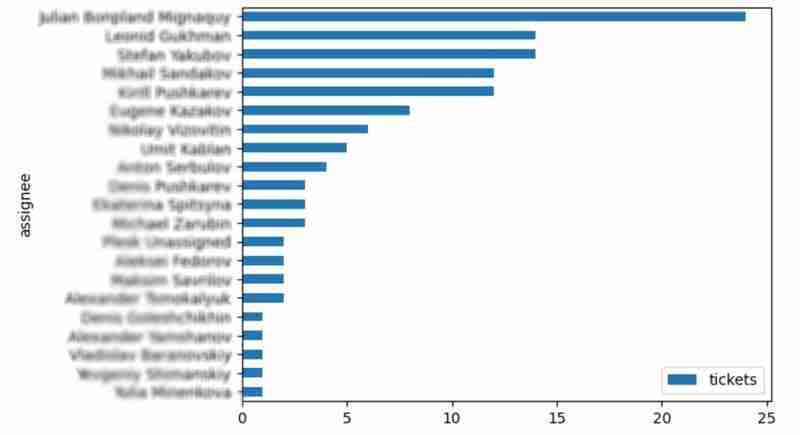
查看受让人解决的问题的分布也很有趣:
top_solvers = df.groupby('assignee').count()[['time']]top_solvers.rename(columns={'time': 'tickets'}, inplace=true)top_solvers.sort_values('tickets', ascending=false, inplace=true)top_solvers.plot.barh().invert_yaxis()
它可能看起来像下面这样:
预测
让我们尝试预测完成所有未决问题所需的时间。当然,我们可以在没有机器学习的情况下,通过使用简单的近似和平均时间来解决问题。因此,预计所需时间就是未解决问题的数量乘以解决问题的平均时间。例如,解决一个问题的平均时间为 2 小时,而我们有 9 个未解决的问题,因此解决所有问题所需的时间为 18 小时(近似值)。这是一个足够好的预测,但我们可能知道解决的速度取决于产品、团队和问题的其他属性。如果我们想改进预测,我们可以利用机器学习来解决这个任务。
高级方法如下所示:
获取“学习”数据集清理数据准备“特征”,又名“特征工程”训练模型使用模型来预测目标数据集的某些值
第一步,我们将使用过去 30 周的门票数据集。出于说明目的,此处对某些部分进行了简化。在现实生活中,用于学习的数据量应该足够大才能建立有用的模型(例如,在我们的例子中,我们需要分析数千个问题)。
issues = jira.search_issues( f'project = pps and status in (resolved) and created >= -30w', maxresults=false, fields='summary,issuetype,customfield_10718,customfield_10674,aggregatetimespent',)closed_tickets = pd.dataframe([{ 'key': issue.key, 'team': issue.fields.customfield_10718, 'product': issue.fields.customfield_10674, 'time': issue.fields.aggregatetimespent,} for issue in issues])closed_tickets.set_index('key', inplace=true)closed_tickets['time'].fillna(closed_tickets['time'].median(), inplace=true)closed_tickets
就我而言,大约有 800 张门票,并且只有两个“学习”字段:“团队”和“产品”。
下一步是获取我们的目标数据集。我为什么这么早做?我想一次性清理两个数据集并进行“特征工程”。否则,结构之间的不匹配可能会导致问题。
issues = jira.search_issues( f'project = pps and status in (open, reopened)', maxresults=false, fields='summary,issuetype,customfield_10718,customfield_10674',)open_tickets = pd.dataframe([{ 'key': issue.key, 'team': issue.fields.customfield_10718, 'product': issue.fields.customfield_10674,} for issue in issues])open_tickets.set_index('key', inplace=true)open_tickets
请注意,我们这里没有“时间”列,因为我们想要预测它。让我们取消它并结合两个数据集来准备“特征”。
open_tickets['time'] = 0tickets = pd.concat([closed_tickets, open_tickets])tickets
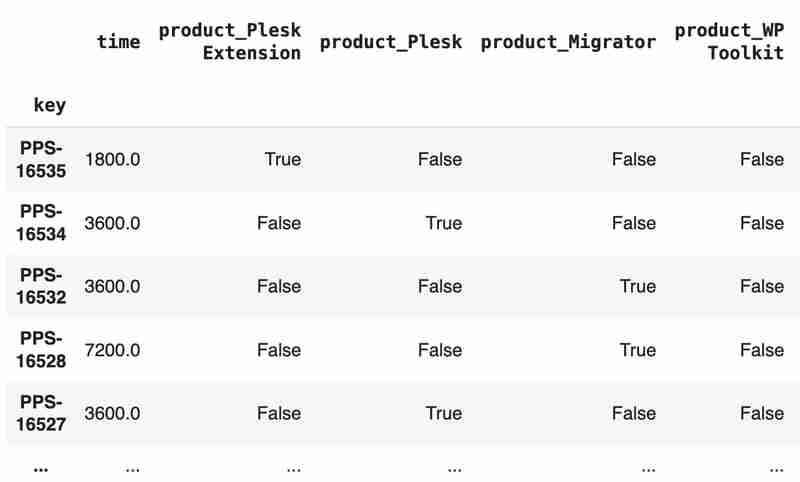
“团队”和“产品”列包含字符串值。处理这个问题的方法之一是将每个值转换为带有布尔标志的单独字段。
products = pd.get_dummies(tickets['product'], prefix='product')tickets = pd.concat([tickets, products], axis=1)tickets.drop('product', axis=1, inplace=true)teams = pd.get_dummies(tickets['team'], prefix='team')tickets = pd.concat([tickets, teams], axis=1)tickets.drop('team', axis=1, inplace=true)tickets
结果可能如下所示:
组合数据集准备完毕后,我们可以将其分成两部分:
closed_tickets = tickets[:len(closed_tickets)]open_tickets = tickets[len(closed_tickets):][:]
现在是时候训练我们的模型了:
from sklearn.model_selection import train_test_splitfrom sklearn.tree import decisiontreeregressorfeatures = closed_tickets.drop(['time'], axis=1)labels = closed_tickets['time']features_train, features_val, labels_train, labels_val = train_test_split(features, labels, test_size=0.2)model = decisiontreeregressor()model.fit(features_train, labels_train)model.score(features_val, labels_val)
最后一步是使用我们的模型进行预测:
open_tickets['time'] = model.predict(open_tickets.drop('time', axis=1, errors='ignore'))open_tickets['time'].sum() / 3600
最终的输出,就我而言,是 25 小时,这比我们最初的粗略估计要高。这是一个基本的例子。但是,通过使用 ml 工具,您可以显着扩展分析 jira 数据的能力。
结论
有时,jira 内置工具和插件不足以进行有效分析。此外,许多第 3 方插件相当昂贵,每年花费数千美元,而且您仍然很难让它们按照您想要的方式工作。然而,您可以通过 jira api 获取必要的信息,轻松利用众所周知的数据分析工具,并超越这些限制。我花了很多时间使用各种 jira 插件,试图为项目创建好的报告,但它们经常错过一些重要的部分。在 jira api 之上构建工具或功能齐全的服务通常看起来也有些过头了。这就是为什么 jupiter、pandas、matplotlib、scikit-learn 等典型数据分析和 ml 工具在这里可能效果更好。

以上就是使用 Pandas 进行 JIRA 分析的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1349403.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























