
介绍 :
各位,在 it 运营中,监视服务器指标(例如 cpu/内存和磁盘或文件系统的利用率)是一项非常通用的任务,但如果任何指标被触发为关键指标,则需要专门人员通过以下方式执行一些基本故障排除:登录服务器并找出使用的最初原因,如果该人收到多个相同的警报,导致无聊且根本没有生产力,则他必须多次执行该操作。因此,作为一种解决方法,可以开发一个系统,一旦触发警报,该系统就会做出反应,并通过执行一些基本的故障排除命令来对这些实例采取行动。只是总结问题陈述和期望 –
问题陈述:
开发一个能够满足低于预期的系统 –
每个 ec2 实例都应该由 cloudwatch 监控。一旦触发警报,就必须有一些东西可以登录到受影响的 ec2 实例并执行一些基本的故障排除命令。然后,创建一个 jira 问题来记录该事件,并在评论部分添加命令的输出。然后,发送一封自动电子邮件,其中提供所有警报详细信息和 jira 问题详细信息。
架构图:
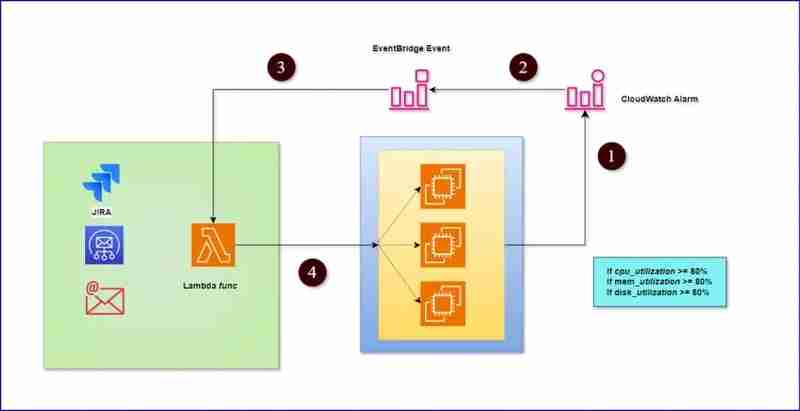
先决条件:
ec2 实例cloudwatch 警报eventbridge 规则lambda 函数jira 账户简单的通知服务
实施步骤:
a. cloudwatch 代理安装和配置设置:
打开 systems manager 控制台并单击“文档”
搜索“aws-configureawspackage”文档并通过提供所需的详细信息来执行。
包名称 = amazoncloudwatchagent
安装后,需要根据配置文件配置 cloudwatch 代理。为此,请执行 amazoncloudwatch-manageagent 文档。另外,请确保 json cloudwatch 配置文件存储在 ssm 参数中。
一旦您看到指标正在向 cloudwatch 控制台报告,请为 cpu 和内存利用率等创建警报。
b.设置eventbridge规则:
为了跟踪警报状态的变化,这里,我们稍微定制了模式来跟踪警报状态从 ok 到 alarm 的变化,而不是反向变化。然后,将此规则添加到 lambda 函数作为触发器。
{ "source": ["aws.cloudwatch"], "detail-type": ["cloudwatch alarm state change"], "detail": { "state": { "value": ["alarm"] }, "previousstate": { "value": ["ok"] } }}
c.创建 lambda 函数以在 jira 中发送电子邮件和记录事件:此 lambda 函数是为由 eventbridge 规则触发的多个活动创建的,并作为使用 aws sdk(boto3) 添加的目标 sns 主题。一旦触发 eventbridge 规则,就会将 json 事件内容发送到 lambda,该函数通过该函数捕获多个详细信息以不同的方式进行处理。到目前为止,我们已经研究了两种类型的警报 – i。 cpu 利用率和 ii.内存利用率。一旦这两个警报中的任何一个被触发并且警报状态从 ok 更改为 alarm,就会触发 eventbridge,这也会触发 lambda 函数来执行表单代码中提到的那些任务。
lambda 先决条件:
我们需要导入以下模块才能使代码正常工作 –
>> 操作系统>> 系统>> json>> boto3>> 时间>> 请求
注意: 从上面的模块中,除了“requests”模块之外,其余的都默认在 lambda 底层基础设施中下载。 lambda 不支持直接导入“requests”模块。因此,首先,通过执行以下命令将请求模块安装在本地计算机(笔记本电脑)的文件夹中 –
pip3 install requests -t --no-user
_之后,这将被下载到您执行上述命令的文件夹或您想要存储模块源代码的文件夹中,这里我希望 lambda 代码正在您的本地计算机中准备。如果是,则使用 module.txt 创建整个 lambda 源代码的 zip 文件。之后,将 zip 文件上传到 lambda 函数。
所以,我们在这里执行以下两个场景 –
1. cpu 利用率 – 如果触发 cpu 利用率警报,则 lambda 函数需要获取实例并登录到该实例并执行前 5 个高消耗进程。然后,它将创建一个 jira 问题并在评论部分添加流程详细信息。同时,它将发送一封电子邮件,其中包含警报详细信息和 jira 问题详细信息以及流程输出。
2.内存利用率 – 与上面相同的方法
现在,让我重新构建 lambda 应该执行的任务细节 –
登录实例执行基本故障排除步骤。创建 jira 问题向收件人发送包含所有详细信息的电子邮件
场景 1:当警报状态从 ok 更改为 alarm 时
第一组(定义cpu和内存函数):
################# importing required modules ############################################################################import jsonimport boto3import timeimport osimport syssys.path.append('./python') ## this will add requests module along with all dependencies into this scriptimport requestsfrom requests.auth import httpbasicauth################## calling aws services ##############################################################################ssm = boto3.client('ssm')sns_client = boto3.client('sns')ec2 = boto3.client('ec2')################## defining blank variable ###########################################################################cpu_process_op = ''mem_process_op = ''issueid = ''issuekey = ''issuelink = ''################# function for cpu utilization ###############################################################################def cpu_utilization(instanceid, metric_name, previous_state, current_state): global cpu_process_op if previous_state == 'ok' and current_state == 'alarm': command = 'ps -eo user,pid,ppid,cmd,%mem,%cpu --sort=-%cpu | head -5' print(f'impacted instance id is : {instanceid}, metric name: {metric_name}') # start a session print(f'starting session to {instanceid}') response = ssm.send_command(instanceids = [instanceid], documentname="aws-runshellscript", parameters={'commands': [command]}) command_id = response['command']['commandid'] print(f'command id: {command_id}') # retrieve the command output time.sleep(4) output = ssm.get_command_invocation(commandid=command_id, instanceid=instanceid) print('please find below output -n', output['standardoutputcontent']) cpu_process_op = output['standardoutputcontent'] else: print('none')################# function for memory utilization ############################################################################### def mem_utilization(instanceid, metric_name, previous_state, current_state): global mem_process_op if previous_state == 'ok' and current_state == 'alarm': command = 'ps -eo user,pid,ppid,cmd,%mem,%cpu --sort=-%mem | head -5' print(f'impacted instance id is : {instanceid}, metric name: {metric_name}') # start a session print(f'starting session to {instanceid}') response = ssm.send_command(instanceids = [instanceid], documentname="aws-runshellscript", parameters={'commands': [command]}) command_id = response['command']['commandid'] print(f'command id: {command_id}') # retrieve the command output time.sleep(4) output = ssm.get_command_invocation(commandid=command_id, instanceid=instanceid) print('please find below output -n', output['standardoutputcontent']) mem_process_op = output['standardoutputcontent'] else: print('none')
第二组(创建 jira 问题):
################## create jira issue #####################################################################def create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val): ## create issue ## url ='https://.atlassian.net//rest/api/2/issue' username = os.environ['username'] api_token = os.environ['token'] project = 'anirbanspace' issue_type = 'incident' assignee = os.environ['username'] summ_metric = '%cpu utilization' if 'cpu' in metric_name else '%memory utilization' if 'mem' in metric_name else '%filesystem utilization' if metric_name == 'disk_used_percent' else none metric_val = metric_val summary = f'client | {account} | {instanceid} | {summ_metric} | metric value: {metric_val}' description = f'client: companynaccount: {account}nregion: {region}ninstanceid = {instanceid}ntimestamp = {timestamp}ncurrent state: {current_state}nprevious state = {previous_state}nmetric value = {metric_val}' issue_data = { "fields": { "project": { "key": "scrum" }, "summary": summary, "description": description, "issuetype": { "name": issue_type }, "assignee": { "name": assignee } } } data = json.dumps(issue_data) headers = { "accept": "application/json", "content-type": "application/json" } auth = httpbasicauth(username, api_token) response = requests.post(url, headers=headers, auth=auth, data=data) global issueid global issuekey global issuelink issueid = response.json().get('id') issuekey = response.json().get('key') issuelink = response.json().get('self') ################ add comment to above created jira issue ################### output = cpu_process_op if metric_name == 'cpuutilization' else mem_process_op if metric_name == 'mem_used_percent' else none comment_api_url = f"{url}/{issuekey}/comment" add_comment = requests.post(comment_api_url, headers=headers, auth=auth, data=json.dumps({"body": output})) ## check the response if response.status_code == 201: print("issue created successfully. issue key:", response.json().get('key')) else: print(f"failed to create issue. status code: {response.status_code}, response: {response.text}")
第三组(发送电子邮件):
################## send an email #################################################################def send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink): ### define a dictionary of custom input ### metric_list = {'mem_used_percent': 'memory', 'disk_used_percent': 'disk', 'cpuutilization': 'cpu'} ### conditions ### if previous_state == 'ok' and current_state == 'alarm' and metric_name in list(metric_list.keys()): metric_msg = metric_list[metric_name] output = cpu_process_op if metric_name == 'cpuutilization' else mem_process_op if metric_name == 'mem_used_percent' else none print('this is output', output) email_body = f"hi team, nnplease be informed that {metric_msg} utilization is high for the instanceid {instanceid}. please find below more information nnalarm details:nmetricname = {metric_name}, naccount = {account}, ntimestamp = {timestamp}, nregion = {region}, ninstanceid = {instanceid}, ncurrentstate = {current_state}, nreason = {current_reason}, nmetricvalue = {metric_val}, nthreshold = 80.00 nnprocessoutput: n{output}nincident deatils:nissueid = {issueid}, nissuekey = {issuekey}, nlink = {issuelink}nnregards,nanirban das,nglobal cloud operations team" res = sns_client.publish( topicarn = os.environ['snsarn'], subject = f'high {metric_msg} utilization alert : {instanceid}', message = str(email_body) ) print('mail has been sent') if res else print('email not sent') else: email_body = str(0)
第四组(调用 lambda 处理函数):
################## lambda handler function ###########################################################################def lambda_handler(event, context): instanceid = event['detail']['configuration']['metrics'][0]['metricstat']['metric']['dimensions']['instanceid'] metric_name = event['detail']['configuration']['metrics'][0]['metricstat']['metric']['name'] account = event['account'] timestamp = event['time'] region = event['region'] current_state = event['detail']['state']['value'] current_reason = event['detail']['state']['reason'] previous_state = event['detail']['previousstate']['value'] previous_reason = event['detail']['previousstate']['reason'] metric_val = json.loads(event['detail']['state']['reasondata'])['evaluateddatapoints'][0]['value'] ##### function calling ##### if metric_name == 'cpuutilization': cpu_utilization(instanceid, metric_name, previous_state, current_state) create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val) send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink) elif metric_name == 'mem_used_percent': mem_utilization(instanceid, metric_name, previous_state, current_state) create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val) send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink) else: none
报警邮件截图:
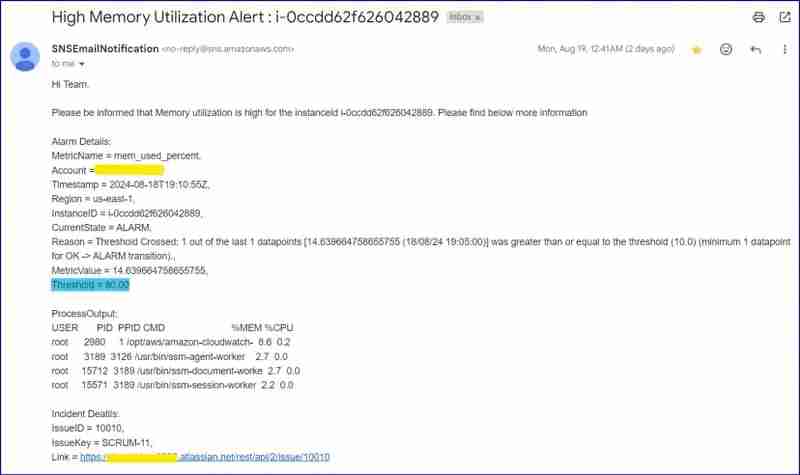
注意:在理想情况下,阈值是 80%,但为了测试我将其更改为 10%。请看原因。
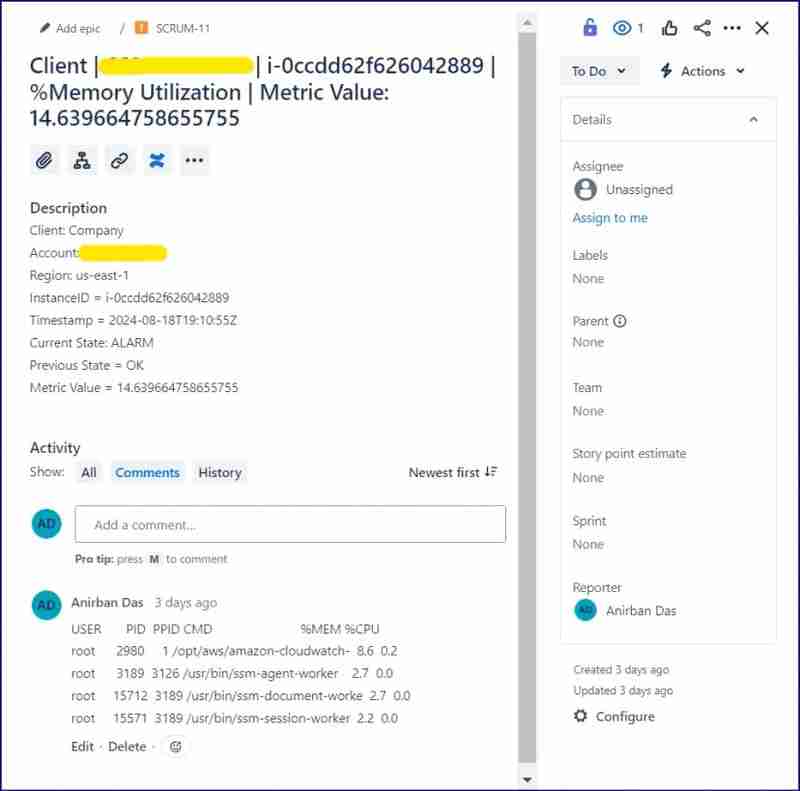
警报 jira 问题:
场景 2:当警报状态从“正常”更改为“数据不足”时
在这种情况下,如果未捕获任何服务器 cpu 或内存利用率指标数据,则警报状态将从 ok 更改为 insufficient_data。可以通过两种方式实现此状态 – a.) 如果服务器处于停止状态 b.) 如果 cloudwatch 代理未运行或进入死亡状态。
因此,根据下面的脚本,您将能够看到,当 cpu 或内存利用率警报状态获取的数据不足时,lambda 将首先检查实例是否处于运行状态。如果实例处于运行状态,那么它将登录并检查 cloudwatch 代理状态。发布后,它将创建一个 jira 问题并在 jira 问题的评论部分发布代理状态。之后,它将发送一封包含警报详细信息和代理状态的电子邮件。
完整代码:
################# Importing Required Modules ############################################################################import jsonimport boto3import timeimport osimport syssys.path.append('./python') ## This will add requests module along with all dependencies into this scriptimport requestsfrom requests.auth import HTTPBasicAuth################## Calling AWS Services ##############################################################################ssm = boto3.client('ssm')sns_client = boto3.client('sns')ec2 = boto3.client('ec2')################## Defining Blank Variable ###########################################################################cpu_process_op = ''mem_process_op = ''issueid = ''issuekey = ''issuelink = ''################# Function for CPU Utilization ###############################################################################def cpu_utilization(instanceid, metric_name, previous_state, current_state): global cpu_process_op if previous_state == 'OK' and current_state == 'INSUFFICIENT_DATA': ec2_status = ec2.describe_instance_status(InstanceIds=[instanceid,])['InstanceStatuses'][0]['InstanceState']['Name'] if ec2_status == 'running': command = 'systemctl status amazon-cloudwatch-agent;sleep 3;systemctl restart amazon-cloudwatch-agent' print(f'Impacted Instance ID is : {instanceid}, Metric Name: {metric_name}') # Start a session print(f'Starting session to {instanceid}') response = ssm.send_command(InstanceIds = [instanceid], DocumentName="AWS-RunShellScript", Parameters={'commands': [command]}) command_id = response['Command']['CommandId'] print(f'Command ID: {command_id}') # Retrieve the command output time.sleep(4) output = ssm.get_command_invocation(CommandId=command_id, InstanceId=instanceid) print('Please find below output -n', output['StandardOutputContent']) cpu_process_op = output['StandardOutputContent'] else: cpu_process_op = f'Instance current status is {ec2_status}. Not able to reach out!!' print(f'Instance current status is {ec2_status}. Not able to reach out!!') else: print('None')################# Function for Memory Utilization ############################################################################### def mem_utilization(instanceid, metric_name, previous_state, current_state): global mem_process_op if previous_state == 'OK' and current_state == 'INSUFFICIENT_DATA': ec2_status = ec2.describe_instance_status(InstanceIds=[instanceid,])['InstanceStatuses'][0]['InstanceState']['Name'] if ec2_status == 'running': command = 'systemctl status amazon-cloudwatch-agent' print(f'Impacted Instance ID is : {instanceid}, Metric Name: {metric_name}') # Start a session print(f'Starting session to {instanceid}') response = ssm.send_command(InstanceIds = [instanceid], DocumentName="AWS-RunShellScript", Parameters={'commands': [command]}) command_id = response['Command']['CommandId'] print(f'Command ID: {command_id}') # Retrieve the command output time.sleep(4) output = ssm.get_command_invocation(CommandId=command_id, InstanceId=instanceid) print('Please find below output -n', output['StandardOutputContent']) mem_process_op = output['StandardOutputContent'] print(mem_process_op) else: mem_process_op = f'Instance current status is {ec2_status}. Not able to reach out!!' print(f'Instance current status is {ec2_status}. Not able to reach out!!') else: print('None')################## Create JIRA Issue #####################################################################def create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val): ## Create Issue ## url ='https://.atlassian.net//rest/api/2/issue' username = os.environ['username'] api_token = os.environ['token'] project = 'AnirbanSpace' issue_type = 'Incident' assignee = os.environ['username'] summ_metric = '%CPU Utilization' if 'CPU' in metric_name else '%Memory Utilization' if 'mem' in metric_name else '%Filesystem Utilization' if metric_name == 'disk_used_percent' else None metric_val = metric_val summary = f'Client | {account} | {instanceid} | {summ_metric} | Metric Value: {metric_val}' description = f'Client: CompanynAccount: {account}nRegion: {region}nInstanceID = {instanceid}nTimestamp = {timestamp}nCurrent State: {current_state}nPrevious State = {previous_state}nMetric Value = {metric_val}' issue_data = { "fields": { "project": { "key": "SCRUM" }, "summary": summary, "description": description, "issuetype": { "name": issue_type }, "assignee": { "name": assignee } } } data = json.dumps(issue_data) headers = { "Accept": "application/json", "Content-Type": "application/json" } auth = HTTPBasicAuth(username, api_token) response = requests.post(url, headers=headers, auth=auth, data=data) global issueid global issuekey global issuelink issueid = response.json().get('id') issuekey = response.json().get('key') issuelink = response.json().get('self') ################ Add Comment To Above Created JIRA Issue ################### output = cpu_process_op if metric_name == 'CPUUtilization' else mem_process_op if metric_name == 'mem_used_percent' else None comment_api_url = f"{url}/{issuekey}/comment" add_comment = requests.post(comment_api_url, headers=headers, auth=auth, data=json.dumps({"body": output})) ## Check the response if response.status_code == 201: print("Issue created successfully. Issue key:", response.json().get('key')) else: print(f"Failed to create issue. Status code: {response.status_code}, Response: {response.text}")################## Send An Email #################################################################def send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink): ### Define a dictionary of custom input ### metric_list = {'mem_used_percent': 'Memory', 'disk_used_percent': 'Disk', 'CPUUtilization': 'CPU'} ### Conditions ### if previous_state == 'OK' and current_state == 'INSUFFICIENT_DATA' and metric_name in list(metric_list.keys()): metric_msg = metric_list[metric_name] output = cpu_process_op if metric_name == 'CPUUtilization' else mem_process_op if metric_name == 'mem_used_percent' else None email_body = f"Hi Team, nnPlease be informed that {metric_msg} utilization alarm state has been changed to {current_state} for the instanceid {instanceid}. Please find below more information nnAlarm Details:nMetricName = {metric_name}, n Account = {account}, nTimestamp = {timestamp}, nRegion = {region}, nInstanceID = {instanceid}, nCurrentState = {current_state}, nReason = {current_reason}, nMetricValue = {metric_val}, nThreshold = 80.00 nnProcessOutput = n{output}nIncident Deatils:nIssueID = {issueid}, nIssueKey = {issuekey}, nLink = {issuelink}nnRegards,nAnirban Das,nGlobal Cloud Operations Team" res = sns_client.publish( TopicArn = os.environ['snsarn'], Subject = f'Insufficient {metric_msg} Utilization Alarm : {instanceid}', Message = str(email_body) ) print('Mail has been sent') if res else print('Email not sent') else: email_body = str(0)################## Lambda Handler Function ###########################################################################def lambda_handler(event, context): instanceid = event['detail']['configuration']['metrics'][0]['metricStat']['metric']['dimensions']['InstanceId'] metric_name = event['detail']['configuration']['metrics'][0]['metricStat']['metric']['name'] account = event['account'] timestamp = event['time'] region = event['region'] current_state = event['detail']['state']['value'] current_reason = event['detail']['state']['reason'] previous_state = event['detail']['previousState']['value'] previous_reason = event['detail']['previousState']['reason'] metric_val = 'NA' ##### function calling ##### if metric_name == 'CPUUtilization': cpu_utilization(instanceid, metric_name, previous_state, current_state) create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val) send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink) elif metric_name == 'mem_used_percent': mem_utilization(instanceid, metric_name, previous_state, current_state) create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val) send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink) else: None
数据不足邮件截图:
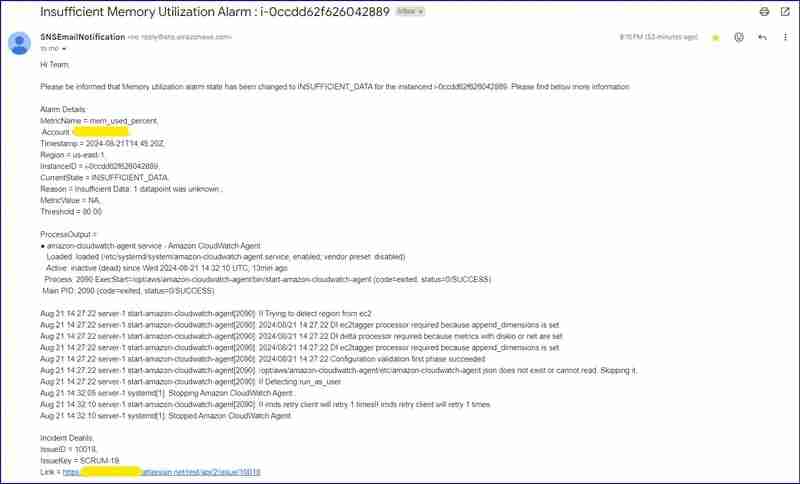
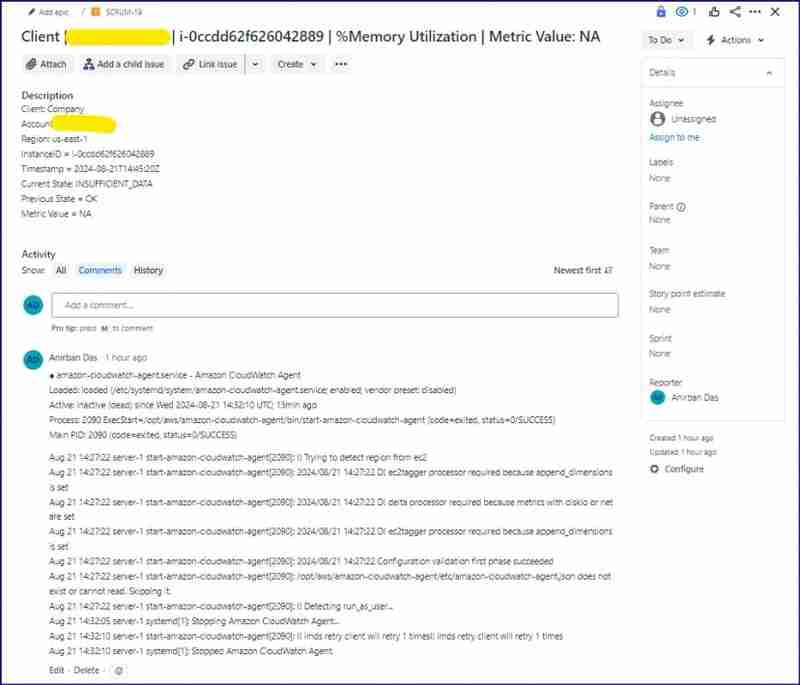
数据不足jira问题:
结论 :
在本文中,我们测试了有关 cpu 和内存利用率的场景,但是我们可以在很多指标上配置自动事件和自动电子邮件功能,这将减少监控和创建事件等方面的大量工作。 。该解决方案为我们提供了进一步推进的初步方法,但可以肯定的是,还可以有其他可能性来实现这一目标。我相信你们都会理解我们如何努力让这一切产生关联。如果您喜欢这篇文章或有任何其他建议,请点赞和评论,以便我们可以在接下来的文章中补充。 ??
谢谢!!
阿尼班·达斯
以上就是使用 EventBridge 和 Lambda 进行自动故障排除和 ITSM 系统的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1349426.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























