
作为一名学生,我亲眼目睹了我们大学低效的失物招领系统所带来的挫败感。目前的流程依赖于每个找到的物品的单独电子邮件,通常会导致丢失物品与其所有者之间的延误和错过联系。
出于为自己和同学改善这种体验的愿望,我开始了一个项目,探索深度学习在彻底改变我们的失物招领系统方面的潜力。 在这篇博文中,我将分享我评估预训练模型(resnet、efficientnet、vgg 和 nasnet)的旅程,以自动识别和分类丢失的物品。
通过比较分析,我的目标是找出最适合集成到我们系统中的模型,最终为校园里的每个人创造更快、更准确、用户友好的失物招领体验。
残差网络
inception-resnet v2 是 keras 中提供的强大的卷积神经网络架构,将 inception 架构的优势与 resnet 的残差连接相结合。这种混合模型旨在在保持计算效率的同时实现图像分类任务的高精度。
训练数据集:imagenet
图像格式:299 x 299
预处理功能
def readyforresnet(filename): pic = load_img(filename, target_size=(299, 299)) pic_array = img_to_array(pic) expanded = np.expand_dims(pic_array, axis=0) return preprocess_input_resnet(expanded)
预测
data1 = readyforresnet(test_file)prediction = inception_model_resnet.predict(data1)res1 = decode_predictions_resnet(prediction, top=2)
vgg(视觉几何组)
vgg(视觉几何组)是一系列深度卷积神经网络架构,以其在图像分类任务中的简单性和有效性而闻名。这些模型,特别是 vgg16 和 vgg19,由于在 2014 年 imagenet 大规模视觉识别挑战赛 (ilsvrc) 中的出色表现而受到欢迎。
训练数据集:imagenet
图像格式:224 x 224
预处理功能
def readyforvgg(filename): pic = load_img(filename, target_size=(224, 224)) pic_array = img_to_array(pic) expanded = np.expand_dims(pic_array, axis=0) return preprocess_input_vgg19(expanded)
预测
data2 = readyforvgg(test_file)prediction = inception_model_vgg19.predict(data2)res2 = decode_predictions_vgg19(prediction, top=2)
高效网络
efficientnet 是一系列卷积神经网络架构,可在图像分类任务上实现最先进的准确性,同时比以前的模型更小、速度更快。这种效率是通过平衡网络深度、宽度和分辨率的新型复合缩放方法来实现的。
训练数据集:imagenet
图像格式:480 x 480
预处理功能
def readyforef(filename): pic = load_img(filename, target_size=(480, 480)) pic_array = img_to_array(pic) expanded = np.expand_dims(pic_array, axis=0) return preprocess_input_ef(expanded)
预测
data3 = readyforef(test_file)prediction = inception_model_ef.predict(data3)res3 = decode_predictions_ef(prediction, top=2)
纳斯网络
nasnet(神经架构搜索网络)代表了深度学习中的一种突破性方法,其中神经网络本身的架构是通过自动搜索过程发现的。此搜索过程旨在找到层和连接的最佳组合,以在给定任务上实现高性能。
训练数据集:imagenet
图像格式:224 x 224
预处理功能
def readyfornn(filename): pic = load_img(filename, target_size=(224, 224)) pic_array = img_to_array(pic) expanded = np.expand_dims(pic_array, axis=0) return preprocess_input_nn(expanded)
预测
data4 = readyForNN(test_file)prediction = inception_model_NN.predict(data4)res4 = decode_predictions_NN(prediction, top=2)
摊牌
准确性
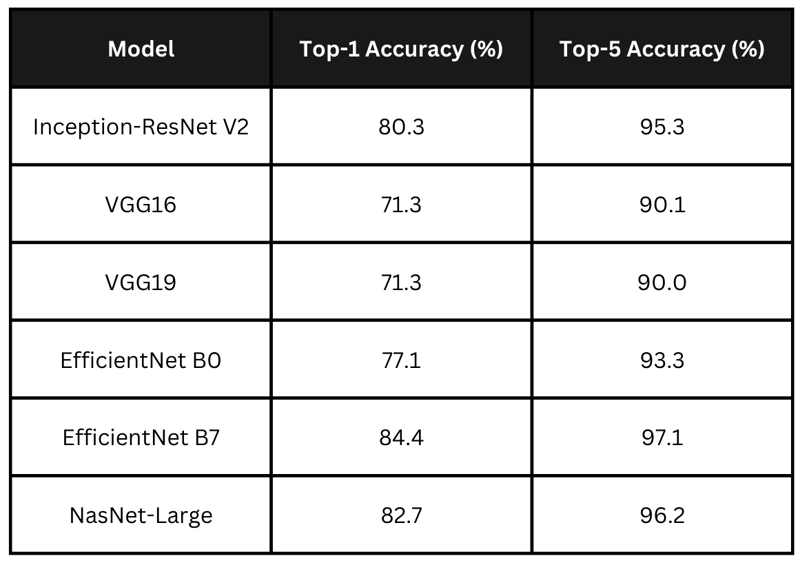
该表总结了上述模型声称的准确性分数。 efficientnet b7 以最高的准确率领先,紧随其后的是 nasnet-large 和 inception-resnet v2。 vgg 模型的精度较低。对于我的应用程序,我想选择一个在处理时间和准确性之间取得平衡的模型。
时间
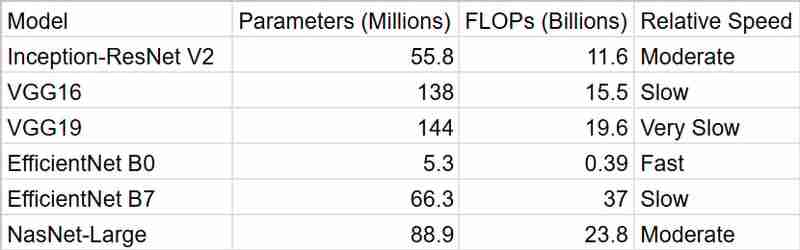
正如我们所见,efficientnetb0 为我们提供了最快的结果,但是考虑到准确性,inceptionresnetv2 是一个更好的包
概括
对于我的智能失物招领系统,我决定使用 inceptionresnetv2。虽然 efficientnet b7 以其一流的准确性看起来很诱人,但我担心它的计算需求。在大学环境中,资源可能有限,而实时性能往往是可取的,我认为在准确性和效率之间取得平衡很重要。 inceptionresnetv2 似乎是完美的选择 – 它提供了强大的性能,而又不会过度计算密集。
此外,它在 imagenet 上进行预训练的事实让我相信它可以处理人们可能丢失的各种物体。我们不要忘记在 keras 中使用是多么容易!这绝对让我的决定更容易。
总的来说,我相信 inceptionresnetv2 为我的项目提供了准确性、效率和实用性的正确组合。我很高兴看到它如何帮助丢失的物品与失主重新团聚!
以上就是ResNet、EfficientNet、VGG、NN的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1349458.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















