
提交问题
对于我的第一个贡献,我提交了一个问题以向另一个项目添加新功能,即添加一个新的标志选项来显示用于提示和完成生成的令牌。
 功能:聊天完成令牌信息标志选项 #8
功能:聊天完成令牌信息标志选项 #8

描述
一个标志选项,为用户提供发送和接收的令牌计数。我认为这是一个重要的功能,可以引导用户在发出聊天完成请求时保持在代币预算之内!
实施
为此,我们需要添加另一个选项标志,可以是 -t 和 –token-usage。当用户在命令中包含此标志时,它应该清楚地详细显示在生成完成过程中使用了多少个令牌,以及在提示中使用了多少个令牌。
我选择为 fadingna 的开源项目 chat-minal 做出贡献,这是一个用 python 编写的 cli 工具,允许您利用 openai 来做各种事情,例如使用它生成代码审查、文件转换、从文本和摘要文本。
我的拉取请求
我以前用python写过代码,但这不是我最强的技能。因此,为这个项目做出贡献为我提供了具有挑战性但良好的学习经历。
挑战在于我必须阅读和理解别人的代码,并以不破坏代码设计的方式提供正确的解决方案。理解流程至关重要,这样我就可以高效地添加功能,而无需对代码进行大的更改并保持代码一致。
feat:代币使用标志 #9
功能
添加了为用户添加 –token_usage 标志选项的功能。此选项向用户提供用于提示和生成完成的令牌数量的信息。
实施
我根据代码设计提出的解决方案是检查 token_usage 标志是否存在。如果未使用 token_usage 标志,我不希望代码检查任何不必要的 if 语句,因此我制作了两个单独的相同循环逻辑,不同之处在于检查块内是否存在 use_metadata。
if token_usage: for chunk in runnable.stream({"input_text": input_text}): print(chunk.content, end="", flush=true) answer.append(chunk.content) if chunk.usage_metadata: completion_tokens = chunk.usage_metadata.get('output_tokens') prompt_tokens = chunk.usage_metadata.get('input_tokens')else: for chunk in runnable.stream({"input_text": input_text}): print(chunk.content, end="", flush=true) answer.append(chunk.content)
显示
在 get_completions() 方法执行结束时,添加对标记 token_usage 的检查,然后如果使用了该标记,则将令牌使用详细信息显示到 stderr。
if token_usage: logger.error(f"tokens used for completion: {completion_tokens}") logger.error(f"tokens used for prompt: {prompt_tokens}")
我的解决方案
检索令牌使用情况
if token_usage: for chunk in runnable.stream({"input_text": input_text}): print(chunk.content, end="", flush=true) answer.append(chunk.content) if chunk.usage_metadata: completion_tokens = chunk.usage_metadata.get('output_tokens') prompt_tokens = chunk.usage_metadata.get('input_tokens')else: for chunk in runnable.stream({"input_text": input_text}): print(chunk.content, end="", flush=true) answer.append(chunk.content)
最初,代码只有一个 for 循环,它从流中检索内容并将其附加到一个数组,该数组形成完成的响应。
我为什么要这样写呢?
我在添加不同的 if 块时复制 for 的原因是为了防止代码重复检查 if 块,即使用户没有使用新添加的 –token_usage 标志。因此,我首先检查该标志是否存在,然后决定执行哪个 for 循环。
实现
尽管我的拉取请求已被项目所有者接受,但我后来意识到这种方式增加了代码可维护性的复杂性。例如,如果处理流的 for 循环中需要进行更改,则意味着需要修改代码两次,因为有两个相同的 for 循环。
我认为我可以做的改进就是将其变成一个函数,这样任何需要的更改都可以在一个函数中完成,保持代码的可维护性。这只是证明,即使我在编写代码时考虑到了优化,我仍然可能会错过其他对项目至关重要的东西,在本例中就是可维护性。
收到拉取请求
我的工具genereadme也收到了贡献。我收到了 mounayer 的 pr,旨在将相同的功能添加到我的项目中。
壮举:添加了一个新标志,显示提示中发送的令牌数和完成时收到的令牌数 #13

描述
关闭#12。
添加了一个新标志 –token-usage,指定该标志后,会打印提示中发送的令牌数量以及完成时返回到 `stderr 的令牌数量。
这只需要添加另一个标志检查 –token-usage:
.option("--token-usage", "show prompt and completion token usage")
我还确保保持命名约定/格式风格一致,在为每个处理的文件完成聊天完成的 for 循环中,我累计了发送和接收的总令牌:
prompttokens += response.usage.prompt_tokens; completiontokens += response.usage.completion_tokens;
如果这样提供 –token-usage 标志,我会在程序运行时结束时显示它:
if (program.opts().tokenusage) { console.error(`prompt tokens: ${prompttokens}`); console.error(`completion tokens: ${completiontokens}`); }
更新了 readme.md 以解释新标志。
测试
测试 1
genereadme examples/sum.js --token-usage
这应该显示类似:
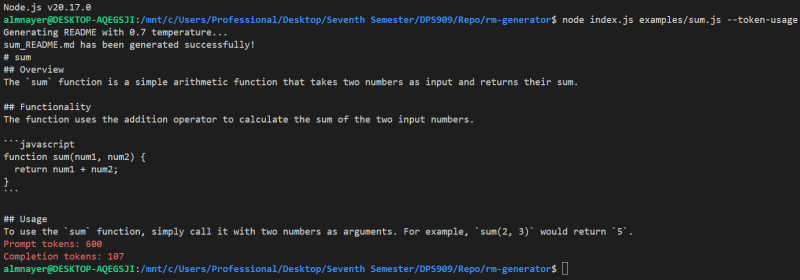
测试2
您也可以尝试使用多个文件,即:
genereadme examples/sum.js examples/createUser.js --token-usage
这一次,不必阅读别人的代码,而是必须有人阅读我的代码并为其做出贡献。很高兴知道有人能够为我的项目做出贡献。对我来说,这意味着他们了解我的代码是如何工作的,因此他们能够添加该功能,而不会破坏任何内容或增加代码库的任何复杂性。
话虽如此,阅读代码也是一项不可低估的技能。我的代码还远未达到完美,我知道还有一些地方可以改进,所以功劳也归功于能够阅读和理解代码。
这个特定的拉取请求实际上不需要任何来回更改,因为 mounayer 编写的代码就是我自己编写的。
以上就是我的第一个开源贡献的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1349810.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




























