
在开发打算由外部代码导入的 python 模块时,确保此类导入符合特定要求至关重要。未能正确管理导入可能会导致冲突、错误以及开发和维护方面的重大挑战。 importspy 是一个功能强大的 python 库,允许开发人员主动管理导入,确保外部模块遵守代码所需的预定义结构和规则。
参考架构
要了解利用 importspy 确保正确控制导入的项目的最小架构,请参考下图:
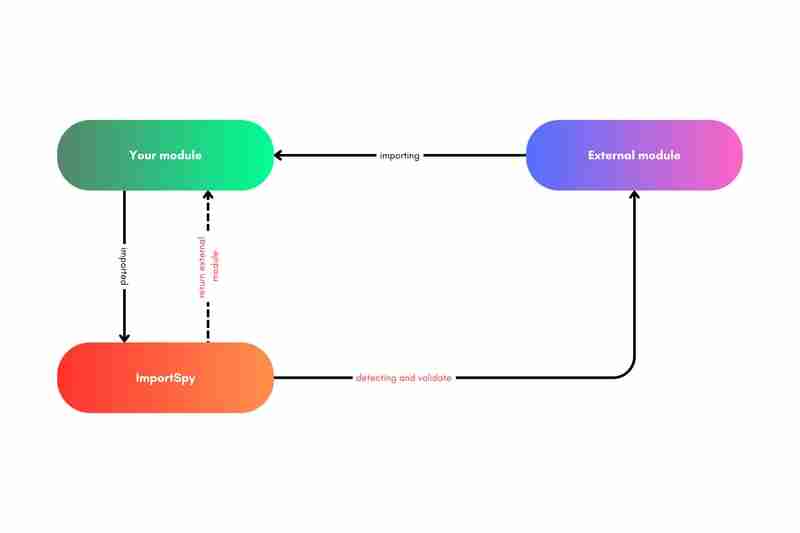
此图说明了当外部模块尝试导入您的模块并接受 importspy 验证时所涉及的关键组件和交互:
1.您的模块:这代表您开发的代码,将由外部模块导入。该模块受到 importspy 的“保护”,以确保正确使用。
2.外部模块:这是尝试导入模块以使用其功能的外部代码。外部模块必须遵守一定的结构规则才能成功完成导入过程。
3.importspy:作为代码的守护者,importspy 拦截导入尝试并检查外部模块是否遵循开发人员指定的规则(使用 spymodel)。如果外部模块不符合要求,导入将被阻止。
通过执行这些规则,importspy 降低了冲突、不当使用以及因导入结构不正确的代码而产生的错误的风险。
立即学习“Python免费学习笔记(深入)”;
进口流程
图中描述的过程遵循以下步骤:
导入尝试:外部模块尝试导入您的模块。拦截和验证:importspy 立即拦截导入过程,检查外部模块是否符合所有定义的规则。这些规则可能包括特定变量、函数和类的存在,它们是根据使用 spymodel 创建的验证模型构建的。批准或拒绝:如果外部模块满足要求,则导入成功,并且该模块已集成到项目中。如果失败,importspy 会阻止导入 并返回一个错误,突出显示不合规情况。
importspy 的工作原理
importspy 允许开发人员定义外部模块必须遵循的清晰且严格的结构才能使用其功能。使用 spymodel 类,开发人员可以指定:
必需变量:必须在外部模块中定义的变量。必要功能:导入模块必须实现的功能。类和方法:外部模块中必须存在的必需类及其方法。
子集逻辑和 spymodel 验证
当外部模块尝试导入您的代码时,importspy 会将导入的模块与开发人员使用 spymodel 定义的结构进行比较和验证。验证过程如下:
模型定义:开发人员使用 spymodel 定义验证模型,指定所需的变量、函数和类。该模型充当外部模块必须遵循的一组规则。一致性检查:importspy 在将外部模块与验证模型进行比较时应用子集逻辑。它检查导入的模块是否包含 spymodel 中定义的所有必需元素(变量、函数、类)。错误处理:如果导入的模块缺少任何必需的元素或包含结构差异,importspy 会引发错误,从而阻止导入。这确保了代码的正确使用,减少了冲突和不可预见行为的风险。
importspy 的主要特点
分析 importspy 的 github 存储库中的代码揭示了一些基本功能:
主动验证:spymodel 类不仅允许开发人员为新模块定义规则,还可以追溯验证现有代码。这对于在初始开发期间可能未考虑验证的遗留项目特别有用。依赖关系检测:importspy 自动检查导入模块是否遵循预定义的结构,包括文件名、版本、函数和类。这有助于维护项目中依赖关系的完整性。插件隔离:importspy 在基于插件的架构中特别有用,其中模块必须在集成之前进行隔离和验证。这确保了整个系统保持模块化和稳定。
importspy 入门
importspy 入门很简单,可以通过 pip 完成:
pip install importspy
安装后,开发人员可以在其代码中配置 importspy,以使用 spymodel 类.
定义必要的导入规则
使用示例
下面是一个使用示例,演示如何使用 importspy 来验证导入的模块。它包括主模块和外部模块的代码,必须遵守开发人员设定的规则。
主模块代码:your_code.py
from importspy import spyfrom importspy.models import spymodel, classmodelfrom typing import list# define the rules for the structure and usage of your python code by external modulesclass mylibraryspy(spymodel): # list of required variables that must be present in the importing module variables: list[str] = ["required_var1", "required_var2"] # list of required functions that must be defined in the importing module functions: list[str] = ["required_function"] # define the required classes, their attributes, and methods classes: list[classmodel] = [ classmodel( name="myrequiredclass", class_attr=["attr_1", "attr_2"], # class-level attributes instance_attr=["attr_3"], # instance-level attributes methods=["required_method1", "required_method2"] # required methods ) ]# use importspy to check if the importing module complies with the defined rulesmodule = spy().importspy(spymodel=mylibraryspy)if module: print(f"module '{module.__name__}' complies with the specified rules and is ready to use!")else: print("the importing module does not comply with the required structure.")
在本模块中,我们定义了所需变量、函数和类结构的规则。 importspy 确保导入模块遵守这些规则。
外部模块代码:importing_module.py
import your_code# Define the required variables at the module levelrequired_var1 = "Value for required_var1"required_var2 = "Value for required_var2"# Define the required class as per the validation modelclass MyRequiredClass: # Class-level attributes attr_1 = "Class attribute 1" attr_2 = "Class attribute 2" # Instance-level attributes def __init__(self): self.attr_3 = "Instance attribute" # Implement the required methods def required_method1(self): print("Method 1 implemented") def required_method2(self): print("Method 2 implemented")# Define the required functiondef required_function(): print("Required function implemented")
在此外部模块中,我们定义变量 required_var1 和 required_var2,以及类 myrequiredclass 和函数 required_function。该结构遵循主模块设定的规则,确保集成顺利、合规。
主动验证的工作原理
要启用主动验证,外部模块(导入您的代码)必须遵循开发人员使用 importspy 定义的结构。验证过程如下:
定义规则:开发人员使用 importspy 定义一个模型 (spymodel),概述外部模块的预期结构和行为。导入外部模块:当外部模块尝试导入开发人员的代码时,importspy 会检查导入的模块是否符合预定义的规则,例如是否存在特定变量、函数或类。验证结果:如果导入的模块符合要求,则验证成功,导入顺利进行。否则,importspy 会引发指示不合规的错误,帮助开发人员避免运行时问题并确保他们的代码正确集成到外部项目中。
结论
importspy 是确保外部模块正确使用您的 python 代码的重要工具,特别是在多个团队可能处理不同模块的大型项目或敏捷开发环境中。通过定义和执行导入规则,importspy 有助于防止错误并提高软件质量,确保您的代码安全一致地集成。
实时监控导入的能力,加上主动验证依赖项,使 importspy 成为现代 python 开发的宝贵资产。实现这个库可以让开发人员相信他们的代码将按预期使用,从而最大限度地减少错误和冲突的风险。
有关更多详细信息和资源,您可以访问 github 上的 importspy 存储库、pypi 包页面和官方文档。
以上就是在 Python 中管理导入:使用 ImportSpy 主动验证的重要性的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1351026.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




























