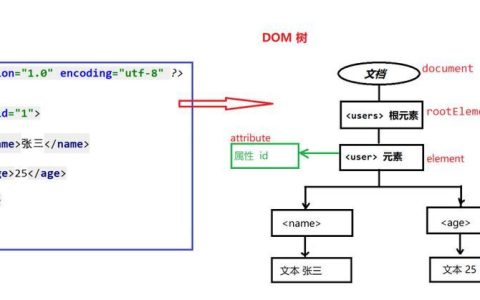
使用beautifulsoup的find_all提取包含回车符的列表元素
问题场景:使用beautifulsoup从指定页面的标签中提取’green’类元素,但提取结果中存在回车符,导致元素被分割为多个。
解决方案:
使用.get_text()方法可以获取标签中去除回车符的文本内容。要在保持.get_text()方法可用性的前提下去除回车符,可以使用replace()函数替换回车符:
for name in name_list: print(name.get_text().replace('n', ''))
这样,anna pavlovna 和 scherer将被正确识别为单个元素,因为回车符已去除。
以上就是BeautifulSoup提取包含回车符的span标签文本:如何避免元素被分割?的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1353700.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫