
抓取 google 搜索可提供基本的 serp 分析、seo 优化和数据收集功能。现代抓取工具使这个过程更快、更可靠。
我们的一位社区成员撰写了此博客,作为对 crawlee 博客的贡献。如果您想向 crawlee 博客贡献此类博客,请通过我们的 discord 频道与我们联系。
在本指南中,我们将使用 crawlee for python 创建一个 google 搜索抓取工具,可以处理结果排名和分页。
我们将创建一个抓取工具:
从搜索结果中提取标题、url 和描述处理多个搜索查询追踪排名位置处理多个结果页面以结构化格式保存数据
先决条件
python 3.7 或更高版本对 html 和 css 选择器的基本了解熟悉网络抓取概念crawlee for python v0.4.2 或更高版本
项目设置
安装 crawlee 所需的依赖项:
pipx install crawlee[beautifulsoup,curl-impersonate]
使用 crawlee cli 创建一个新项目:
pipx run crawlee create crawlee-google-search
出现提示时,选择 beautifulsoup 作为您的模板类型。
立即学习“Python免费学习笔记(深入)”;
导航到项目目录并完成安装:
cd crawlee-google-searchpoetry install
使用 python 开发 google 搜索抓取工具
1. 定义提取数据
首先,让我们定义提取范围。谷歌的搜索结果现在包括地图、名人、公司详细信息、视频、常见问题和许多其他元素。我们将重点分析带有排名的标准搜索结果。
这是我们要提取的内容:
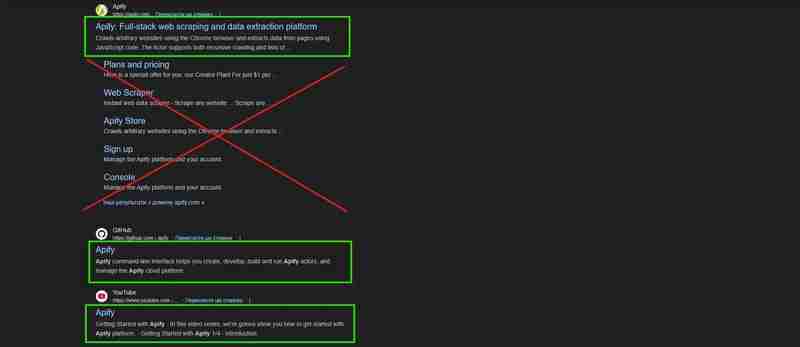
我们来验证一下是否可以从页面的html代码中提取必要的数据,或者是否需要更深入的分析或js渲染。请注意,此验证对 html 标签敏感:
根据从页面获取的数据,所有必要的信息都存在于 html 代码中。因此,我们可以使用beautifulsoup_crawler。
我们将提取的字段:
搜索结果标题网址描述文字排名位置
2.配置爬虫
首先,让我们创建爬虫配置。
我们将使用 curlimpersonatehttpclient 作为带有预设标头的 http_client,并模拟与 chrome 浏览器相关的内容。
我们还将配置 concurrencysettings 来控制抓取攻击性。这对于避免被 google 屏蔽至关重要。
如果您需要更集中地提取数据,请考虑设置proxyconfiguration。
from crawlee.beautifulsoup_crawler import beautifulsoupcrawlerfrom crawlee.http_clients.curl_impersonate import curlimpersonatehttpclientfrom crawlee import concurrencysettings, httpheadersasync def main() -> none: concurrency_settings = concurrencysettings(max_concurrency=5, max_tasks_per_minute=200) http_client = curlimpersonatehttpclient(impersonate="chrome124", headers=httpheaders({"referer": "https://www.google.com/", "accept-language": "en", "accept-encoding": "gzip, deflate, br, zstd", "user-agent": "mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/131.0.0.0 safari/537.36" })) crawler = beautifulsoupcrawler( max_request_retries=1, concurrency_settings=concurrency_settings, http_client=http_client, max_requests_per_crawl=10, max_crawl_depth=5 ) await crawler.run(['https://www.google.com/search?q=apify'])
3. 实现数据提取
首先我们来分析一下需要提取的元素的html代码:
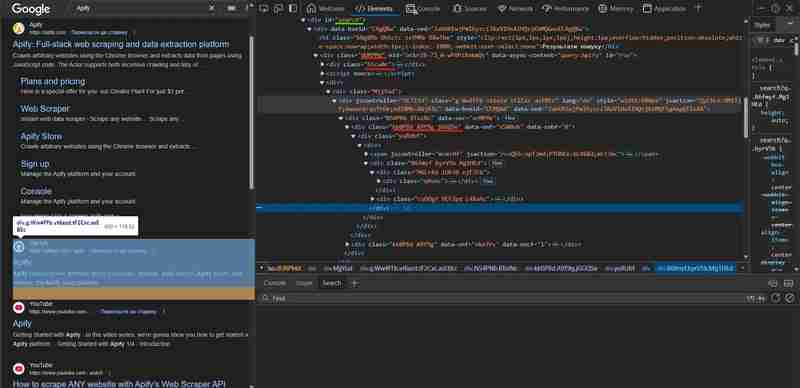
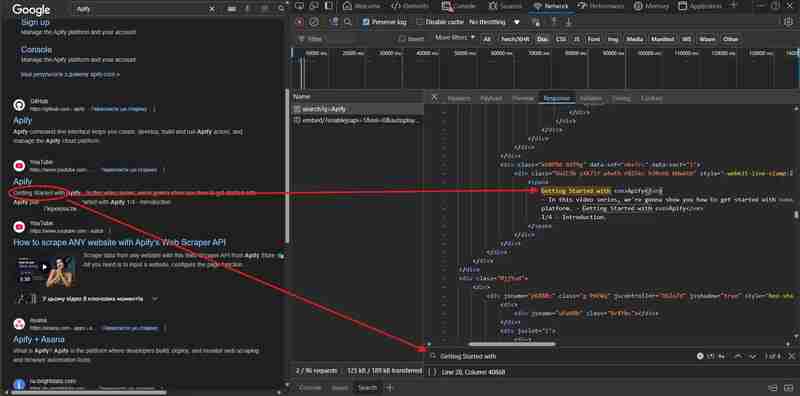
可读 id 属性和生成 类名和其他属性之间存在明显区别。创建用于数据提取的选择器时,您应该忽略任何生成的属性。即使您已经了解到 google 已经使用特定的生成标签 n 年了,您也不应该依赖它 – 这反映了您编写健壮代码的经验。
现在我们了解了 html 结构,让我们来实现提取。由于我们的爬虫只处理一种类型的页面,因此我们可以使用 router.default_handler 来处理它。在处理程序中,我们将使用 beautifulsoup 迭代每个搜索结果,在保存结果时提取标题、url 和 text_widget 等数据。
@crawler.router.default_handlerasync def default_handler(context: beautifulsoupcrawlingcontext) -> none: """default request handler.""" context.log.info(f'processing {context.request} ...') for item in context.soup.select("div#search div#rso div[data-hveid][lang]"): data = { 'title': item.select_one("h3").get_text(), "url": item.select_one("a").get("href"), "text_widget": item.select_one("div[style*='line']").get_text(), } await context.push_data(data)
4. 处理分页
由于 google 结果取决于搜索请求的 ip 地理位置,因此我们不能依赖链接文本进行分页。我们需要创建一个更复杂的 css 选择器,无论地理位置和语言设置如何,它都可以工作。
max_crawl_depth 参数控制我们的爬虫应该扫描多少页面。一旦我们有了强大的选择器,我们只需获取下一页链接并将其添加到爬虫队列中即可。
要编写更高效的选择器,请学习 css 和 xpath 语法的基础知识。
await context.enqueue_links(selector="div[role='navigation'] td[role='heading']:last-of-type > a")
5. 将数据导出为csv格式
由于我们希望以方便的表格格式(例如 csv)保存所有搜索结果数据,因此我们可以在运行爬虫后立即添加 export_data 方法调用:
await crawler.export_data_csv("google_search.csv")
6. 完成 google 搜索抓取工具
虽然我们的核心爬虫逻辑有效,但您可能已经注意到我们的结果目前缺乏排名位置信息。为了完成我们的抓取工具,我们需要通过使用请求中的 user_data 在请求之间传递数据来实现正确的排名位置跟踪。
让我们修改脚本来处理多个查询并跟踪搜索结果分析的排名位置。我们还将爬行深度设置为顶级变量。让我们将 router.default_handler 移至 paths.py 以匹配项目结构:
# crawlee-google-search.mainfrom crawlee.beautifulsoup_crawler import beautifulsoupcrawler, beautifulsoupcrawlingcontextfrom crawlee.http_clients.curl_impersonate import curlimpersonatehttpclientfrom crawlee import request, concurrencysettings, httpheadersfrom .routes import routerqueries = ["apify", "crawlee"]crawl_depth = 2async def main() -> none: """the crawler entry point.""" concurrency_settings = concurrencysettings(max_concurrency=5, max_tasks_per_minute=200) http_client = curlimpersonatehttpclient(impersonate="chrome124", headers=httpheaders({"referer": "https://www.google.com/", "accept-language": "en", "accept-encoding": "gzip, deflate, br, zstd", "user-agent": "mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/131.0.0.0 safari/537.36" })) crawler = beautifulsoupcrawler( request_handler=router, max_request_retries=1, concurrency_settings=concurrency_settings, http_client=http_client, max_requests_per_crawl=100, max_crawl_depth=crawl_depth ) requests_lists = [request.from_url(f"https://www.google.com/search?q={query}", user_data = {"query": query}) for query in queries] await crawler.run(requests_lists) await crawler.export_data_csv("google_ranked.csv")
我们还可以修改处理程序以添加 query 和 order_no 字段以及基本错误处理:
# crawlee-google-search.routesfrom crawlee.beautifulsoup_crawler import BeautifulSoupCrawlingContextfrom crawlee.router import Routerrouter = Router[BeautifulSoupCrawlingContext]()@router.default_handlerasync def default_handler(context: BeautifulSoupCrawlingContext) -> None: """Default request handler.""" context.log.info(f'Processing {context.request.url} ...') order = context.request.user_data.get("last_order", 1) query = context.request.user_data.get("query") for item in context.soup.select("div#search div#rso div[data-hveid][lang]"): try: data = { "query": query, "order_no": order, 'title': item.select_one("h3").get_text(), "url": item.select_one("a").get("href"), "text_widget": item.select_one("div[style*='line']").get_text(), } await context.push_data(data) order += 1 except AttributeError as e: context.log.warning(f'Attribute error for query "{query}": {str(e)}') except Exception as e: context.log.error(f'Unexpected error for query "{query}": {str(e)}') await context.enqueue_links(selector="div[role='navigation'] td[role='heading']:last-of-type > a", user_data={"last_order": order, "query": query})
我们就完成了!
我们的 google 搜索抓取工具已准备就绪。我们来看看 google_ranked.csv 文件中的结果:
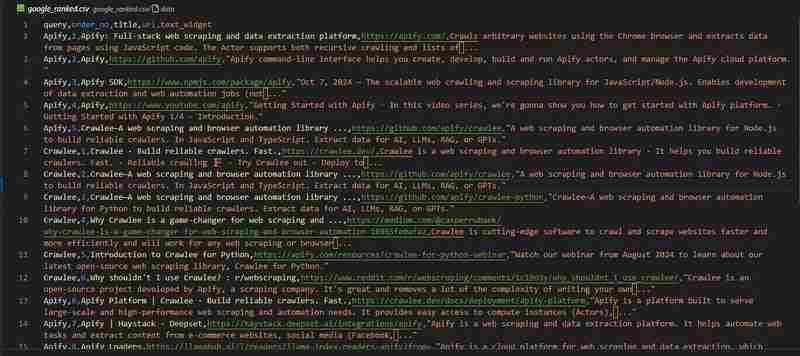
代码存储库可在 github 上获取
使用 apify 抓取 google 搜索结果
如果您正在从事需要数百万个数据点的大型项目,例如本文中有关 google 排名分析的项目 – 您可能需要一个现成的解决方案。
考虑使用 apify 团队开发的 google 搜索结果抓取器。
它提供了重要的功能,例如:
代理支持大规模数据提取的可扩展性地理位置控制与 zapier、make、airbyte、langchain 等外部服务集成
您可以在 apify 博客中了解更多信息
你会刮什么?
在本博客中,我们逐步探索了如何创建收集排名数据的 google 搜索抓取工具。如何分析此数据集取决于您!
温馨提示,您可以在 github 上找到完整的项目代码。
我想 5 年后我需要写一篇关于“如何从 llm 的最佳搜索引擎中提取数据”的文章,但我怀疑 5 年后这篇文章仍然具有相关性。
以上就是如何使用 Python 抓取 Google 搜索结果的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1354559.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


























