
请我喝杯咖啡☕
*我的帖子解释了加州理工学院 101。
caltech101()可以使用caltech 101数据集,如下所示:
*备忘录:
第一个参数是 root(必需类型:str 或 pathlib.path)。 *绝对或相对路径都是可能的。第二个参数是 target_type(可选-默认:“category”-类型:str 或元组或 str 列表)。 *可以为其设置“类别”和/或“注释”。第三个参数是transform(optional-default:none-type:callable)。第四个参数是 target_transform(optional-default:none-type:callable)。第五个参数是 download(optional-default:false-type:bool):*备注:如果为 true,则从互联网下载数据集并解压(解压)到根目录。如果为 true 并且数据集已下载,则将其提取。如果为 true 并且数据集已下载并提取,则不会发生任何事情。如果数据集已经下载并提取,则应该为 false,因为它速度更快。您可以从此处手动下载并提取数据集(101_objectcategories.tar.gz 和 annotations.tar)到 data/caltech101/。关于图像索引的类别,faces(0) 为 0~434,faces_easy(1) 为 435~869,豹子(2 )为870~1069, 摩托车(3)是1070~1867,手风琴(4)是1868~1922,飞机(5)是1923~2722,锚(6) 是2723~2764,蚂蚁(7)为2765~2806,桶(8)为2807~2853,低音(9)为2854~2907等。
from torchvision.datasets import Caltech101category_data = Caltech101( root="data")category_data = Caltech101( root="data", target_type="category", transform=None, target_transform=None, download=False)annotation_data = Caltech101( root="data", target_type="annotation")all_data = Caltech101( root="data", target_type=["category", "annotation"])len(category_data), len(annotation_data), len(all_data)# (8677, 8677, 8677)category_data# Dataset Caltech101# Number of datapoints: 8677# Root location: datacaltech101# Target type: ['category']category_data.root# 'data/caltech101'category_data.target_type# ['category']print(category_data.transform)# Noneprint(category_data.target_transform)# Nonecategory_data.download# len(category_data.categories)# 101category_data.categories# ['Faces', 'Faces_easy', 'Leopards', 'Motorbikes', 'accordion', # 'airplanes', 'anchor', 'ant', 'barrel', 'bass', 'beaver',# 'binocular', 'bonsai', 'brain', 'brontosaurus', 'buddha',# 'butterfly', 'camera', 'cannon', 'car_side', 'ceiling_fan',# 'cellphone', 'chair', 'chandelier', 'cougar_body', 'cougar_face', ...]len(category_data.annotation_categories)# 101category_data.annotation_categories# ['Faces_2', 'Faces_3', 'Leopards', 'Motorbikes_16', 'accordion',# 'Airplanes_Side_2', 'anchor', 'ant', 'barrel', 'bass',# 'beaver', 'binocular', 'bonsai', 'brain', 'brontosaurus',# 'buddha', 'butterfly', 'camera', 'cannon', 'car_side',# 'ceiling_fan', 'cellphone', 'chair', 'chandelier', 'cougar_body', ...]category_data[0]# (, 0)category_data[1]# (, 0)category_data[2]# (, 0)category_data[435]# (, 1)category_data[870]# (, 2)annotation_data[0]# (,# array([[10.00958466, 8.18210863, 8.18210863, 10.92332268, ...],# [132.30670927, 120.42811502, 103.52396166, 90.73162939, ...]]))annotation_data[1]# (,# array([[15.19298246, 13.71929825, 15.19298246, 19.61403509, ...],# [121.5877193, 103.90350877, 80.81578947, 64.11403509, ...]]))annotation_data[2]# (,# array([[10.40789474, 7.17807018, 5.79385965, 9.02368421, ...],# [131.30789474, 120.69561404, 102.23947368, 86.09035088, ...]]))annotation_data[435]# (,# array([[64.52631579, 95.31578947, 123.26315789, 149.31578947, ...],# [15.42105263, 8.31578947, 10.21052632, 28.21052632, ...]]))annotation_data[870]# (,# array([[2.96536524, 7.55604534, 19.45780856, 33.73992443, ...],# [23.63413098, 32.13539043, 33.83564232, 8.84193955, ...]]))all_data[0]# (,# (0, array([[10.00958466, 8.18210863, 8.18210863, 10.92332268, ...],# [132.30670927, 120.42811502, 103.52396166, 90.73162939, ...]]))all_data[1]# (,# (0, array([[15.19298246, 13.71929825, 15.19298246, 19.61403509, ...],# [121.5877193, 103.90350877, 80.81578947, 64.11403509, ...]]))all_data[2]# (,# (0, array([[10.40789474, 7.17807018, 5.79385965, 9.02368421, ...],# [131.30789474, 120.69561404, 102.23947368, 86.09035088, ...]]))all_data[3]# (,# (0, array([[19.54035088, 18.57894737, 26.27017544, 38.2877193, ...],# [131.49122807, 100.24561404, 74.2877193, 49.29122807, ...]]))all_data[4]# (,# (0, array([[11.87982456, 11.87982456, 13.86578947, 15.35526316, ...],# [128.34649123, 105.50789474, 91.60614035, 76.71140351, ...]]))import matplotlib.pyplot as pltdef show_images(data, main_title=None): plt.figure(figsize=(10, 5)) plt.suptitle(t=main_title, y=1.0, fontsize=14) ims = (0, 1, 2, 435, 870, 1070, 1868, 1923, 2723, 2765, 2807, 2854) for i, j in enumerate(ims, start=1): plt.subplot(2, 5, i) if len(data.target_type) == 1: if data.target_type[0] == "category": im, lab = data[j] plt.title(label=lab) elif data.target_type[0] == "annotation": im, (px, py) = data[j] plt.scatter(x=px, y=py) plt.imshow(X=im) elif len(data.target_type) == 2: if data.target_type[0] == "category": im, (lab, (px, py)) = data[j] elif data.target_type[0] == "annotation": im, ((px, py), lab) = data[j] plt.title(label=lab) plt.imshow(X=im) plt.scatter(x=px, y=py) if i == 10: break plt.tight_layout() plt.show()show_images(data=category_data, main_title="category_data")show_images(data=annotation_data, main_title="annotation_data")show_images(data=all_data, main_title="all_data")
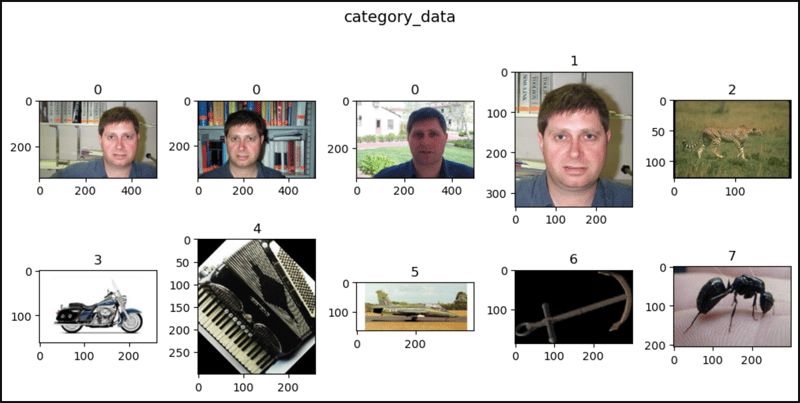
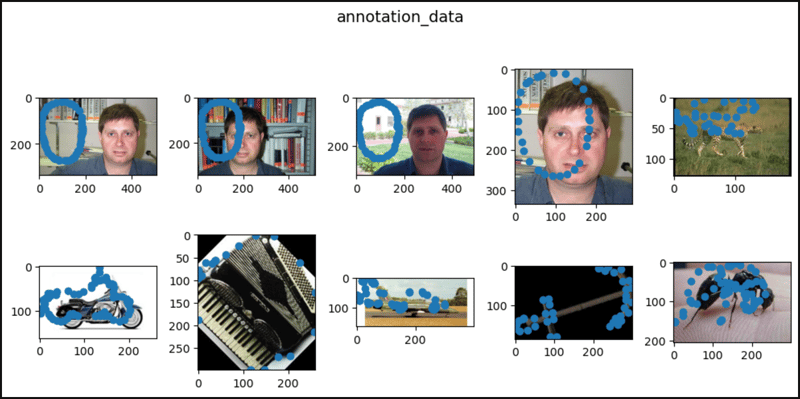
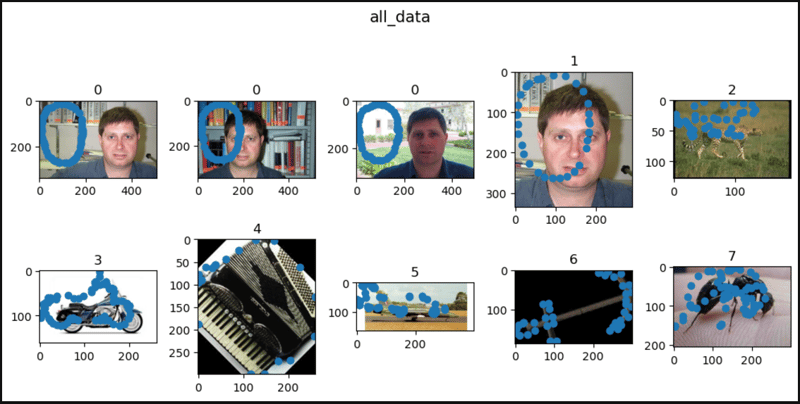
以上就是PyTorch 中的加州理工学院的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1354771.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




























