
请我喝杯咖啡☕
*我的帖子解释了 celeba。
celeba() 可以使用 celeba 数据集,如下所示:
*备忘录:
第一个参数是 root(必需类型:str 或 pathlib.path)。 *绝对或相对路径都是可能的。第二个参数是 split(可选-默认:”train”-类型:str)。 *可以设置“train”(162,770张图片)、“valid”(19,867张图片)、“test”(19,962张图片)或“all”(202,599张图片)。第三个参数是target_type(可选-默认:“attr”-类型:str或str列表):*备注:可以为其设置“attr”、“identity”、“bbox”和/或“landmark”。也可以设置空列表。可以设置多个相同的值。如果值的顺序不同,则其元素的顺序也会不同。第四个参数是transform(optional-default:none-type:callable)。第 5 个参数是 target_transform(optional-default:none-type:callable)。第 6 个参数是 download(可选-默认:false-类型:bool):*备注:如果为 true,则从互联网下载数据集并解压(解压)到根目录。如果为 true 并且数据集已下载,则将其提取。如果为 true 并且数据集已下载并提取,则不会发生任何事情。如果数据集已经下载并提取,则应该为 false,因为它速度更快。下载数据集需要 gdown。 您可以从这里手动下载并解压数据集(img_align_celeba.zip with identity_celeba.txt、list_attr_celeba.txt、list_bbox_celeba.txt、list_eval_partition.txt 和 list_landmarks_align_celeba.txt)到 data/celeba/。
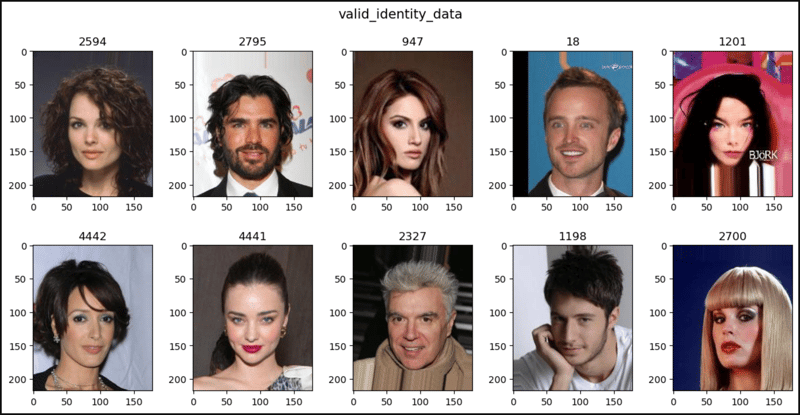
from torchvision.datasets import CelebAtrain_attr_data = CelebA( root="data")train_attr_data = CelebA( root="data", split="train", target_type="attr", transform=None, target_transform=None, download=False)valid_identity_data = CelebA( root="data", split="valid", target_type="identity")test_bbox_data = CelebA( root="data", split="test", target_type="bbox")all_landmarks_data = CelebA( root="data", split="all", target_type="landmarks")all_empty_data = CelebA( root="data", split="all", target_type=[])all_all_data = CelebA( root="data", split="all", target_type=["attr", "identity", "bbox", "landmarks"])len(train_attr_data), len(valid_identity_data), len(test_bbox_data)# (162770, 19867, 19962)len(all_landmarks_data), len(all_empty_data), len(all_all_data)# (202599, 202599, 202599)train_attr_data# Dataset CelebA# Number of datapoints: 162770# Root location: data# Target type: ['attr']# Split: traintrain_attr_data.root# 'data'train_attr_data.split# 'train'train_attr_data.target_type# ['attr']print(train_attr_data.transform)# Noneprint(train_attr_data.target_transform)# Nonetrain_attr_data.download# len(train_attr_data.attr), train_attr_data.attr# (162770, tensor([[0, 1, 1, ..., 0, 0, 1],# [0, 0, 0, ..., 0, 0, 1],# [0, 0, 0, ..., 0, 0, 1],# ...,# [1, 0, 1, ..., 0, 1, 1],# [0, 0, 0, ..., 0, 0, 1],# [0, 1, 1, ..., 1, 0, 1]]))len(train_attr_data.attr_names), train_attr_data.attr_names# (41, ['5_o_Clock_Shadow', 'Arched_Eyebrows', 'Attractive', # 'Bags_Under_Eyes', 'Bald', 'Bangs', 'Big_Lips', 'Big_Nose',# 'Black_Hair', 'Blond_Hair', 'Blurry', 'Brown_Hair',# ...# 'Wearing_Necklace', 'Wearing_Necktie', 'Young', ''])len(train_attr_data.identity), train_attr_data.identity# (162770, tensor([[2880], [2937], [8692], ..., [7391], [8610], [2304]]))len(train_attr_data.bbox), train_attr_data.bbox# (162770, tensor([[95, 71, 226, 313],# [72, 94, 221, 306],# [216, 59, 91, 126],# ...,# [103, 103, 143, 198],# [30, 59, 216, 280],# [376, 4, 372, 515]]))len(train_attr_data.landmarks_align), train_attr_data.landmarks_align# (162770, tensor([[69, 109, 106, ..., 152, 108, 154],# [69, 110, 107, ..., 151, 108, 153],# [76, 112, 104, ..., 156, 98, 158],# ...,# [69, 113, 109, ..., 151, 110, 151],# [68, 112, 109, ..., 150, 108, 151],# [70, 111, 107, ..., 153, 102, 152]]))train_attr_data[0]# (,# tensor([0, 1, 1, 0, 0, 0, 0, 0, 0, 0,# 0, 1, 0, 0, 0, 0, 0, 0, 1, 1,# 0, 1, 0, 0, 1, 0, 0, 1, 0, 0,# 0, 1, 1, 0, 1, 0, 1, 0, 0, 1]))train_attr_data[1]# (,# tensor([0, 0, 0, 1, 0, 0, 0, 1, 0, 0,# 0, 1, 0, 0, 0, 0, 0, 0, 0, 1,# 0, 1, 0, 0, 1, 0, 0, 0, 0, 0,# 0, 1, 0, 0, 0, 0, 0, 0, 0, 1]))train_attr_data[2]# (,# tensor([0, 0, 0, 0, 0, 0, 1, 0, 0, 0,# 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,# 1, 0, 0, 1, 1, 0, 0, 1, 0, 0,# 0, 0, 0, 1, 0, 0, 0, 0, 0, 1]))valid_identity_data[0]# (,# tensor(2594))valid_identity_data[1]# (,# tensor(2795))valid_identity_data[2]# (,# tensor(947))test_bbox_data[0]# (,# tensor([147, 82, 120, 166]))test_bbox_data[1]# (,# tensor([106, 34, 140, 194]))test_bbox_data[2]# (,# tensor([107, 78, 109, 151]))all_landmarks_data[0]# (,# tensor([69, 109, 106, 113, 77, 142, 73, 152, 108, 154]))all_landmarks_data[1]# (,# tensor([69, 110, 107, 112, 81, 135, 70, 151, 108, 153]))all_landmarks_data[2]# (,# tensor([76, 112, 104, 106, 108, 128, 74, 156, 98, 158]))all_empty_data[0]# (, None)all_empty_data[1]# (, None)all_empty_data[2]# (, None)all_all_data[0]# (,# (tensor([0, 1, 1, 0, 0, 0, 0, 0, 0, 0,# 0, 1, 0, 0, 0, 0, 0, 0, 1, 1,# 0, 1, 0, 0, 1, 0, 0, 1, 0, 0,# 0, 1, 1, 0, 1, 0, 1, 0, 0, 1]),# tensor(2880),# tensor([95, 71, 226, 313]),# tensor([69, 109, 106, 113, 77, 142, 73, 152, 108, 154])))all_all_data[1]# (,# (tensor([0, 0, 0, 1, 0, 0, 0, 1, 0, 0,# 0, 1, 0, 0, 0, 0, 0, 0, 0, 1,# 0, 1, 0, 0, 1, 0, 0, 0, 0, 0,# 0, 1, 0, 0, 0, 0, 0, 0, 0, 1]),# tensor(2937),# tensor([72, 94, 221, 306]),# tensor([69, 110, 107, 112, 81, 135, 70, 151, 108, 153])))all_all_data[2]# (,# (tensor([0, 0, 0, 0, 0, 0, 1, 0, 0, 0,# 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,# 1, 0, 0, 1, 1, 0, 0, 1, 0, 0,# 0, 0, 0, 1, 0, 0, 0, 0, 0, 1]),# tensor(8692),# tensor([216, 59, 91, 126]),# tensor([76, 112, 104, 106, 108, 128, 74, 156, 98, 158])))import matplotlib.pyplot as pltfrom matplotlib.patches import Rectanglefrom matplotlib.patches import Circledef show_images(data, main_title=None): if "attr" in data.target_type and len(data.target_type) == 1 or not data.target_type: plt.figure(figsize=(12, 6)) plt.suptitle(t=main_title, y=1.0, fontsize=14) for i, (im, _) in enumerate(data, start=1): plt.subplot(2, 5, i) plt.imshow(X=im) if i == 10: break plt.tight_layout(h_pad=3.0) plt.show() elif "identity" in data.target_type and len(data.target_type) == 1: plt.figure(figsize=(12, 6)) plt.suptitle(t=main_title, y=1.0, fontsize=14) for i, (im, lab) in enumerate(data, start=1): plt.subplot(2, 5, i) plt.title(label=lab.item()) plt.imshow(X=im) if i == 10: break plt.tight_layout(h_pad=3.0) plt.show() elif "bbox" in data.target_type and len(data.target_type) == 1: fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(12, 6)) fig.suptitle(t=main_title, y=1.0, fontsize=14) for (i, (im, (x, y, w, h))), axis in zip(enumerate(data, start=1), axes.ravel()): axis.imshow(X=im) rect = Rectangle(xy=(x, y), width=w, height=h, linewidth=3, edgecolor='r', facecolor='none') axis.add_patch(p=rect) if i == 10: break fig.tight_layout(h_pad=3.0) plt.show() elif "landmarks" in data.target_type and len(data.target_type) == 1: plt.figure(figsize=(12, 6)) plt.suptitle(t=main_title, y=1.0, fontsize=14) for i, (im, lm) in enumerate(data, start=1): px = [] py = [] for j, v in enumerate(lm): if j%2 == 0: px.append(v) else: py.append(v) plt.subplot(2, 5, i) plt.imshow(X=im) plt.scatter(x=px, y=py) if i == 10: break plt.tight_layout(h_pad=3.0) plt.show() elif len(data.target_type) == 4: fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(12, 6)) fig.suptitle(t=main_title, y=1.0, fontsize=14) for (i, (im, (_, lab, (x, y, w, h), lm))), axis in zip(enumerate(data, start=1), axes.ravel()): axis.set_title(label=lab.item()) axis.imshow(X=im) rect = Rectangle(xy=(x, y), width=w, height=h, linewidth=3, edgecolor='r', facecolor='none', clip_on=True) axis.add_patch(p=rect) for j, (px, py) in enumerate(lm.split(2)): axis.add_patch(p=Circle(xy=(px, py))) # for j, v in enumerate(lm): # if j%2 == 0: # px.append(v) # else: # py.append(v) # axis.scatter(x=px, y=py) # axis.plot(px, py)# `axis.scatter()` and `axis.plot()` of `plt.subplots()` don't work# properly. They shrink images so use `axis.add_patch()` instead. if i == 10: break fig.tight_layout(h_pad=3.0) plt.show()show_images(data=train_attr_data, main_title="train_attr_data")show_images(data=valid_identity_data, main_title="valid_identity_data")show_images(data=test_bbox_data, main_title="test_bbox_data")show_images(data=all_landmarks_data, main_title="all_landmarks_data")show_images(data=all_empty_data, main_title="all_empty_data")show_images(data=all_all_data, main_title="all_all_data")





以上就是CelebA 是 PyTorch的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1354781.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























