
在本文中,您将了解 n 1 查询、如何使用 appsignal 检测它们,以及如何修复它们以显着加快 django 应用程序的速度。
我们将从理论方面开始,然后转向实际示例。实际示例将反映您在生产环境中可能遇到的场景。
让我们开始吧!
什么是n 1查询?
n 1 查询问题是与数据库交互的 web 应用程序中普遍存在的性能问题。这些查询可能会导致严重的瓶颈,并且随着数据库的增长而加剧。
当您检索对象集合,然后访问集合中每个项目的相关对象时,就会出现问题。例如,获取书籍列表需要单个查询(1 个查询),但访问每本书的作者会触发对每个项目的额外查询(n 个查询)。
在数据库中创建或更新数据时也可能会出现 n 1 问题。例如,通过循环迭代来单独创建或更新对象,而不是使用bulk_create() 或bulk_update() 等方法,可能会导致过多的查询。
n 1 查询效率极低,因为执行大量小查询比将操作合并为更少、更大的查询要慢得多,而且更耗费资源。
django 的默认 queryset 行为可能会无意中导致 n 1 问题,特别是如果您不知道 queryset 的工作原理的话。 django 中的查询集是惰性的,这意味着在计算查询集之前不会执行任何数据库查询。
先决条件
确保您拥有:
python 3.9 和 git 安装在本地计算机上支持 appsignal 的操作系统appsignal 帐户
注意:此项目的源代码可以在 appsignal-django-n-plus-one github 存储库中找到。
项目设置
我们将使用图书管理网络应用程序。该 web 应用程序旨在演示 n 1 查询问题以及如何解决它。
首先克隆 github 存储库的基础分支:
$ git clone git@github.com:duplxey/appsignal-django-n-plus-one.git --single-branch --branch base && cd appsignal-django-n-plus-one
接下来,创建并激活虚拟环境:
$ python3 -m venv venv && source venv/bin/activate
安装要求:
(venv)$ pip install -r requirements.txt
迁移并填充数据库:
(venv)$ python manage.py migrate(venv)$ python manage.py populate_db
最后,启动开发服务器:
(venv)$ python manage.py runserver
打开您最喜欢的网络浏览器并导航到http://localhost:8000/books.网络应用程序应从数据库返回包含 500 本书的 json 列表。
可通过 http://localhost:8000/admin. 访问 django 管理站点,管理员凭据为:
user: usernamepass: password
为 django 安装 appsignal
要在 django 项目上安装 appsignal,请按照官方文档操作:
appsignal python 安装appsignal django 检测appsignal sqlite 工具
通过重新启动开发服务器确保一切正常:
(venv)$ python manage.py runserver
您的应用程序应自动向 appsignal 发送演示错误。从此时起,您的所有错误都将发送到 appsignal。此外,appsignal 将监控您应用的性能并检测任何问题。
网络应用程序逻辑
修复 n 1 查询的先决条件是了解应用程序的数据库架构。密切关注模型的关系:它们可以帮助您查明潜在的 n 1 问题。
型号
web 应用程序有两个模型 – 作者和书籍 – 它们共享一对多 (1:m) 关系。这意味着每本书都与一个作者相关联,而一个作者可以链接到多本书。
两个模型都有一个 to_dict() 方法,用于将模型实例序列化为 json。最重要的是,book 模型使用深度序列化(序列化书籍以及书籍的作者)。
模型在 books/models.py 中定义:
# books/models.pyclass author(models.model): first_name = models.charfield(max_length=64) last_name = models.charfield(max_length=64) birth_date = models.datefield() def full_name(self): return f"{self.first_name} {self.last_name}" def to_dict(self): return { "id": self.id, "first_name": self.first_name, "last_name": self.last_name, "birth_date": self.birth_date, } def __str__(self): return f"{self.first_name} {self.last_name}"class book(models.model): title = models.charfield(max_length=128) author = models.foreignkey( to=author, related_name="books", on_delete=models.cascade, ) summary = models.textfield(max_length=512, blank=true, null=true) isbn = models.charfield(max_length=13, unique=true, help_text="isbn-13") published_at = models.datefield() def to_dict(self): return { "id": self.id, "title": self.title, "author": self.author.to_dict(), "summary": self.summary, "isbn": self.isbn, "published_at": self.published_at, } def __str__(self): return f"{self.author}: {self.title}"
然后它们在 books/admin.py 中注册 django 管理站点,如下所示:
# books/admin.pyclass bookinline(admin.tabularinline): model = book extra = 0class authoradmin(admin.modeladmin): list_display = ["full_name", "birth_date"] inlines = [bookinline]class bookadmin(admin.modeladmin): list_display = ["title", "author", "published_at"]admin.site.register(author, authoradmin)admin.site.register(book, bookadmin)
请注意,authoradmin 使用 bookinline 在作者的管理页面中显示作者的书籍。
意见
网络应用程序提供以下端点:
/books/ 返回书籍列表/books// 返回特定的书籍/books/by-authors/ 返回按作者分组的书籍列表/books/authors/ 返回作者列表/books/authors// 返回特定作者
如果您正在运行开发网络服务器,则可以单击上面的链接。
它们在 books/views.py 中定义如下:
# books/views.pydef book_list_view(request): books = book.objects.all() return jsonresponse( { "count": books.count(), "results": [book.to_dict() for book in books], } )def book_details_view(request, book_id): try: book = book.objects.get(id=book_id) return jsonresponse(book.to_dict()) except book.doesnotexist: return jsonresponse({"error": "book not found"}, status=404)def book_by_author_list_view(request): try: authors = author.objects.all() return jsonresponse( { "count": authors.count(), "results": [ { "author": author.to_dict(), "books": [book.to_dict() for book in author.books.all()], } for author in authors ], } ) except author.doesnotexist: return jsonresponse({"error": "author not found"}, status=404)def author_list_view(request): authors = author.objects.all() return jsonresponse( { "count": authors.count(), "results": [author.to_dict() for author in authors], } )def author_details_view(request, author_id): try: author = author.objects.get(id=author_id) return jsonresponse(author.to_dict()) except author.doesnotexist: return jsonresponse({"error": "author not found"}, status=404)
太棒了,您现在知道网络应用程序是如何工作的!
在下一节中,我们将对我们的应用程序进行基准测试,以使用 appsignal 检测 n 1 查询,然后修改代码以消除它们。
使用 appsignal 检测 django 应用程序中的 n 1 查询
使用 appsignal 检测性能问题很容易。您所要做的就是像平常一样使用/测试应用程序(例如,通过访问所有端点并验证响应来执行最终用户测试)。
当某个端点被命中时,appsignal 将为其创建一份性能报告,并将所有相关访问分组在一起。每次访问都将作为样本记录在端点的报告中。
检测视图中的 n 1 查询
首先,访问您应用程序的所有端点以生成性能报告:
/书籍//books///书籍/作者//书籍/作者//books/authors//
接下来,让我们使用 appsignal 仪表板来分析慢速端点。
示例 1:一对一关系 (select_lated())
导航到您的 appsignal 应用程序并选择侧边栏上的 性能 > 问题列表。然后单击平均值 按平均响应时间降序对问题进行排序。
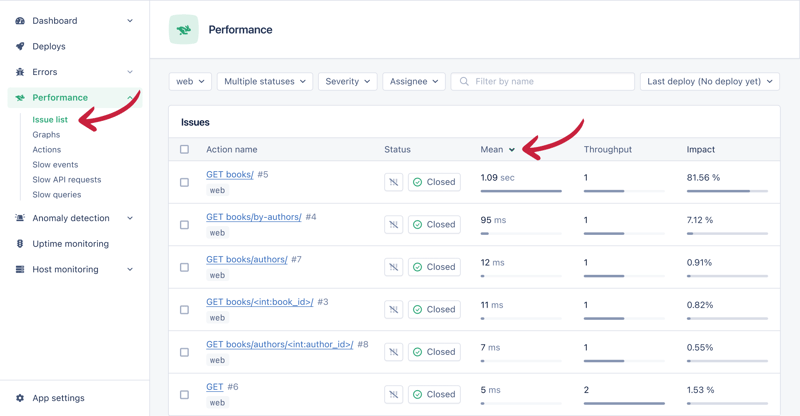
点击最慢的端点(books/)查看其详细信息。
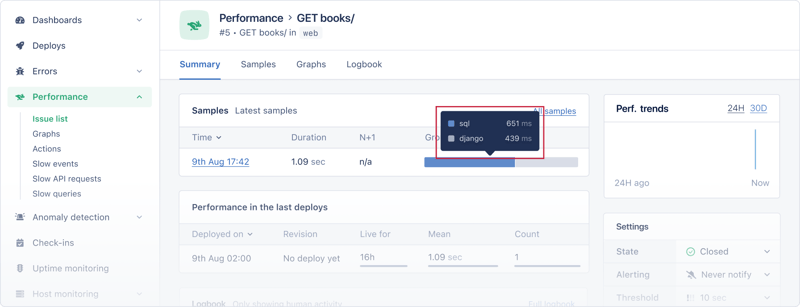
查看最新示例,我们可以看到该端点在 1090 毫秒内返回响应。组细分显示 sqlite 需要 651 毫秒,而 django 需要 439 毫秒。
这表明存在问题,因为像这样简单的端点不应该花费那么长时间。
要获取有关所发生事件的更多详细信息,请选择侧边栏中的示例,然后选择最新示例。
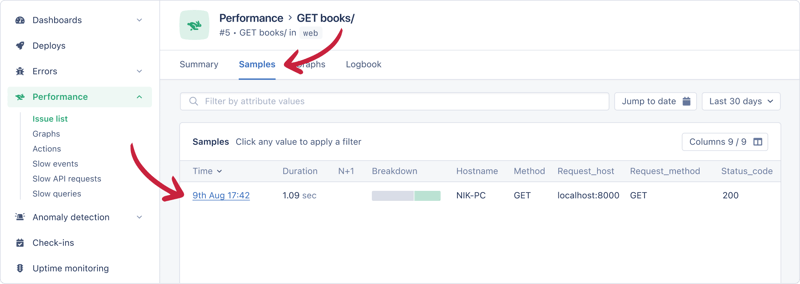
向下滚动到事件时间线以查看执行了哪些 sql 查询。
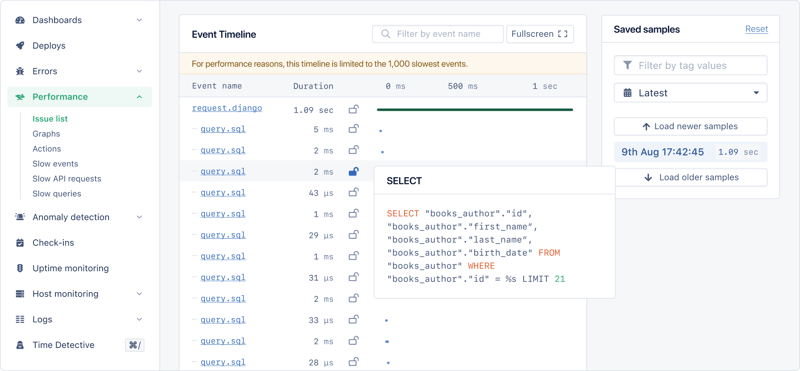
将鼠标悬停在 query.sql 文本上会显示实际的 sql 查询。
执行了超过 1000 个查询:
select * from "books_book";select * from "books_author" where "books_author"."id" = 3; -- 3= 1st book's author idselect * from "books_author" where "books_author"."id" = 6; -- 6= 2nd book's author id...select * from "books_author" where "books_author"."id" = n; -- n= n-th book's author id
这些是 n 1 查询的明显标志。第一个查询获取一本书 (1),随后的每个查询获取该书的作者详细信息 (n)。
要修复它,请导航到 books/views.py 并修改 book_list_view(),如下所示:
# books/views.pydef book_list_view(request): books = book.objects.all().select_related("author") # modified return jsonresponse( { "count": books.count(), "results": [book.to_dict() for book in books], } )
通过利用 django 的 select_lated() 方法,我们在初始查询中选择其他相关对象数据(即作者)。 orm 现在将利用 sql 连接,最终查询将如下所示:
select * from "books_book" inner join "books_author" on ("books_book"."author_id" = "books_author"."id")
等待开发服务器重新启动并重新测试受影响的端点。
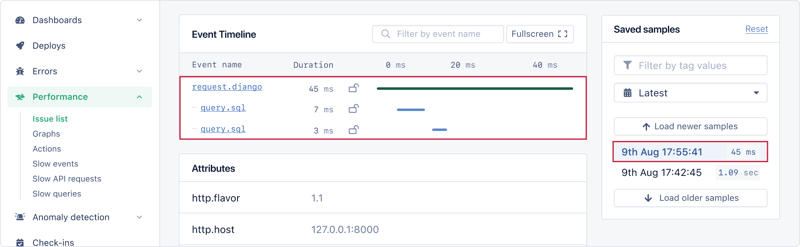
再次进行基准测试后,响应时间从 1090 减少到 45,查询数量从 1024 减少到 2。分别提高了 24 倍和 512 倍。
示例 2:多对一关系 (prefetch_lated())
接下来,让我们看看第二慢的端点(books/by-authors/)。
像我们在上一步中所做的那样使用仪表板来检查端点的 sql 查询。您会注意到此端点有类似但不太严重的 n 1 模式。
这个端点的性能不太严重,因为 django 足够聪明,可以缓存频繁执行的 sql 查询,即重复获取一本书的作者。查看官方文档以了解有关 django 缓存的更多信息。
让我们利用 books/views.py 中的 prefetch_lated() 来加速端点:
# books/views.pydef book_by_author_list_view(request): try: authors = author.objects.all().prefetch_related("books") # modified return jsonresponse( { "count": authors.count(), "results": [ { "author": author.to_dict(), "books": [book.to_dict() for book in author.books.all()], } for author in authors ], } ) except author.doesnotexist: return jsonresponse({"error": "author not found"}, status=404)
在上一节中,我们使用 select_lated() 方法来处理一对一关系(每本书都有一个作者)。然而,在本例中,我们正在处理一对多关系(一个作者可以拥有多本书),因此我们必须使用 prefetch_lated()。
这两种方法的区别在于 select_lated() 工作在 sql 级别,而 prefetch_lated() 则在 python 级别进行优化。后一种方法也可以用于多对多关系。
有关更多信息,请查看 django 关于 prefetch_lated() 的官方文档。
基准测试后,响应时间从 90 毫秒减少到 44 毫秒,查询数量从 32 减少到 4。
在 django admin 中检测 n 1 查询
在 django 管理站点中发现 n 1 查询的工作原理类似。
首先,登录您的管理站点并生成绩效报告(例如,创建一些作者或书籍,更新和删除它们)。
接下来,导航到您的 appsignal 应用仪表板,这次由管理员过滤问题:
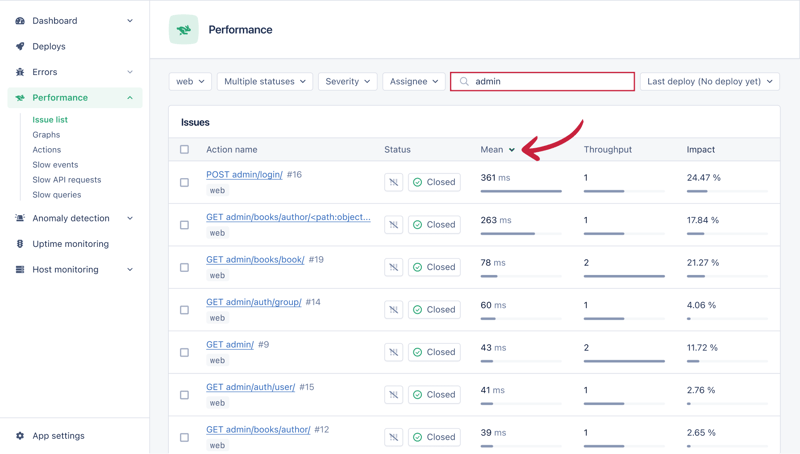
就我而言,两个最慢的端点是:
/管理/登录/admin/books/author/
我们无法对 /admin/login 做太多事情,因为它完全由 django 处理,所以让我们关注第二个最慢的端点。检查它会发现 n 1 查询问题。每本书都会单独获取作者。
要解决此问题,请重写 bookinline 中的 get_queryset() 以在初始查询中获取作者详细信息:
# books/admin.pyclass BookInline(admin.TabularInline): model = Book extra = 0 def get_queryset(self, request): queryset = super().get_queryset(request) return queryset.select_related("author")
再次进行基准测试并验证查询数量是否有所减少。
总结
在这篇文章中,我们讨论了使用 appsignal 检测和修复 django 中的 n 1 查询。
利用您在这里学到的知识可以帮助您显着加快 django web 应用程序的速度。
要记住的两个最重要的方法是 select_lated() 和 prefetch_lated()。第一个用于一对一关系,第二个用于一对多和多对多关系。
编码愉快!
p.s.如果您想在 python 文章发布后立即阅读,请订阅我们的 python wizardry 时事通讯,不错过任何一篇文章!
以上就是使用 AppSignal 在 Django 中查找并修复 N+ueries的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1355044.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























