
数据抓取:高效获取blinkit产品数据,助力应用开发
对于构建应用需要真实数据的开发者来说,数据抓取是高效获取信息的关键。本文将分享如何利用Chrome DevTools和HAR文件从Blinkit平台抓取产品数据,并阐述其优势。
为何选择数据抓取构建杂货应用?
在开发杂货配送应用时,获取真实数据至关重要。自行创建数据集耗时且效率低下。数据抓取则提供了一种快捷、高效的解决方案。通过从Blinkit提取产品信息,我们可以获得准确的真实数据,用于测试和优化应用,避免资源浪费。
数据抓取常用方法:
手动复制粘贴: 简单但低效,仅适用于少量数据。网页抓取工具: (如Scrapy, BeautifulSoup, Puppeteer) 自动化数据提取,适合大规模结构化数据。API集成: 直接访问网站数据,需了解API端点和认证流程。浏览器开发者工具: 检查网络请求、捕获HAR文件或分析页面元素,适合识别隐藏API或JSON数据。无头浏览器: (如Puppeteer, Selenium) 自动化导航和抓取,适用于需要JavaScript渲染的网站。HAR文件解析: 解析HTTP存档文件,提取API、JSON响应等数据,适用于动态内容或隐藏数据的网站。HTML解析: (如BeautifulSoup, Cheerio) 解析HTML提取数据,适用于简单的静态网站。PDF/图像数据提取: (如PyPDF2, Tesseract OCR, Adobe API) 从文件中提取文本。自动脚本: (Python, Node.js等) 自定义脚本控制抓取流程。第三方API: (如DataMiner, Octoparse, Scrapy Cloud) 提供抓取服务,节省时间但可能有限制。
选择HAR文件解析的原因:

HAR(HTTP Archive)文件以JSON格式记录网页网络活动,包含HTTP请求和响应的详细信息。其结构如下:
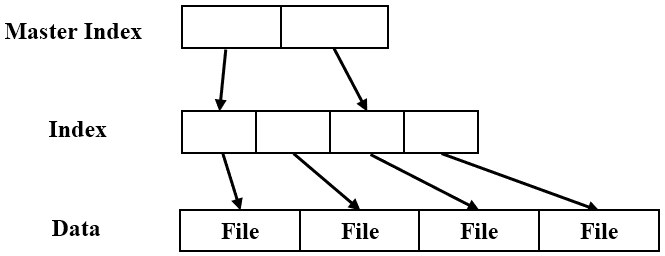
主要包含日志(包含元数据)、条目(每个HTTP请求和响应)、页面(加载网页数据)和创建者(工具信息)。HAR文件提供网页所有网络活动的全面快照,便于识别隐藏API、捕获JSON负载和提取所需数据。
实施计划:

浏览并捕获网络活动: 打开Blinkit网站,使用Chrome DevTools浏览产品页面,捕获必要的API调用。
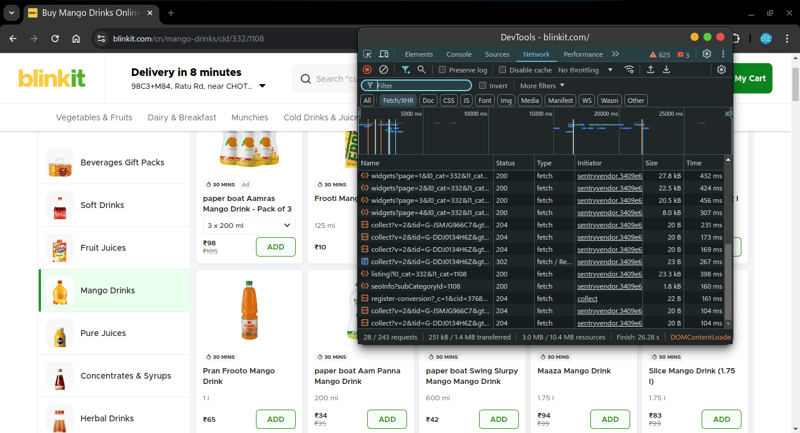
导出HAR文件: 保存记录的网络活动。解析HAR文件: 使用Python解析HAR文件,提取所需数据。三个关键函数:过滤相关响应 (提取/listing?catId=*端点相关的响应)清理和提取数据 (提取ID、名称、类别等关键字段)保存图片到本地 (下载商品图片)

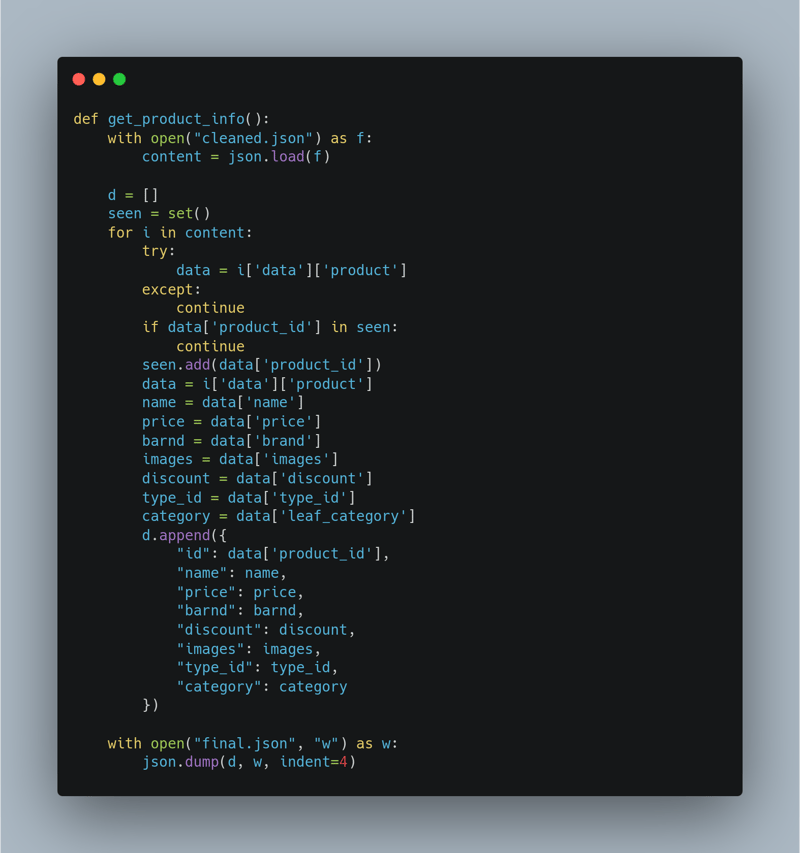
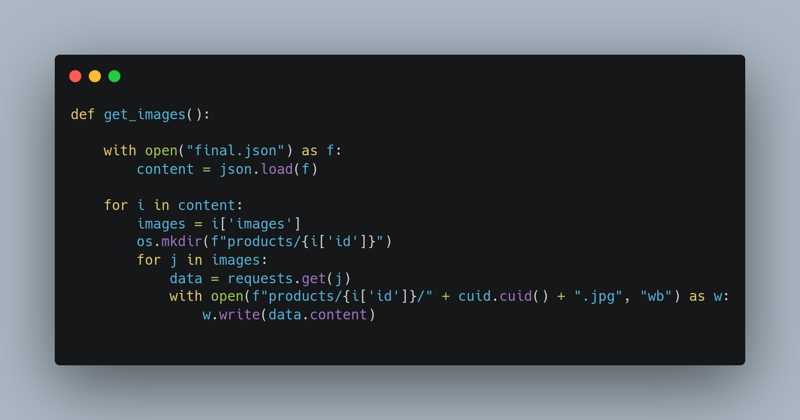
执行与结果: 约30-40分钟内成功抓取约600个产品数据(名称、类别、图片)。
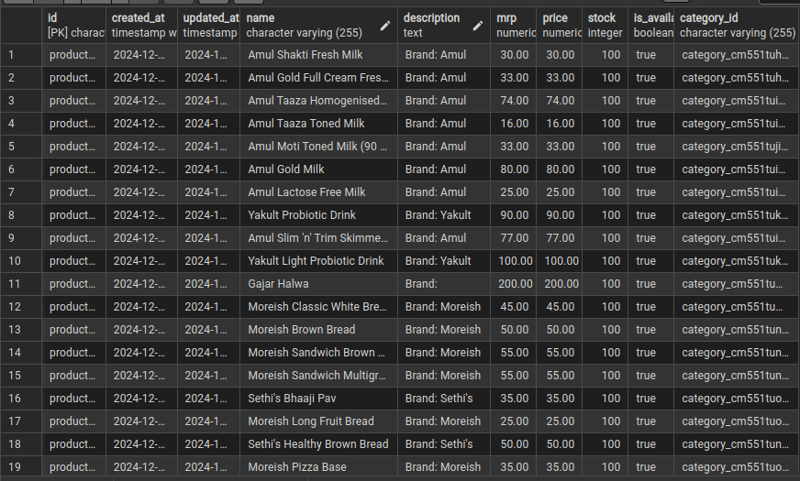
结论:
高效的数据抓取可以节省大量时间和精力。利用Chrome DevTools和HAR文件,我们可以快速有效地从Blinkit提取产品数据。 记住,数据抓取需遵守网站的服务条款和法律法规。 合理运用数据抓取,可以成为提升开发效率的强大工具。
以上就是使用 DevTools 和 HAR 文件抓取数据的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1355187.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























