
利用python和beautiful soup从网络抓取midi数据,训练magenta神经网络生成经典任天堂风格音乐。本文将引导您完成整个过程,从环境搭建到数据下载,并提供代码示例。
准备工作与依赖安装
首先,确保已安装Python 3和pip。建议创建一个虚拟环境,以避免包冲突。 激活虚拟环境后,运行以下命令安装必要的库:
pip install requests==2.22.0 beautifulsoup4==4.8.1
我们使用Beautiful Soup 4,因为它比已不再维护的版本3更稳定。
使用requests抓取数据,Beautiful Soup解析
立即学习“Python免费学习笔记(深入)”;
以下代码从指定网页获取HTML,并创建一个Beautiful Soup对象用于解析:
import requestsfrom bs4 import BeautifulSoupvgm_url = 'https://www.vgmusic.com/music/console/nintendo/nes/'html_text = requests.get(vgm_url).textsoup = BeautifulSoup(html_text, 'html.parser')
soup 对象允许您遍历和搜索HTML中的数据。例如,soup.title 获取页面标题,print(soup.get_text()) 打印所有文本内容。
了解Beautiful Soup的核心方法
find() 和 find_all() 是Beautiful Soup中最常用的方法。find() 用于查找单个元素,例如 soup.find(id='banner_ad').text 获取指定ID元素的文本。 find_all() 用于查找所有匹配条件的元素,例如以下代码打印页面上所有超链接的URL:
for link in soup.find_all('a'): print(link.get('href'))
find_all() 支持多种参数,例如正则表达式或属性,以精确过滤搜索结果。
解析和导航HTML
在编写解析代码之前,建议使用浏览器开发者工具检查目标网页的HTML结构。 下图显示了目标网页截图和开发者工具的使用方法。
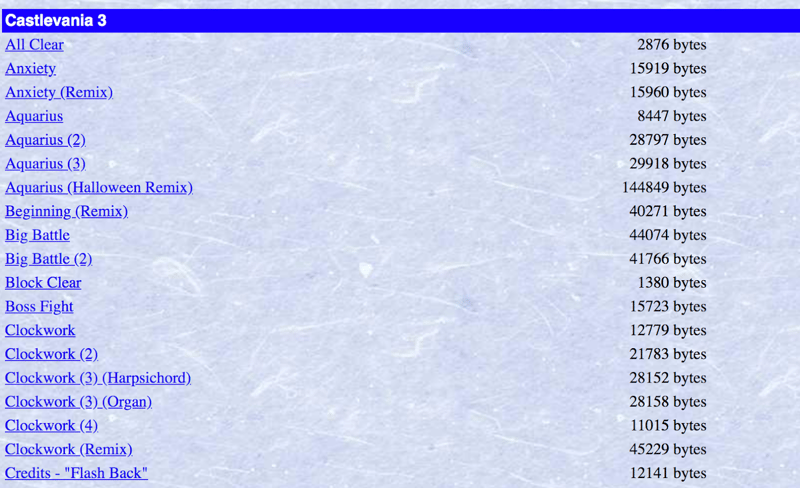
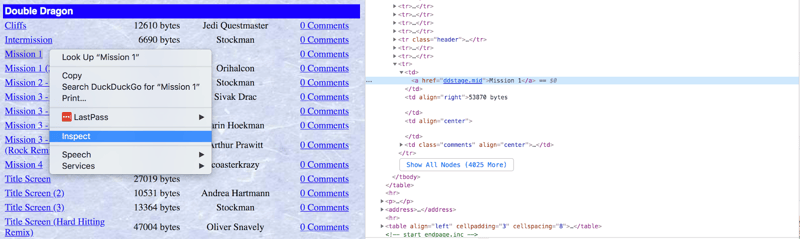
我们的目标是从网页下载MIDI文件,但需要排除重复曲目和混音版本。
使用Beautiful Soup过滤和下载MIDI文件
以下代码使用正则表达式过滤链接,仅下载不包含括号的MIDI文件:
import reimport requestsfrom bs4 import BeautifulSoupvgm_url = 'https://www.vgmusic.com/music/console/nintendo/nes/'html_text = requests.get(vgm_url).textsoup = BeautifulSoup(html_text, 'html.parser')def download_track(count, track_element): track_title = track_element.text.strip().replace('/', '-') download_url = '{}{}'.format(vgm_url, track_element['href']) file_name = '{}_{}.mid'.format(count, track_title) r = requests.get(download_url, allow_redirects=True) with open(file_name, 'wb') as f: f.write(r.content) print('Downloaded: {}'.format(track_title))if __name__ == '__main__': attrs = {'href': re.compile(r'.mid$')} tracks = soup.find_all('a', attrs=attrs, string=re.compile(r'^((?!().)*$')) count = 0 for track in tracks: download_track(count, track) count += 1 print(len(tracks))
运行此代码将下载所有过滤后的MIDI文件。

总结与展望
通过Beautiful Soup,您可以轻松地从网页中抓取所需数据。 请记住,网页结构可能会发生变化,需要定期检查和更新代码。 您可以使用mido等库进一步处理MIDI数据,并使用Magenta训练神经网络生成音乐。 希望您能利用这些技术创建令人惊叹的项目!
以上就是使用 Beautiful Soup 在 Python 中进行网页抓取和解析 HTML的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1355513.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
![pandas 中语法 `df[&#column&#] = expression` 的解释](https://cdn.chuangxiangniao.com/www/2025/12/173646838486162.jpg?imageMogr2/crop/480x300/gravity/center)



























