
blinkit、zepto、swiggy instamart 等应用程序近年来出现了巨大的增长。为了探索此类应用程序的挑战和复杂性,我决定创建一个类似的应用程序来了解如何在 10 分钟或更短的时间内将杂货送到您家门口。
问题陈述
所以基本上这些只是一个供应商电子商务网站,交货速度更快,不到一天,这里要解决的主要问题是如何找到该地区的送货代理,然后将他们分配给订单,该网站的其他功能应用程序与电子商务网站相同
作为一名自由职业者,我建立了相当多的电子商务平台,提供多种服务,这也不例外。
技术堆栈
作为一名主要使用 Django 作为后端和 React 作为前端的全栈开发人员,我选择了与我过去使用 Class To Cloud 作为前端的经验相同的方式,我选择了 React Native。
对于数据库,我使用 PorstgresSQL,因为我需要一个 SQL 数据库来更好地存储我使用 Redis 的内存数据库的数据。
后端
框架:Django数据库:用于结构化数据存储的 PostgreSQL。内存数据库:用于缓存和快速数据检索的Redis。
前端
框架:React Native(利用过去的 Class To Cloud 经验)。
库存管理的数据抓取
在构建项目时,我很快就处理了电子商务部分,例如产品和类别列表,但为了真实世界的数据。我需要抓取数据,我发现了一种使用 har 文件的非常新的方法。您可以在这里阅读有关此体验的更多信息。
我使用这些数据来创建应用程序的设计,结果证明效果很好,我从 Figma 设计和现有应用程序中获得了一些灵感。原来是这样的
设计灵感
对于应用程序的设计,我结合了:
Figma 模板.来自 Blinkit 和 Zepto 等现有应用程序的灵感。
屏幕设计
主屏幕实时位置跟踪
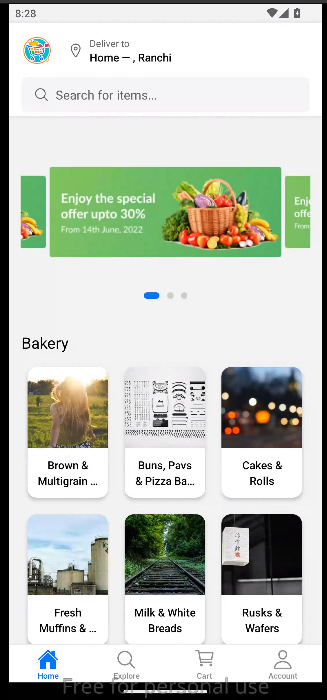
实时位置跟踪
我没有使用移动架构和 GPS 系统的经验,我对这个主题进行了大量研究,发现每个人都在谈论使用 Kafka 进行位置更新。它是一个事件驱动的系统,可以轻松处理所有任务,但作为一个整体架构应用程序,我不想通过添加更多的 kafka 开销来使事情变得复杂,所以我想出了自己的解决方案。
我了解 Django 的缓存系统,但在使用 redis 并使其工作之前从未使用过它,您可以在这里详细了解这方面。
虽然我不认为这个系统很棒,但作为一个副项目,如果用户群非常少,我认为这个系统就很好了。如果我找到更好的方法来做到这一点,我会更新
经验教训
技术堆栈决策:选择技术堆栈时平衡复杂性和性能的重要性。您不一定要采用每个人都建议的技术堆栈,而是选择能够完成您的用例并且您可以轻松维护的技术堆栈。
实时更新:实时更新需要跨多个系统仔细同步。我仍在研究如何使这些更新更加安全可靠,以及如果该地区没有可用的驱动程序该怎么办。
模块化架构:如果明天您需要扩展并且希望速度更快,那么将您的项目模块化,那么您应该只需要一个 ec2 实例就可以实现这一点。
未来的考虑因素
到目前为止,考虑到范围,我认为不需要在项目中添加更多内容,如果将来我决定将其作为产品发布,那么我会考虑更新到目前为止,应用程序的状态只是分散项目并将其存储到数据库中,我可以添加分析功能,还可以添加一个应用程序供管理员在手机上查看数据。使这个应用程序成为白标,任何人都可以使用这个应用程序,只需进行一些上下配置。
结论
构建 10 分钟杂货配送应用程序是一项具有挑战性但又有益的努力。通过正面解决运营和技术挑战并做出有关技术堆栈的战略决策,该应用程序为成功奠定了坚实的基础。随着应用程序的发展,它将继续发展,集成高级功能并进行扩展以满足不断增长的需求。
源代码
您可以在此处找到该应用程序的完整源代码。
与我联系
如果您有疑问或想分享自己的经验,请随时发表评论或联系我们!
以上就是分钟杂货配送应用程序:挑战、技术堆栈和关键决策的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1355674.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


























