
我们终于完成了 10 个谜题,超越了我之前的记录(尽管我还有第 24 天和第 25 天的时间来解决,而且我可能需要在第二部分中重新审视第 12 天)。巧合的是,我能够调整我的 fsm 库来解决第 11 天的问题。虽然这不是最有效的解决方案,但我很乐意分享它。

由 microsoft copilot 生成的非常神秘的插图
我们首先解析输入,一个看似简单的空格分隔数字列表。正如我们现在所知,较小的输入文件通常暗示着其他地方存在更复杂的挑战。尽管如此,解析函数还是很简单的:
def parse(input: str) -> tuple[int, ...]: return tuple(int(item) for item in input.strip().split(" "))
第 1 部分
让我们从一个简单的实现开始,直接将谜题的描述转换为代码。这需要实施三个转换规则。在这个拼图中,每块石头都由刻有的数字表示。我们要实现的第一条规则是,如果数字的位数为偶数,则分裂石头的函数:
def len_digit(number: int) -> int: return floor(log10(number) + 1)def stone_split(stone: int) -> tuple[int, int]: assert len_digit(stone) % 2 == 0 return ( int(stone / (10 ** (len_digit(stone) / 2))), int(stone % (10 ** (len_digit(stone) / 2))), )
len_digit 函数是我们在第 7 天也使用的一种技术,它使用 floor 和 log10 函数计算数字中的位数。 stone_split 使用此函数来确定是否应该分割石头。如果位数为偶数,stone_split 函数会将石头分成两等份。
第一个变换规则仅当石头的值为0时才适用。在这种特定情况下,石头的值会增加到 1。为了保持一致性并简化后续处理,所有转换函数都将返回元组。这是使用装饰器实现的,如下所示:
def to_tuple(func: callable[..., int]) -> callable[..., tuple[int]]: def inner(*arg: any, **kwargs: any) -> tuple[int]: return (func(*arg, **kwargs),) return inner@to_tupledef stone_increment(stone: int) -> int: assert stone == 0 return 1
让每个转换函数返回一个元组的原因是为了轻松组合将转换应用于多个石头的结果。这使我们能够将每次“闪烁”(一组完整的转换)后所有石头的状态表示为单个元组。当我们实现眨眼逻辑时,这一点会变得更加清晰。
最后,第三个变换规则是将石头的价值乘以 2024。此规则仅适用于前面的规则均不适用(即石头不为 0 并且没有偶数)数字)。
@to_tupledef stone_multiply(stone: int) -> int: return stone * 2024
同样,这会以元组形式返回结果。
现在我们已经实现了单独的转换规则,我们将它们组合成一个stone_transform函数。该函数将石头的值作为输入,并根据之前定义的规则应用适当的转换。
def stone_transform(stone: int) -> tuple[int, ...]: result = () if stone == 0: result = stone_increment(stone) elif len_digit(stone) % 2 == 0: result = stone_split(stone) else: result = stone_multiply(stone) return result
现在我们可以对所有石头进行眨眼了。为此,我想介绍一下toolz中的pipe函数。与 linux 中的管道运算符类似,toolz.pipe 函数允许我们将一个函数的输出重定向到下一个函数的输入。例如,当您想要阅读网站 html 源代码的前几行时,您可以使用
下载并打印源代码
curl https://example.com/ | head
如果curl和head可作为函数使用,则使用toolz.pipe的等效代码将是:
from toolz import pipepipe("https://example.com", curl, head)
虽然卷曲| head 示例可以在 python 中重写为 head(curl(“https://example.com”)),这个谜题需要我们重复应用相同的转换。虽然reduce 语句可以实现类似的结果,但我更喜欢使用管道和重复的方法,它应用了stone_transform每眨眼每颗石头:
from collections.abc import iteratorfrom itertools import chain, repeatdef blink(stones: tuple[int, ...], iterations: int = 1) -> iterator[int]: return pipe( stones, *repeat( lambda current: chain.from_iterable( stone_transform(stone) for stone in current ), iterations, ), )
现在我们可以组装第 1 部分的解决方案,该解决方案要求 25 次迭代后的石头数量。
def part1(input: str) -> int: return len(tuple(blink(parse(input), 25)))
熟悉这个谜题的人可能会预见到其描述中存在潜在的矛盾,我们将在第 2 部分中解决这个问题。
第2部分
谜题描述指出:
无论宝石如何变化,它们的顺序都会保持,并且保持完美的直线。
但是,第 1 部分和第 2 部分都只询问数量 的石头,而不是它们的顺序。这就提出了一个有趣的问题:强调维护秩序是故意误导吗?
作者对此的评论就留给读者来解读吧。
现在,我们将继续假设顺序无关。如果是这种情况,我们在每次眨眼后唯一关心的是每个不同宝石值的计数。本质上,我们需要汇总每次眨眼的结果,并将计数乘以上一次眨眼的相应计数。
例如,如果我们之前有两个值为 2024 的棋子,那么一眨眼后,它们将变成两个值为 20 的棋子和两个值为 24 的棋子。因此,我们各有两个新的棋子值。
为了有效地聚合计数,我将引入 toolz 中的 merge_with。该函数合并多个词典。在重复键的情况下,它使用提供的函数来组合相应的值。例如:
from toolz import merge_withfoo = {"meow": 1}bar = {"meow": 2}baz = merge_with(sum, foo, bar)print(baz) # prints {"meow", 3}
为了实现更高效的眨眼,我们将替换原来的 lambda 函数:
lambda current: chain.from_iterable( stone_transform(stone) for stone in current)
这个 lambda 函数跟踪单个宝石的顺序。我们的新方法仅关注每种不同宝石价值的计数。我们将使用“石头计数映射”——一个字典,其中键是石头值,值是它们相应的计数。对于每次眨眼,我们都会转换键(石头值)并将结果计数聚合成新的石头计数映射。
def blink_get_index(current: dict[int, int]) -> dict[int, int]: return merge_with( sum, *( {stone: count_current} for stone_current, count_current in current.items() for stone in stone_transform(stone_current) ), )
使用blink_get_index函数,我们现在可以实现更高效的blink_to_count函数,直接计算最终的石头数量:
def blink_to_count(stones: tuple[int, ...], iterations: int = 1) -> int: return sum( pipe( counter(stones), *repeat(blink_get_index, iterations), ).values()
通过我们高效的blink_to_count函数,我们现在可以轻松计算第2部分75次迭代后的石头数量:
def part2(input: str) -> int: return blink_to_count(parse(input), 75)
fsm 库 genstates 怎么样?
在这篇文章的开头,我提到这个谜题提供了一个很好的机会来展示我的 fsm 库 genstates。如果我们将石头变换表示为状态机,则图表将如下所示:
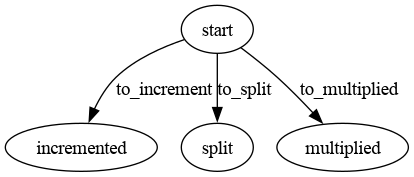
借助 ai 工具构建状态机库
为了演示如何将 genstates 应用于这个难题,我们将定义状态机将使用的函数来确定要进行哪个转换。这些函数充当转换的守卫或条件。
首先,检查石头的价值是否为 0:
def check_is_zero() -> callable[[int], bool]: return lambda value: value == 0
第二,检查宝石的价值是否有偶数位:
def check_is_split() -> callable[[int], bool]: return lambda value: len_digit(value) % 2 == 0
第三,检查以确定是否应应用乘法变换:
def check_is_multiply() -> callable[[int], bool]: return lambda value: not (check_is_split()(value) or check_is_zero()(value))
这些检查必须是详尽的,因为 genstate 的当前设计仅允许一次进行一次转换。与我们基于计数的解决方案相比,这种详尽的检查导致这种方法的效率相对较低。
我们可以重用之前定义的stone_split、stone_increment和stone_multiply函数作为状态转换时发生的动作。考虑到这一点,我们可以使用 genstates 定义状态机:
from genstates import machinestate_machine = machine( { "machine": {"initial_state": "start"}, "states": { "start": { "transitions": { "to_increment": { "rule": "(check_is_zero)", "destination": "incremented", }, "to_split": { "rule": "(check_is_split)", "destination": "split", }, "to_multiplied": { "rule": "(check_is_multiply)", "destination": "multiplied", }, } }, "incremented": {"action": "stone_increment"}, "split": {"action": "stone_split"}, "multiplied": {"action": "stone_multiply"}, }, }, sys.modules[__name__],)
使用 genstates,我们可以将石头转换建模为状态转换,从而有效地替换我们的stone_transform 函数。而不是:
stone_transform(0) # returns (1,)stone_transform(10) # returns (1, 0)stone_transform(3) # returns (6144, )
我们可以使用之前定义的 genstates state_machine:
initial_state = state_machine.initialstate_machine.progress(initial_state, 0).do_action(0) # returns (1,)state_machine.progress(initial_state, 0).do_action(10) # returns (1, 0)state_machine.progress(initial_state, 0).do_action(3) # returns (6144,)
要将其与我们原始的保序闪烁逻辑一起使用,我们需要将状态机实例传递给闪烁函数:
def blink(stones: tuple[int, ...], fsm: machine, iterations: int = 1) -> iterator[int]: return pipe( stones, *repeat( lambda current: chain.from_iterable( fsm.progress(fsm.initial, stone).do_action(stone) for stone in current ), iterations, ), )
我们现在可以创建基于 genstates 的第 1 部分版本,它使用我们的状态机来执行转换:
def part1(input: str) -> int: return len(tuple(blink(parse(input), state_machine, 25)))
也可以将 genstates 应用于第 2 部分中基于计数的方法。这需要对眨眼获取索引进行轻微修改以合并状态机并使用partial将状态机传递给函数。更新后的功能如下:
from functools import partialdef blink_to_count(stones: tuple[int, ...], fsm: Machine, iterations: int = 1) -> int: return sum( pipe( Counter(stones), *repeat(partial(blink_get_index, fsm=fsm), iterations), ).values() )def blink_get_index(current: dict[int, int], fsm: Machine) -> dict[int, int]: return merge_with( sum, *( {stone: count_current} for stone_current, count_current in current.items() for stone in fsm.progress(fsm.initial, stone_current).do_action( # type: ignore stone_current ) ), )
这个 genstates 实现主要是为了我自己的娱乐和测试目的,因为我是该库的开发人员。虽然不是解决这个难题的最有效方法,但它提供了一个宝贵的机会来探索如何将 genstates 应用于“现实世界”问题(即使这个“世界”是代码的出现)。
导致性能差异的一个重要因素是 genstates 处理转换的方式。该库的设计强制要求在任何给定时间只能进行一次转换。这意味着即使已经满足了较早的条件,也必须评估所有保护条件(check_is_zero、check_is_split 和 check_is_multiply 函数)。这可以防止通过更直接的实现可能出现的短路行为。
我对“代码出现”难题的讨论到此结束。这很有趣,但有一点巧妙的误导。最近工作申请有点忙,这就是为什么我上周没有解决另一个难题,但我希望下周能回到正轨并讨论另一个难题。如果您正在寻找开发人员,请随时与我们联系。
以上就是最后,我的 FSM 库的应用程序! 11 月 11 日代码问世的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1355751.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























