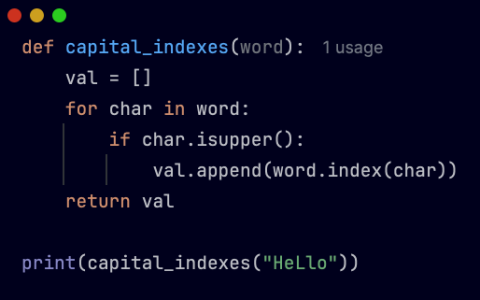
import csvinput_file = 'input.csv'output_file = 'output.csv'column_index = 1with open(input_file, 'r') as infile: csv_reader = csv.reader(infile) header = next(csv_reader) filtered_rows = [header] for row in csv_reader: if float(row[column_index]) > 100: filtered_rows.append(row)with open(output_file, 'w', newline='') as outfile: csv_writer = csv.writer(outfile) csv_writer.writerows(filtered_rows)print("filtered rows have been written to output.csv")
代码逻辑如下;
>
>导入csv模块:
>代码首先导入csv模块,该模块可以帮助我们读取和写入csv文件。
>文件路径和列索引
:>
input_file =’input.csv’告诉程序在哪里找到我们要读取的文件。output_file =’output.csv’是程序将保存过滤数据的地方。>column_index = 1指示我们将检查值的列(在这种情况下为第二列,因为列计数从0开始)。>打开输入文件:>该程序打开input.csv文件以读取内部的数据。
>
>读取标题:它读取文件的第一行,其中包含列名,并将其存储在标题中。这将稍后在写入新文件时使用。
>
过滤行
:该程序通过每一行数据:
>它检查指定列中的数字(第二列)是否大于100。如果该数字大于100,则该程序将保持该行。
如果不是,则行跳过。
>>写入输出文件:>过滤后,该程序将标题和剩余的行(满足条件)写入称为output.csv。打印消息
:最后,该程序打印一条消息,让您知道已过滤的数据已保存到新文件中。
2a。 ** python多线程解决方案,以同时下载多个文件。
>
import threadingimport requestsurls = [ 'https://example.com/file1.jpg', 'https://example.com/file2.jpg', 'https://example.com/file3.jpg']def download_file(url): try: response = requests.get(url) filename = url.split('/')[-1] with open(filename, 'wb') as f: f.write(response.content) print(f"downloaded: {filename}") except exception as e: print(f"failed to download {url}: {e}")threads = []for url in urls: thread = threading.thread(target=download_file, args=(url,)) threads.append(thread) thread.start()for thread in threads: thread.join()print("all downloads are complete.")
说明代码:
url列表:urls包含要下载的文件url列表。
下载函数:download_file(url)是一个从url下载单个文件并保存它的函数。
线程创建
:对于每个url,使用螺纹创建一个新线程。线程同时下载文件。>启动线程:在每个线程上调用start()方法开始下载文件。等待完成:join()确保主要程序等待所有线程在打印“所有下载均已完成”之前完成。2b。一个多处理脚本,以计算1到10的数字阶乘。
import multiprocessingdef factorial(n): result = 1 for i in range(1, n + 1): result *= i print(f"factorial of {n} is {result}")if __name__ == '__main__': for i in range(1, 11): process = multiprocessing.process(target=factorial, args=(i,)) process.start() process.join() print("all factorials have been computed.")
解释:fortorial(n)函数:计算数字n的阶乘并打印结果。>主块:在if __name__ ==’__ -main __’块:
通过1到10的数字循环。对于每个数字,创建一个新的过程来计算其阶乘。>开始每个过程,然后等待使用process.join()在移至下一个过程中完成。
。
> 2c一个简单的python脚本,该脚本演示了如何使用conturrent。
import pandas as pdimport concurrent.futuresdef modify_row(row): row['modified'] = row['value'] * 2 return rowdef main(): data = {'value': [1, 2, 3, 4, 5]} df = pd.DataFrame(data) with concurrent.futures.ThreadPoolExecutor() as executor: results = list(executor.map(modify_row, [row for _, row in df.iterrows()])) df = pd.DataFrame(results) print(df)if __name__ == '__main__': main()
解释:dataframe :使用列“值”创建一个简单的数据框df。> modify_row函数:此函数通过添加新列“修改”来修改行,其中值是原始的’value’乘以2。 threadpoolexecutor: executor.map(modify_row,[…])在数据框中的每一行中并行运行modify_row函数。
结果
:修改后的数据框在末尾打印出来。
>
以上就是“ Python程序过滤CSV行并将输出写入新文件”的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1356176.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫