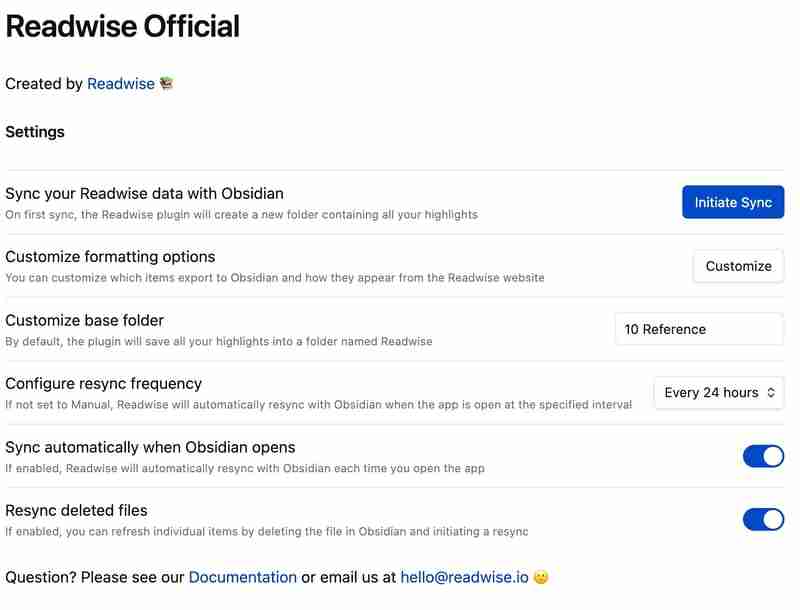
深度学习图像分类:用几百张图片训练苹果香蕉识别模型,可行吗?
利用深度学习技术构建苹果和香蕉图像分类器,样本数量是一个关键问题。本文分析一个案例,并探讨如何提升模型性能。
案例中,研究者使用ResNet50模型,收集了458张图片(195张香蕉,263张苹果)进行训练,使用了数据增强技术(随机裁剪和水平翻转),并采用SGD优化器。然而,结果却令人沮丧:所有图片都被预测为香蕉。
这引发了样本量不足的质疑。一种替代方案是:使用预训练的VGG16模型提取特征,再用这些特征训练一个三层MLP网络。这暗示,少量样本(几百张)可能足以训练一个性能尚可的模型。
两种方法各有优劣。ResNet50等大型预训练模型拥有强大的特征提取能力,但需要大量计算资源和训练数据。数据不足容易导致过拟合,正如案例中所示。而VGG16+MLP方案,则降低了对数据量和计算资源的需求,并降低了过拟合风险,更适合少量样本的情况。
因此,458张图片可能不足以训练ResNet50模型,导致泛化能力差。VGG16+MLP方案或许能提升准确率,但这需要进一步实验验证。 最终模型性能,还取决于数据质量、预处理方法、模型选择和超参数设置等因素。
以上就是深度学习图像识别:苹果香蕉分类,几百张图片够用吗?的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1358773.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫