本文介绍了如何使用 Pandas 库对 DataFrame 进行分组聚合计算,以实现按设备统计带宽利用率的需求。通过 groupby() 和 transform() 函数,可以高效地计算每个设备的带宽输入和输出利用率,并将结果添加到原始 DataFrame 中。本文提供了清晰的代码示例,帮助读者理解和应用 Pandas 的强大聚合功能。
使用 Pandas 计算分组带宽利用率
在网络监控和数据分析中,经常需要对设备或接口的带宽利用率进行统计。Pandas 提供了强大的分组聚合功能,可以方便地实现这一需求。本文将介绍如何使用 Pandas 对 DataFrame 进行分组聚合计算,以实现按设备统计带宽利用率的需求。
数据准备
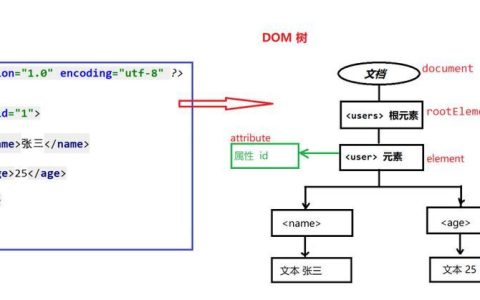
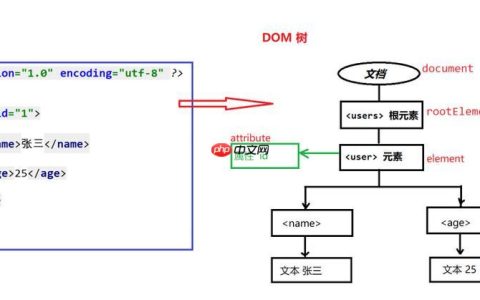
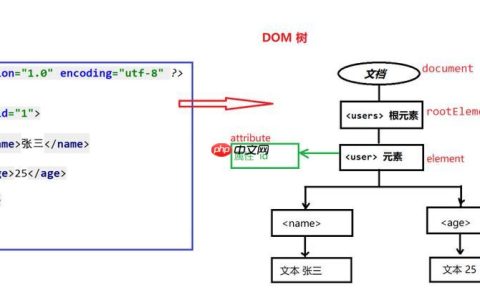
首先,我们需要准备包含设备、接口、输入流量、输出流量、输入带宽、输出带宽等信息的 DataFrame。例如:
import pandas as pddata = { 'Device': ['Usa123', 'Usa123', 'Emea01', 'Emea01'], 'int': ['Eth1', 'Eth0', 'Wan1', 'Eth3'], 'In': [1000, 10000, 1000, 2000], 'Out': [500, 700, 500, 1000], 'Bw_in': [100, 200, 150, 200], 'Bw_out': [75, 80, 90, 70]}df = pd.DataFrame(data)print(df)
这段代码创建了一个 DataFrame,其中包含了设备名称、接口名称、输入流量、输出流量、输入带宽和输出带宽等信息。
分组聚合计算
接下来,我们使用 groupby() 函数按设备名称进行分组,并使用 transform() 函数对每个分组进行聚合计算。具体步骤如下:
使用 groupby() 函数按 Device 列进行分组:
g = df.groupby("Device")
使用 transform() 函数计算每个设备的带宽输入利用率和带宽输出利用率。transform() 函数会将聚合计算的结果广播到每个分组的每一行,保持 DataFrame 的形状不变。
df[["%InUsage", "%OutUsage"]] = ( g[["Bw_in", "Bw_out"]].transform("sum") / g[["In", "Out"]].transform("sum").to_numpy())
这段代码首先使用 g[[“Bw_in”, “Bw_out”]].transform(“sum”) 计算每个设备的输入带宽总和和输出带宽总和。然后,使用 g[[“In”, “Out”]].transform(“sum”) 计算每个设备的输入流量总和和输出流量总和。最后,将带宽总和除以流量总和,得到带宽利用率,并将结果添加到 DataFrame 的 %InUsage 和 %OutUsage 列中。注意,这里使用了 .to_numpy() 将分组后的流量总和转换为 NumPy 数组,以避免 Pandas 在进行除法运算时出现对齐问题。
查看结果
最后,我们可以查看计算结果:
print(df)
输出结果如下:
Device int In Out Bw_in Bw_out %InUsage %OutUsage0 Usa123 Eth1 1000 500 100 75 0.027273 0.1291671 Usa123 Eth0 10000 700 200 80 0.027273 0.1291672 Emea01 Wan1 1000 500 150 90 0.116667 0.1066673 Emea01 Eth3 2000 1000 200 70 0.116667 0.106667
可以看到,DataFrame 中新增了 %InUsage 和 %OutUsage 两列,分别表示每个设备的输入带宽利用率和输出带宽利用率。
总结
本文介绍了如何使用 Pandas 的 groupby() 和 transform() 函数对 DataFrame 进行分组聚合计算,以实现按设备统计带宽利用率的需求。这种方法简洁高效,可以方便地应用于各种数据分析场景。
注意事项:
确保 DataFrame 中包含需要进行分组聚合计算的列。transform() 函数会将聚合计算的结果广播到每个分组的每一行,保持 DataFrame 的形状不变。在进行除法运算时,需要注意避免 Pandas 的对齐问题,可以使用 .to_numpy() 将分组后的数据转换为 NumPy 数组。可以根据实际需求修改分组的列和聚合计算的函数。例如,可以按接口名称进行分组,或者计算其他指标,如平均带宽利用率、最大带宽利用率等。
以上就是使用 Pandas 进行分组聚合计算带宽利用率的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1370154.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫