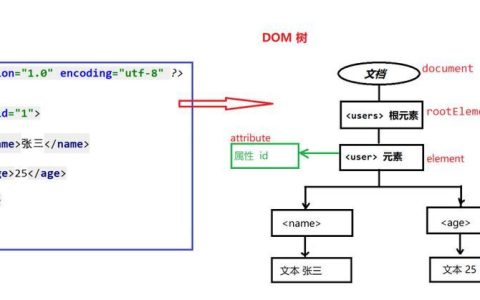
本文详细介绍了在pandas中对分组数据计算滚动平均值时可能遇到的索引不兼容(typeerror)和数据错位问题。通过分析`groupby().rolling().mean()`操作产生的multiindex结构,教程演示了如何利用`droplevel()`方法有效地调整索引,确保滚动统计结果能够正确地赋值回原始dataframe,从而实现精确的分组滚动计算。
在数据分析中,对分组数据执行滚动统计(如滚动平均、滚动求和等)是一项常见操作。Pandas库提供了强大的groupby()和rolling()方法来支持此类计算。然而,在使用这些方法并将结果赋值回原始DataFrame时,用户可能会遇到TypeError: incompatible index of inserted column with frame index错误,或者即使没有错误,计算结果也可能出现错位。本教程将深入探讨这一问题的原因,并提供一个简洁有效的解决方案。
理解问题:索引不兼容与数据错位
首先,我们创建一个示例DataFrame来模拟实际场景:
import pandas as pdimport numpy as np# 创建示例DataFramedf = pd.DataFrame({ 'a': np.random.choice(['x', 'y'], 8), 'b': np.random.choice(['r', 's'], 8), 'c': np.arange(1, 8 + 1)})print("原始DataFrame:")print(df)
可能的输出示例:
原始DataFrame: a b c0 y s 11 y r 22 y s 33 y r 44 y s 55 x r 66 y r 77 x r 8
我们的目标是根据列’a’和’b’进行分组,然后计算列’c’的滚动平均值(窗口大小为3),并将结果作为新列’ROLLING_MEAN’添加到df中。
当尝试直接将groupby().rolling().mean()的结果赋值给新列时,通常会遇到TypeError:
# 错误尝试:直接赋值try: df['ROLLING_MEAN'] = df.groupby(['a', 'b'])['c'].rolling(3).mean()except TypeError as e: print(f"n发生TypeError: {e}")
输出将显示:发生TypeError: incompatible index of inserted column with frame index。
这个错误的原因在于df.groupby([‘a’, ‘b’])[‘c’].rolling(3).mean()操作返回的Series具有一个MultiIndex(多级索引),其中包含分组键(’a’和’b’)以及原始DataFrame的索引。例如,单独查看其输出:
print("ngroupby().rolling().mean()的原始输出结构:")print(df.groupby(['a', 'b'])['c'].rolling(3).mean())
可能的输出示例:
groupby().rolling().mean()的原始输出结构:a b x r 5 NaN 7 7.000000 s 1 NaNy r 2 NaN 3 NaN 6 4.666667y s 0 NaN 4 NaNName: c, dtype: float64
可以看到,这个Series的索引是(a, b, 原始索引)这样的三级结构,而原始DataFrame的索引是单级的。Pandas在尝试将具有MultiIndex的Series插入到具有单级索引的DataFrame中时,会因为索引不兼容而报错。
有些用户可能会尝试使用.values来规避TypeError:
# 错误尝试:使用.values规避TypeErrordf_copy = df.copy() # 使用副本避免影响后续操作df_copy['ROLLING_MEAN'] = df_copy.groupby(['a', 'b'])['c'].rolling(3).mean().valuesprint("n使用.values后的结果 (数据错位):")print(df_copy)# 检查特定分组的数据print("n特定分组 ('a'=='x', 'b'=='r') 的结果:")print(df_copy[(df_copy['a'] == 'x') & (df_copy['b'] == 'r')])
使用.values虽然避免了TypeError,但它会丢弃Series的索引信息,导致计算出的滚动平均值与原始DataFrame的行发生错位。尤其是在分组内数据不连续或某些分组没有足够的数据来计算滚动平均时,这种错位会更加明显,导致结果完全不符合预期。
解决方案:使用 droplevel()
解决索引不兼容问题的关键在于,将groupby().rolling().mean()返回的Series的MultiIndex中的分组级别移除,使其索引结构与原始DataFrame的索引保持一致。droplevel()方法正是为此而生。
我们可以通过在rolling().mean()之后链式调用droplevel([‘a’, ‘b’])来移除分组键’a’和’b’作为索引级别:
# 正确的解决方案:使用droplevel()df['ROLLING_MEAN'] = df.groupby(['a', 'b'])['c'] .rolling(3).mean() .droplevel(['a', 'b'])print("n使用droplevel()后的正确结果:")print(df)# 检查特定分组的数据print("n特定分组 ('a'=='x', 'b'=='r') 的正确结果:")print(df[(df['a'] == 'x') & (df['b'] == 'r')])
通过droplevel([‘a’, ‘b’])操作,我们移除了MultiIndex中的’a’和’b’级别,只保留了原始的DataFrame索引。这样,生成的Series就能够与原始DataFrame的索引正确对齐,从而实现精确的赋值。
工作原理分析:
df.groupby([‘a’, ‘b’])[‘c’]: 这会创建一个GroupBy对象,按’a’和’b’分组,并选择’c’列进行操作。.rolling(3).mean(): 对每个分组内的’c’列计算窗口为3的滚动平均值。这个操作的结果是一个Series,其索引是一个MultiIndex,包含分组键和原始索引。.droplevel([‘a’, ‘b’]): 这是关键步骤。它从MultiIndex中移除了’a’和’b’这两个级别,使得Series的索引只剩下原始DataFrame的行索引。df[‘ROLLING_MEAN’] = …: 此时,处理后的Series的索引与df的索引兼容,Pandas可以正确地根据索引进行匹配和赋值。
注意事项与最佳实践
min_periods参数: rolling()方法有一个min_periods参数,默认为None(即等于窗口大小)。你可以设置min_periods=1来允许在窗口内数据不足时也计算平均值(只要至少有一个非NaN值)。
df['ROLLING_MEAN_min1'] = df.groupby(['a', 'b'])['c'] .rolling(3, min_periods=1).mean() .droplevel(['a', 'b'])print("n使用min_periods=1的滚动平均:")print(df)
理解索引: 在Pandas中进行复杂的数据操作时,始终理解和检查DataFrame或Series的索引结构至关重要。索引是Pandas实现高效数据对齐和合并的基础。通用性: droplevel()方法不仅适用于rolling().mean(),也适用于任何返回MultiIndex Series或DataFrame的groupby()操作结果,只要你需要将其索引调整为与目标DataFrame兼容。其他滚动统计: 此方法同样适用于rolling().sum(), rolling().std(), rolling().min(), rolling().max()等其他滚动统计函数。
总结
在Pandas中计算分组滚动统计并将其结果添加回原始DataFrame时,由于groupby().rolling()操作会产生一个带有MultiIndex的Series,直接赋值会导致索引不兼容错误或数据错位。通过在滚动统计结果上链式调用.droplevel()方法,我们可以有效地移除MultiIndex中的分组级别,使结果的索引与原始DataFrame的索引对齐,从而实现精确、无误的分组滚动计算。掌握这一技巧,将使您在处理复杂的时序或分组数据时更加游刃有余。
以上就是Pandas分组滚动统计:解决索引不兼容与数据错位问题的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1381868.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫