
书生近日推出了全新视觉模型系列——internvl 3.5,涵盖从1b到241b共8种不同规模的版本。
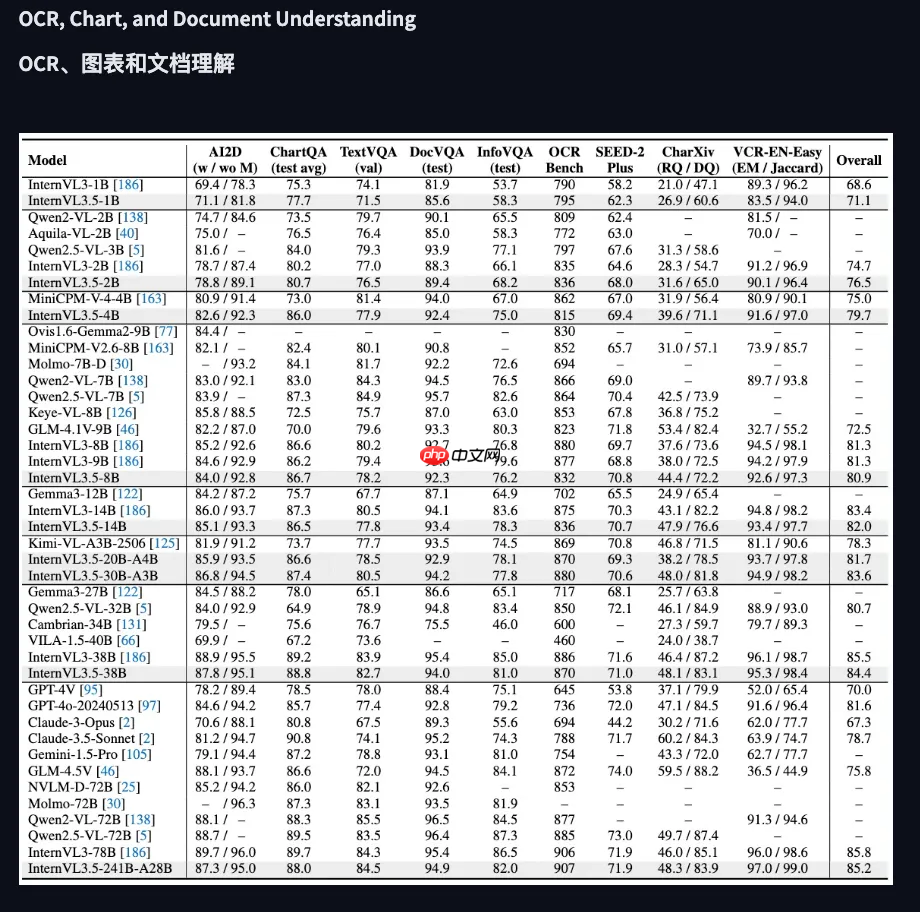
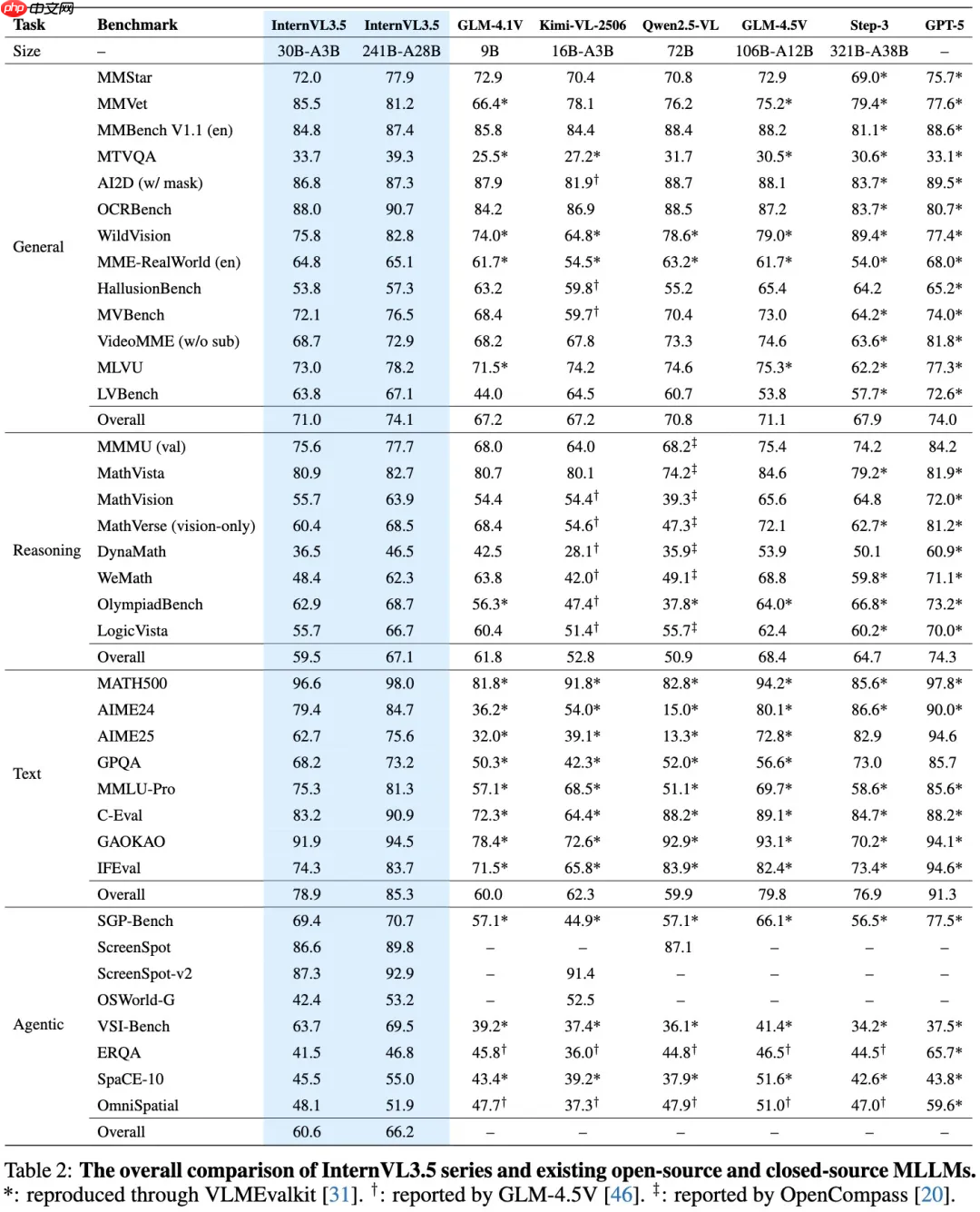
根据多项评测数据显示,InternVL 3.5 中最大规模的241B模型在视觉理解任务中的表现仅次于商用模型 GPT-5 和 Gemini 2.5 Pro,位居前列。
立即进入“豆包AI人工智官网入口”;
立即学习“豆包AI人工智能在线问答入口”;
目前,该系列全部模型均已开源并上线 Hugging Face 平台:
https://www.php.cn/link/e7c3645a3ea1024d6704a3133c7930a8
模型核心技术创新包括:
级联强化学习(Cascade Reinforcement Learning, Cascade RL):结合离线强化学习与在线强化学习的双阶段训练策略,提升模型收敛稳定性与对齐精度,显著增强复杂推理能力,在 MMMU、MathVista 等高难度任务上表现突出。视觉分辨率路由机制(Visual Resolution Router, ViR):支持动态调节视觉 token 的输入分辨率,灵活平衡计算开销与识别精度,提升视觉理解效率。解耦式视觉-语言部署架构(Decoupled Vision-Language Deployment, DvD):将视觉编码器与语言解码器分离部署至不同 GPU 设备,优化资源分配,大幅提高推理吞吐速度。
整体推理性能相较前代提升最高达 16.0%,并在实际部署中实现比 InternVL3 快 4.05 倍的推理速度。
以上就是书生发布 InternVL 3.5 最新视觉全系列模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/139782.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


























