
xpath轴是定位xml/html节点关系的核心机制,其主要类型包括self轴用于指向当前节点自身;child轴选择直接子元素;parent轴选择直接父元素;ancestor轴选择所有祖先节点;ancestor-or-self轴包含自身及祖先;descendant轴选择所有后代节点;descendant-or-self轴包含自身及后代;following-sibling轴选择之后的兄弟节点;preceding-sibling轴选择之前的兄弟节点;following轴选择文档中之后的所有节点;preceding轴选择文档中之前的所有节点;attribute轴选择节点的所有属性。这些轴通过定义从当前节点出发的导航方向,使得xpath表达式能够在复杂、动态变化的文档结构中实现高效、精准的定位。使用轴可以避免脆弱的绝对路径,提升表达式的健壮性和可维护性。选择合适的轴需考虑目标节点的关系、唯一性、文档结构稳定性以及维护成本。xpath轴与谓语结合使用能进一步缩小搜索范围,实现精确定位,如ancestor::div[@id=’main-content’]或descendant::a[contains(text(), ‘下载’)]等常见用法。
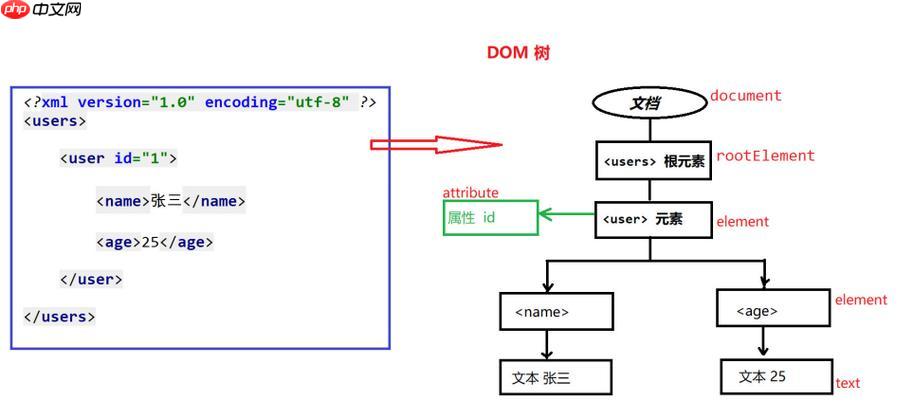
XPath的轴(axis)是定位XML或HTML文档中节点关系的核心机制,它定义了我们如何从当前上下文节点出发,沿着特定的方向去寻找其他节点。简单来说,它们就是指明“你要往哪个方向找”的导航符,比如找父节点、子节点、兄弟节点或者更远的祖先和后代。理解并灵活运用这些轴,能让你的XPath表达式变得异常强大和精准。
XPath的轴类型主要有以下几种,每种都有其独特的用途和适用场景:
self 轴: 顾名思义,它指向上下文节点本身。用途: 当你需要对当前节点进行筛选或进一步操作时,比如self::div[@id='target'],这通常用于在已经定位到某个节点集后,再对其进行条件过滤。child 轴: 选择上下文节点的直接子元素。用途: 这是最常用的一种,比如child::div会选择当前节点下所有的div子元素。简写形式就是直接写元素名,如div。parent 轴: 选择上下文节点的直接父元素。用途: 向上溯源,找到某个元素的直接容器,例如parent::div可以找到当前节点的父级div。简写是..。ancestor 轴: 选择上下文节点的所有祖先元素,包括父元素、父的父元素,直到文档根节点。用途: 当你需要找到某个元素的上层所有特定类型的容器时,比如ancestor::div会找到所有作为当前节点祖先的div元素。ancestor-or-self 轴: 选择上下文节点本身及其所有祖先元素。用途: 结合了self和ancestor,常用于需要包含自身进行条件判断或选择的场景。descendant 轴: 选择上下文节点的所有后代元素(子元素、孙元素等)。用途: 向下遍历,寻找某个区域内的所有特定元素,例如descendant::a会找到当前节点下所有层级的a标签。简写是//。descendant-or-self 轴: 选择上下文节点本身及其所有后代元素。用途: 同样是结合了self和descendant,当你需要在一个大块内容中搜索某个元素,且这个元素可能就是当前大块本身时,它就很有用。following-sibling 轴: 选择上下文节点之后的所有同级兄弟元素。用途: 在同一层级上,定位到某个元素后面的兄弟节点,例如following-sibling::p会选择当前p标签后面所有的同级p标签。preceding-sibling 轴: 选择上下文节点之前的所有同级兄弟元素。用途: 与following-sibling相反,定位到某个元素前面的兄弟节点。following 轴: 选择文档中位于上下文节点之后的所有元素,无论它们是否是兄弟节点。用途: 范围更广,适用于需要查找当前节点之后,但不在同一父级下的任何元素。preceding 轴: 选择文档中位于上下文节点之前的所有元素,无论它们是否是兄弟节点。用途: 与following轴相反,查找当前节点之前,但不在同一父级下的任何元素。attribute 轴: 选择上下文节点的所有属性。用途: 用于定位元素的属性,例如attribute::id会选择当前元素的id属性。简写是@。
XPath轴在复杂文档结构中如何提高定位效率?
在我看来,XPath轴的真正威力,在于它能让你在面对那些没有清晰ID或Class名,或者结构动态变化的网页时,依然能保持一种优雅的定位能力。想象一下,如果一个网站的元素ID是随机生成的,或者你想要找的元素总是在某个特定标题下面,但这个标题本身没有固定位置,这时候,轴就成了救命稻草。
传统上,我们可能会写一长串的绝对路径,比如/html/body/div[2]/div[1]/ul/li[3]/a。这种路径脆弱不堪,页面结构稍有变动就可能失效。而使用轴,我们可以从一个相对稳定的点出发,比如//h2[text()='相关产品'],然后利用following-sibling::div去定位其后的产品列表容器,或者用descendant::a去找到其中的链接。这种方式,就像是你在一个陌生的城市,不是死记硬背每一条街道的门牌号,而是记住“从这个地标建筑出来,沿着这条路走,第三个路口右转,就是我要找的地方”。它提供了一种基于关系的导航,这种关系往往比绝对位置更稳定、更具语义。尤其是在处理嵌套层级很深,或者需要根据某个特定元素的上下文来定位另一个元素时,轴能极大地简化表达式,提高其健壮性。
选择合适的XPath轴有哪些考量?
选择合适的XPath轴,其实是在做一次“导航策略”的制定。我通常会从以下几个角度去思考:
首先,你和目标节点的关系是什么? 这是最直接的判断依据。目标是我的父级?子级?还是同一层的兄弟?如果目标是我的子孙,但具体在哪一层不确定,那descendant轴就比child轴更合适。如果目标是我的父辈,且我需要向上追溯多层,ancestor轴就是首选。
其次,目标的唯一性如何? 如果目标在多个方向上都可能存在,那么选择一个能尽可能缩小搜索范围的轴,并结合谓语(predicates)进行精确过滤,会是更好的策略。比如,在一个列表项中,你可能有很多div子元素,但只有一个div带有特定的类名,这时child::div[@class='item-detail']就比简单的child::div更明确。
再者,文档结构是否稳定? 如果某个区域的结构经常变动,那么过度依赖following-sibling或preceding-sibling可能风险较高,因为它们的顺序可能会变。在这种情况下,尝试寻找一个更稳定的祖先节点,然后利用descendant轴向下搜索,或者利用following轴跳过不稳定的中间结构,可能是更稳妥的做法。
最后,表达式的阅读和维护成本。 虽然某些复杂的轴组合能实现目的,但如果能用更简洁、更直观的轴表达,我会倾向于后者。毕竟,XPath表达式写出来是给人看的,也是要维护的。过于绕弯子的路径,哪怕能跑,也增加了未来的维护难度。
XPath轴与谓语(Predicates)结合使用的技巧?
XPath轴和谓语(Predicates)是绝配,它们的关系就像是“方向”和“筛选条件”。轴先定义了一个方向和一组潜在的节点,而谓语则在这个节点集上进行二次筛选,精确定位到你真正想要的那个或那些节点。没有谓语,轴可能返回一大堆你并不关心的节点;没有轴,谓语就失去了作用的上下文。
一个常见的模式是轴::节点测试[谓语]。例如:
定位特定属性的祖先: ancestor::div[@id='main-content']。这里,ancestor::div找到了所有的div祖先节点,然后[@id='main-content']过滤出其中ID为main-content的那一个。这比从根节点一路写下来找这个ID要灵活得多,因为你不需要知道它在第几层。寻找特定位置的兄弟节点: following-sibling::p[1]。这会找到当前节点之后第一个同级的p标签。如果你想找第二个,就是[2]。这种基于位置的筛选在处理列表或表格时非常有用。在后代中查找包含特定文本的链接: descendant::a[contains(text(), '下载')]。descendant::a会找出所有a标签后代,[contains(text(), '下载')]则筛选出那些链接文本中包含“下载”字样的。这对于查找功能性链接非常实用。结合多个条件筛选父级: parent::div[preceding-sibling::h3[text()='产品详情']]。这个稍微复杂一点,它先找到当前节点的父级div,然后在这个div上再加一个条件:这个div的前面必须有一个文本为“产品详情”的h3兄弟节点。这种方式可以处理非常具体的上下文关系。
在实践中,我发现将轴和谓语结合使用,是构建健壮且可读性强的XPath表达式的关键。它允许你从一个已知点出发,像侦探一样,一步步缩小范围,最终锁定目标。关键在于,你要清楚轴帮你划定了哪个“区域”,而谓语则在这个区域内帮你“指认”了具体的目标。
以上就是XPath的轴(axis)有哪些类型?各有什么用途?的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1429838.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























