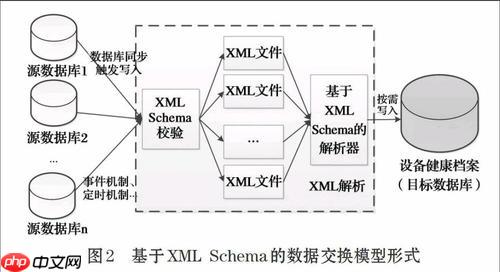
XML与关系数据库映射需根据数据结构和业务需求选择扁平化、父子表、聚合列等策略,结合数据库原生XML/JSON支持与混合建模,通过批量操作、事务管理、索引优化及增量同步等手段,在保证数据一致性的同时提升同步性能。
XML与关系数据库的映射,本质上是两种不同数据模型之间的“翻译”过程。XML以其树状、层级化的特性,非常适合描述半结构化数据和复杂文档;而关系数据库则以其表格、扁平化的结构和严格的模式,擅长处理结构化、规范化的数据。这个过程并非简单的复制粘贴,更多的是一种结构上的重塑和语义上的对齐,它没有放之四海而皆准的银弹,更多是根据具体业务场景、数据复杂度和性能要求进行权衡和设计。
解决方案
将XML数据映射到关系数据库,或者反之,通常涉及以下几种策略,每种都有其适用场景和需要考量的点。
从XML到关系数据库:
扁平化映射 (Flattening): 这是最直观的方式。对于结构相对简单、层级不深的XML,我们可以将其元素和属性直接映射到关系表中的列。例如,一个
Alicealice@example.com
可以直接映射到
Users
表的一行,包含
id
,
Name
,
三列。但这种方式在遇到复杂嵌套时会显得力不从心。
父子表映射 (Parent-Child Table Mapping): 当XML结构出现嵌套,例如一个订单包含多个订单项时,我们会自然地联想到关系数据库中的主从表结构。一个XML元素映射到主表,其嵌套的重复子元素则映射到一张或多张子表,通过外键(通常是主表的ID)与主表关联。这很符合关系型范式,但缺点是查询时需要进行多表连接,性能上可能有所损耗。
聚合列存储 (Aggregated Column Storage): 有时候,XML中的某些嵌套结构并非独立实体,或者我们不经常需要对其进行深入查询。这时,可以考虑将这部分XML内容作为字符串(如CLOB/TEXT类型)或数据库原生支持的XML/JSON类型(例如SQL Server的
XML
类型,PostgreSQL的
JSONB
类型)直接存储在父表的一个列中。这种方式减少了表连接,但对这部分数据的查询和更新可能需要特殊的函数或语法,且索引支持可能有限。我个人在处理一些配置数据或日志信息时,倾向于这种做法,因为它足够灵活,且能保留原始XML的完整性。
混合策略与对象关系映射 (ORM): 实际项目中,往往是上述几种策略的混合使用。对于核心业务数据,我们可能采用父子表映射以保证数据规范性和查询效率;对于非核心或高度可变的扩展信息,则可能使用聚合列。在编程层面,像Java的JAXB、Python的ElementTree或lxml等库,可以帮助我们将XML反序列化为程序中的对象模型,然后通过ORM框架(如Hibernate, SQLAlchemy)将这些对象持久化到关系数据库中。这种方式极大地简化了开发工作,但需要对ORM的映射规则有深入理解,以避免性能陷阱。
从关系数据库到XML:
SQL查询生成XML (SQL Query to XML): 许多现代关系数据库都提供了直接从SQL查询结果生成XML的功能。例如,SQL Server的
FOR XML
子句(
RAW
,
AUTO
,
EXPLICIT
,
PATH
模式),Oracle的
XMLELEMENT
,
XMLAGG
等函数。这些功能强大且高效,能够直接在数据库层面完成大部分XML构建工作,减少了应用层的数据传输和处理开销。这是我首选的方案,尤其是当XML结构与数据库表结构有一定对应关系时。
编程语言构建XML (Programmatic XML Generation): 当需要生成的XML结构非常复杂,或者需要进行大量业务逻辑判断才能确定XML内容时,通常会在应用层通过编程语言来构建XML。这涉及到从数据库查询数据,然后使用DOM(Document Object Model)或SAX(Simple API for XML)解析器(或者更现代的StAX、XMLStreamWriter等)API来动态组装XML文档。这种方式灵活性最高,但开发成本和维护成本也相对较高,且可能面临性能瓶颈(尤其是处理大量数据时)。
XSLT转换 (XSLT Transformation): 如果关系数据库的数据首先被转换为一种“中间”的XML格式(可能比较通用或扁平),然后需要将其转换为另一种特定结构的XML,那么XSLT(Extensible Stylesheet Language Transformations)就派上用场了。XSLT是一种专门用于XML到XML转换的语言,它能高效、声明式地完成复杂的结构重塑和数据格式化。
面对复杂的XML嵌套结构,关系数据库该如何高效应对?
当XML的嵌套层次变得很深,或者存在大量重复的子节点时,关系数据库的传统扁平化策略会遇到挑战。我个人的经验是,高效应对的关键在于识别核心实体与非核心扩展信息,并采用混合建模。
首先,将XML中的核心业务实体及其直接属性映射到主表。比如一个产品XML,产品ID、名称、价格是核心,放到
Products
表。
其次,对于可重复的、有明确业务含义的嵌套结构,创建独立的子表。例如,产品可能有多个“特性”(
),那就创建一个
ProductFeatures
表,通过
ProductID
外键关联。这里要注意的是,不要过度碎片化,如果一个嵌套结构只出现一次且字段不多,可以考虑将其字段提升到父表,或者作为JSON/XML字符串存储。我见过一些系统,把每个XML元素都映射成一张表,结果导致几十上百张表,查询时需要大量的JOIN,性能堪忧,维护起来更是噩梦。
再者,利用数据库的原生XML/JSON支持。如果你的数据库(如SQL Server, PostgreSQL, MySQL 8+)提供了XML或JSON数据类型,对于那些结构多变、查询不频繁、或只做简单键值对检索的嵌套部分,直接以XML或JSON字符串的形式存储在一个列中,是非常高效且灵活的方案。这样既保留了原始的层级信息,又避免了创建过多表。PostgreSQL的
JSONB
类型在这方面表现尤为出色,因为它支持索引和丰富的查询函数。
最后,考虑物化视图或预聚合。对于那些需要频繁查询的复杂路径,如果通过多表JOIN才能得到结果,可以考虑创建物化视图来预先计算和存储JOIN后的结果。这虽然增加了存储空间和数据同步的复杂性(物化视图需要定期刷新),但在读密集型场景下能显著提升查询性能。
映射过程中常见的数据类型不匹配和空值问题如何处理?
数据类型不匹配和空值问题是XML与关系数据库映射中绕不开的坑,它们常常导致数据转换失败或数据语义的丢失。
数据类型不匹配:
XML本身是半结构化的,其元素或属性的值通常被视为字符串,即使它们在语义上代表数字、日期或布尔值。而关系数据库则对每列有严格的数据类型定义。
显式类型转换: 这是最常见的处理方式。在映射代码中,我们需要明确地将XML中的字符串值转换为数据库目标列的相应类型。例如,XML中的
"2023-10-26"
要转换为数据库的
DATE
或
DATETIME
类型;
"123.45"
要转换为
DECIMAL
或
FLOAT
。这里需要特别注意格式兼容性,比如日期格式,XML可能用
YYYY-MM-DD
,数据库可能要求
YYYY/MM/DD
,或者包含时区信息。
默认值与错误处理: 如果XML中某个值无法转换为目标数据类型(例如,将
"abc"
转换为整数),我们不能简单地让程序崩溃。一种策略是为数据库列设置一个合理的默认值,并在转换失败时使用它;另一种更健壮的方式是记录错误日志,将原始的XML片段连同错误信息一并记录下来,以便后续人工审查和修正,同时允许其他部分的数据继续处理。
XML Schema验证: 在进行映射之前,如果XML有对应的Schema定义,强烈建议先进行Schema验证。这能确保XML文档的结构和数据类型符合预期,提前发现潜在的类型不匹配问题,从而避免在映射阶段才暴露错误。
空值问题:
XML中表示“空”的方式有很多种:元素缺失、空元素(
)、空字符串(
)、或者属性缺失。关系数据库中则通常用
NULL
来表示空。
XML缺失元素/属性: 当XML中某个元素或属性完全不存在时,这通常被映射到关系数据库中的
NULL
。这是最直接和普遍的处理方式。
XML空元素/空字符串: 这是比较棘手的情况。
和
在XML解析时通常都表示一个空值。是将其映射为数据库的
NULL
,还是空字符串
''
?这需要根据具体的业务语义来决定。如果业务上“空”和“不存在”是等价的,那么映射为
NULL
。如果业务上“空字符串”有其特定含义(例如,一个可选的备注字段可以为空字符串但不能为NULL),那么就映射为
''
。我个人倾向于在不确定时映射为
NULL
,因为
NULL
在数据库中通常有更好的索引和查询优化表现。
数据库NULL到XML: 在从关系数据库生成XML时,如果某个列的值是
NULL
,通常有两种处理方式:
忽略该元素/属性: 这是最常见的做法,即不生成对应的XML元素或属性。生成空元素/属性: 例如
或
。这通常在XML Schema明确要求该元素必须存在,即使其内容为空时才使用。
处理这些问题,关键在于明确的业务规则定义和鲁棒的错误处理机制。没有银弹,只有根据具体场景的细致考量。
如何在保证数据一致性的前提下,优化XML与关系数据库之间的同步性能?
在XML与关系数据库之间进行数据同步,尤其是在数据量较大、频率较高的情况下,性能和数据一致性是两个核心挑战。
批量操作而非逐条处理: 这是提升性能的黄金法则。无论是将XML数据写入数据库,还是从数据库读取数据生成XML,都应尽量避免在循环中执行单条SQL语句。
写入: 使用数据库连接池,采用批量插入(
INSERT INTO ... VALUES (...), (...), ...
)或批量更新(
UPDATE ... WHERE ID IN (...)
)语句,或者利用数据库提供的
COPY
命令(PostgreSQL)或
BULK INSERT
(SQL Server)等批量加载工具。读取: 从数据库查询数据时,尽量使用
JOIN
操作一次性获取所有相关数据,而不是先查询主表,再循环查询子表(经典的N+1查询问题)。
事务管理: 确保数据一致性的基石。将一个完整的XML文档的解析和所有相关数据库操作(包括多个表的插入、更新、删除)封装在一个数据库事务中。这意味着要么所有操作都成功并提交,要么所有操作都失败并回滚。这样可以避免部分数据写入成功、部分失败导致的数据不一致状态。
索引优化: 关系数据库的性能离不开合理的索引。
外键索引: 确保所有外键列都有索引,这对于父子表之间的
JOIN
操作至关重要。查询条件索引: 对XML映射到数据库后,经常作为查询条件的列建立索引。XML数据类型索引: 如果你在数据库中使用了原生XML数据类型存储,某些数据库允许对XML内容进行索引(例如SQL Server的XML索引),这能显著加速XPath/XQuery查询。
增量同步策略: 对于频繁更新的XML数据,全量同步往往效率低下。
版本控制/时间戳: 在XML文档或其对应的数据库表中引入版本号或最后更新时间戳。在同步时,只处理那些版本号更高或更新时间更晚的数据。差异比较: 在应用层比较新旧XML文档的差异,只生成针对这些差异的数据库操作(插入、更新、删除)。这需要一个高效的XML差异比较算法。
异步处理与消息队列: 对于对实时性要求不高的同步任务,可以考虑将XML解析和数据库写入操作解耦。将待处理的XML文档或其元数据放入消息队列(如Kafka, RabbitMQ),由后台的消费者服务异步地进行数据库写入。这样可以避免同步操作阻塞前端应用,同时通过增加消费者实例来横向扩展处理能力。
数据库连接池与参数化查询: 确保应用使用数据库连接池来管理数据库连接,避免频繁地建立和关闭连接。同时,所有SQL操作都应使用参数化查询,这不仅可以防止SQL注入,还能让数据库更好地缓存执行计划,提升性能。
合理的数据模型设计: 回到最初,一个好的数据库模型设计,能够减少不必要的JOIN,降低数据冗余,本身就是对性能的最大优化。在XML映射到关系数据库时,避免过度范式化或反范式化,找到一个平衡点。
这些策略的组合使用,才能在保障数据一致性的前提下,最大限度地提升XML与关系数据库之间的数据同步性能。
以上就是XML与关系数据库如何映射?的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1430771.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫