XML注释不能嵌套,因解析器会将首个–>视为注释结束,导致后续内容被错误解析,这是XML严格语法设计的一部分,以确保解析的确定性和数据完整性。
 <!– 这是一个内部的、被破坏的注释 –>
<!– 这是一个内部的、被破坏的注释 –>

XML注释不能嵌套,因解析器会将首个–>视为注释结束,导致后续内容被错误解析,这是XML严格语法设计的一部分,以确保解析的确定性和数据完整性。
<!– 这是一个内部的、被破坏的注释 –>
是的,这有点笨拙,需要手动修改,但当你需要快速注释掉一大段包含现有注释的XML时,这招能骗过解析器,让它不再把这些“被破坏”的标记当作真正的注释边界。
利用CDATA节: 另一个技巧是利用CDATA节。如果你要注释掉的内容本身包含XML标记,包括注释标记,你可以先把它包在一个CDATA节里,然后注释掉整个CDATA节。CDATA节内部的内容会被解析器当作纯文本处理,不会解析其中的XML标记。
<!-- 暂时禁用以下包含XML和注释的配置块<![CDATA[ Some value ]]>-->
这种方式相当于把内部的XML结构“钝化”了,让解析器把它当作纯文本处理。虽然有点绕,但在特定场景下,比如临时禁用一个复杂的XML配置块时,它能派上用场。
重构注释逻辑: 当然,最“优雅”的方式,还是从源头解决问题。重新思考你的注释结构,避免需要嵌套的情况。也许你需要的是更细粒度的注释,只注释掉真正需要解释的部分,而不是大块地注释掉整个包含内部注释的结构。或者,对于需要长期禁用但又不删除的配置,可以考虑使用自定义的XML元素(如
...
),然后在应用程序层面忽略这些元素,而不是依赖注释机制。
XML和HTML在注释处理上的差异,深刻反映了它们各自的设计目标和哲学。
HTML的“宽容”:HTML,尤其是在浏览器端,对语法错误表现出惊人的“宽容”。你可能会发现,在HTML中,即使你写了
<!-- 外部注释 -->
这样的嵌套注释,浏览器通常也能“理解”并正确渲染页面,它会尽可能地尝试解析并显示内容,而不是直接报错。这背后是HTML作为“超文本”的哲学——它更注重内容的展示和容错性,即使代码不那么规范,也尽量不让用户看到一个破碎的页面。浏览器内置了复杂的错误恢复机制,能够猜测开发者的意图,并尝试修复不规范的标记。这种“尽力而为”的策略,使得HTML在面对各种手写或生成的不规范代码时,依然能保持良好的用户体验。
XML的“严谨”:但XML则完全不同。XML生来就是为了数据交换和结构化存储。它的解析器是“零容忍”的。任何不符合规范的语法,包括注释嵌套,都会被视为致命错误,导致整个文档无法被处理。这种严格性确保了XML文档在不同系统、不同解析器之间的一致性和互操作性,因为大家都在遵循同一套“死板”的规则。
XML的这种严谨性体现在:
无歧义解析: 严格的语法规则保证了XML文档在任何符合规范的解析器下都能被唯一地解析。这对于数据交换和自动化处理至关重要。数据完整性: 错误被视为致命的,意味着一旦文档有语法问题,它就不是一个“有效”的XML文档,不能被信任和处理。这有助于维护数据的完整性和可靠性。简化解析器实现: 严格的规则使得XML解析器的实现相对简单直接,不需要复杂的错误恢复逻辑,只需按照规范一步步匹配即可。
因此,XML的注释不能嵌套,正是其“严谨”哲学的一个缩影。它牺牲了开发者在某些场景下的“便利性”,换来了数据交换和结构化存储的“确定性”和“可靠性”。理解这一点,有助于我们更好地使用XML,并避免那些看似细微却可能导致严重问题的语法陷阱。
以上就是XML注释能否嵌套?的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1431088.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
CSS mask属性无法获取图片 在使用CSS mask属性时,可能会遇到无法获取指定照片的情况。这个问题通常表现为: 网络面板中没有请求图片:尽管CSS代码中指定了图片地址,但网络面板中却找不到图片的请求记录。 问题原因: 此问题的可能原因是浏览器的兼容性问题。某些较旧版本的浏览器可能不支持CSS…




overflow 导致 inline-block 元素错位解析 当多个 inline-block 元素并列排列时,可能会出现错位显示的问题。这通常是由于其中一个元素设置了 overflow 属性引起的。 问题现象 在不设置 overflow 属性时,元素按预期显示在同一水平线上: 不设置 overf…
网页中使用本地字体 本文将解答如何将本地安装字体应用到网页中,避免使用 src 属性直接引入字体文件。 问题: 想要在网页上使用已安装的“荆南麦圆体”字体,但 css 代码中将其置于第一位的“font-family”属性,页面仍显示“微软雅黑”字体。 立即学习“前端免费学习笔记(深入)”; 答案: …
特定 DIV 无法显示:用户代理样式表的困扰 当你在 Edge 浏览器中打开项目中的某个 div 时,却发现它无法正常显示,仔细检查样式后,发现是由用户代理样式表中的 display none 引起的。但你疑问的是,为什么会出现这样的样式表,而且只针对特定的 div? 背后的原因 用户代理样式表是由…
inline-block元素错位背后的原因 inline-block元素是一种特殊类型的块级元素,它可以与其他元素行内排列。但是,在某些情况下,inline-block元素可能会出现错位显示的问题。 错位的原因 当inline-block元素设置了overflow:hidden属性时,它会影响元素的…
解决 css mask 属性未请求图片的问题 在使用 css mask 属性时,指定了图片地址,但网络面板显示未请求获取该图片,这可能是由于浏览器兼容性问题造成的。 问题 如下代码所示: 立即学习“前端免费学习笔记(深入)”; icon [data-icon=”cloud”] { –icon-cl…
inline-block 元素错位成因剖析 在使用 inline-block 元素时,可能会遇到它们错位显示的问题。如代码 demo 所示,当设置了 overflow 属性时,a 标签就会错位下沉,而未设置时却不会。 问题根源: overflow:hidden 属性影响了 inline-block …
css 设置元素放大效果的疑问解答 原提问者在尝试给元素添加 10em 字体大小和过渡效果后,未能在进入页面时看到放大效果。探究发现,原提问者将 CSS 代码直接写在页面中,导致放大效果无法触发。 解决办法如下: 将 CSS 样式写在一个单独的文件中,并使用 标签引入该样式文件。这个操作与原提问者观…
元素设置 em 和 transition 后不放大 一个 youtube 视频中展示了设置 em 和 transition 的元素在页面加载后会放大,但同样的代码在提问者电脑上没有达到预期效果。 可能原因: 问题在于 css 代码的位置。在视频中,css 被放置在单独的文件中并通过 link 标签引…
width:100%在父元素为inline或inline-block下的显示问题 问题提出 当父元素为inline或inline-block时,内部元素设置width:100%会出现不同的显示效果。以代码为例: 测试内容 这是inline-block span 效果1:父元素为inline-bloc…
标题:基本数据类型大揭秘:了解主流编程语言中的分类 正文: 在各种编程语言中,数据类型是非常重要的概念,它定义了可以在程序中使用的不同类型的数据。对于程序员来说,了解主流编程语言中的基本数据类型是建立坚实程序基础的第一步。 目前,大多数主流编程语言都支持一些基本的数据类型,它们在语言之间可能有所差异…
从零开始学习CSS,掌握网页基本框架制作技巧 前言: 在现今互联网时代,网页设计和开发是一个非常重要的技能。而学习CSS(层叠样式表)是掌握网页设计的关键之一。CSS不仅可以为网页添加样式和布局,还可以为用户呈现独特且具有吸引力的页面效果。在本文中,我将为您介绍一些基本的CSS知识,以及一些常用的代…
在当今数字时代,互联网成为了人们生活中不可或缺的一部分。作为互联网的基本构成单位,网页承载着我们获取和分享信息的重要任务。而网页开发作为一门独特的技术,离不开一些必备的语言。本文将揭秘Web标准涵盖的语言,让我们一起了解网页开发所需的语言范围。 首先,HTML(HyperText Markup La…
Web标准中的语言大揭秘:掌握网页开发所需的语言有哪些? 随着互联网的快速发展,网页开发已经成为人们重要的职业之一。而要成为一名优秀的网页开发者,掌握网页开发所需的语言是必不可少的。本文将为大家揭示Web标准中的语言大揭秘,介绍网页开发所需的主要语言。 HTML(超文本标记语言)HTML是网页开发的…
了解Web标准的语言要点:常见的哪些语言应用在网页开发中? 随着互联网的不断发展,网页已经成为人们获取信息和交流的重要途径。而要实现一个高质量、易用的网页,离不开一种被广泛接受的Web标准。Web标准的制定和应用,涉及到多种语言和技术,本文将介绍常见的几种语言在网页开发中的应用。 首先,HTML(H…
探索Web标准语言的世界:网页开发中常用的语言有哪些? 在现代社会中,互联网的普及程度越来越高,网页已成为人们获取资讯、娱乐、交流的重要途径。而网页的开发离不开各种编程语言的应用和支持。在这个虚拟世界的网络,有许多被广泛应用的标准化语言,用于为用户提供优质的网页体验。本文将探索网页开发中常用的语言,…
Web标准是指互联网上的各个网页所需遵循的一系列规范,确保网页在不同的浏览器和设备上能够正确地显示和运行。这些标准包括HTML、CSS和JavaScript等语言。本文将深入解析Web标准涵盖的语言范围。 首先,HTML(HyperText Markup Language)是构建网页的基础语言。它使…
CSS 超链接属性解析:text-decoration 和 color 超链接是网页中常用的元素之一,它能够在不同页面之间建立连接。为了使超链接在页面中有明显的标识和吸引力,CSS 提供了一些属性来调整超链接的样式。本文将重点介绍 text-decoration 和 color 这两个与超链接相关的…
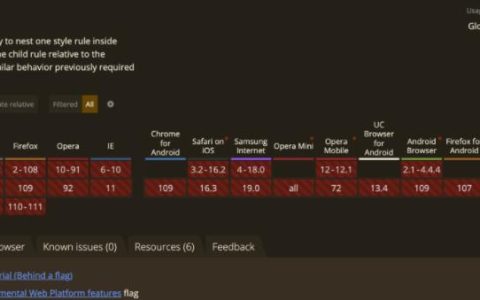
目前,CSS 原生嵌套语法处于开发者试用状态,CSS 工作组正在制定相关规范,Chrome 浏览器预计将于 112 版本正式推出 CSS 原生嵌套功能。 大家好,我是 CUGGZ。 最近在看 caniuse.com 时发现,Chrome 和 Edge 浏览器将在 109 版本实验性支持 CSS 原生…




每天10道题,100天后,搞定所有前端面试的高频知识点,加油!!!,在看文章的同时,希望不要直接看答案,先思考一下自己会不会,如果会,自己的答案是什么?想过之后再与答案比对,是不是会更好一点,当然如果你有比我更好的答案,欢迎评论区留言,一起探讨技术之美。 面试官:给定一个元素,如何实现水平垂直居中?…