简介
在系统设计中,有时我们需要对输入数据进行处理和转换,这些操作通常是独立的,处理后的数据会被放置到指定的输出中。
在日常工作中,常常会遇到这样的数据处理任务,这时可以采用数据流架构。
数据流架构在实际应用中有多种流形式,最常见的包括I/O流、I/O缓冲区和管道等。不同组件或模块通过这些流进行连接,数据的流向可以是带有循环的拓扑图、没有循环的线性结构或树形结构等。
数据流架构的主要目标是实现重用和便于修改。它适用于在顺序定义的输入和输出上进行一系列明确定义的独立数据转换或计算,例如编译器和业务数据处理应用程序。一般来说,有三种基本的数据流结构。
顺序批处理
顺序批处理是最常见也是最基础的数据流架构。数据作为一个整体,会依次通过各个处理单元,只有在前一个处理单元完成处理后,数据才会进入下一个处理单元。
我们来看一下顺序批处理的流程图:
 数据作为一个整体,从一个处理器传递到另一个处理器。主要通过临时文件进行交互。每个处理器的输出作为下一个处理器的输入,经过多次数据处理,最终得到所需的结果。
数据作为一个整体,从一个处理器传递到另一个处理器。主要通过临时文件进行交互。每个处理器的输出作为下一个处理器的输入,经过多次数据处理,最终得到所需的结果。
顺序批处理的优点是每个处理都是独立的,它们组合起来形成一个整体顺序处理架构。
当然,缺点是不能并行,只能串行执行,吞吐量也不够。各个处理器之间仅通过中间文件进行交互,交互程度较低。
管道和过滤器
在顺序批处理中,各个处理器的功能差异较大,通常它们是不同的系统。如果在同一个系统中处理数据流任务,则需要使用管道和过滤器。
Java 8引入了stream和管道的概念。一个集合可以转换成stream,通过对stream的操作,可以对整个数据流进行变换,最终得到想要的结果。
这种方法强调连续组件对数据的增量转换。在这种方法中,数据流由数据驱动,整个系统可以分解为数据源、过滤器、管道和数据接收器等组件。
模块之间的连接是数据流,它是先进/先出的缓冲区,可以是字节流、字符流或任何其他类型的流。这种架构的主要优点在于其并发和增量执行。
在这种模式下,最重要的组件是过滤器,过滤器是独立的数据流转换器。它转换输入数据流的数据,对其进行处理,并将转换后的数据流写入管道以供下一个过滤器处理。它以增量模式工作,一旦数据通过连接的管道到达,它就会开始工作。
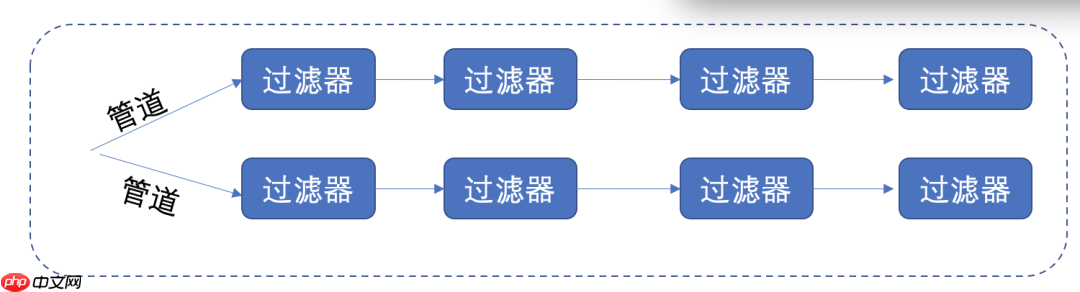 上图中的数据从管道出发,经过一个个的过滤器,最终得到处理后的结果。
上图中的数据从管道出发,经过一个个的过滤器,最终得到处理后的结果。
过滤器有两种类型,分别是主动型过滤器和被动型过滤器。主动型过滤器可以主动从管道中拉取数据,并将处理后的数据推出。这种模式主要用于UNIX管道。而被动型过滤器则负责接收管道推入的数据。
这种模式的优点是可以提供高并发和高吞吐量。缺点是不适合动态交互。
流程控制
还有一种模式,既不是批量处理也不是管道模式,它是根据输入内容的不同,来控制不同的执行流程。类似于我们在程序中使用的判断语句。
总结
以上介绍了几种数据流的架构方式,希望大家能够喜欢。
以上就是架构之:数据流架构的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/155336.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫