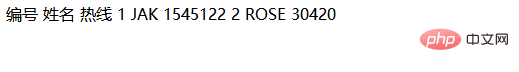本文旨在解决使用 XPath 提取特定文本节点时遇到的问题,特别是在目标文本节点前存在其他文本节点(例如空白字符)的情况下。我们将介绍如何利用 XPath 1.0 的 substring-after 函数来精确提取所需文本,避免提取到不需要的前导字符或空白。通过本文的学习,你将掌握一种有效的 XPath 文本提取技巧。
在使用 XPath 从 HTML 或 XML 文档中提取文本时,我们经常会遇到目标文本节点前存在其他文本节点的情况,例如空白字符或者分隔符。直接使用 //span[@class=”meta”]/text() 这样的 XPath 表达式可能无法精确提取到我们想要的文本,因为该表达式会返回所有文本节点,而在 XPath 1.0 中,如果将节点集合作为字符串参数传递给函数,则只会使用第一个节点的值。
在这种情况下,substring-after 函数提供了一种有效的解决方案。该函数可以从一个字符串中提取指定分隔符之后的部分。
示例
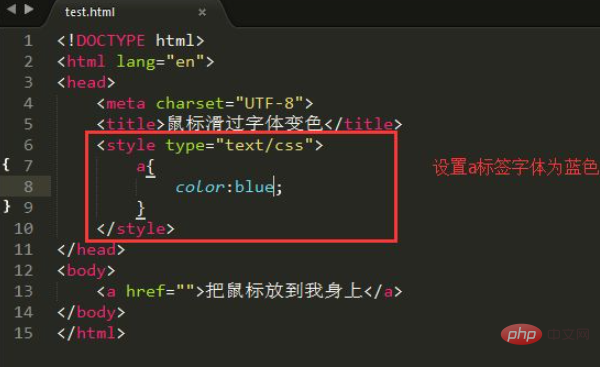
假设我们有以下 HTML 代码片段:
我们的目标是提取 “Aug 7, 2019 at 9:34 am ET” 这段文本。直接使用 //span[@class=”meta”]/text() 可能会返回包含 ” |” 前缀的文本,或者由于前导空白字符而提取失败。
以下 XPath 表达式使用 substring-after 函数来解决这个问题:
substring-after(//span[span/a/@rel="author"],' |')
表达式解析:
//span[span/a/@rel=”author”]:首先,我们使用这个 XPath 表达式选择包含作者链接的 span 元素。这里的 span/a/@rel=”author” 用于定位包含具有 rel=”author” 属性的 a 标签的 span 元素。这样可以确保我们选择的是正确的 span 元素。substring-after(…,’ |’):然后,我们将选定的 span 元素的字符串值作为 substring-after 函数的第一个参数,并将 ‘ |’ 作为第二个参数,表示我们要提取分隔符 ” |” 之后的部分。
结果:
该 XPath 表达式将返回:
Aug 7, 2019 at 9:34 am ET
注意事项:
确保分隔符在目标文本中存在且唯一。如果分隔符不存在,substring-after 函数将返回空字符串。substring-after 函数区分大小写。如果分隔符的大小写不正确,将无法提取到正确的文本。此方法适用于 XPath 1.0。在 XPath 2.0 及更高版本中,有更灵活的字符串处理函数可用。
总结:
substring-after 函数是 XPath 1.0 中一个强大的工具,可以帮助我们精确提取字符串中特定分隔符之后的部分。在处理包含前导字符或空白的文本节点时,该函数可以有效地避免提取到不需要的内容。通过结合具体的 HTML 结构和目标文本的特点,我们可以灵活运用 substring-after 函数,实现精确的文本提取。
以上就是使用 XPath 提取文本节点:substring-after 函数的应用的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1582598.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫