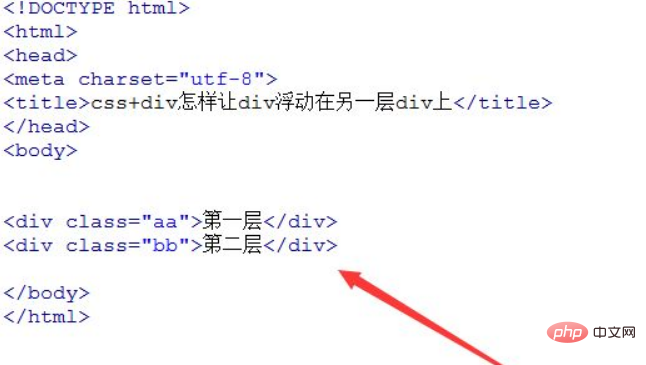
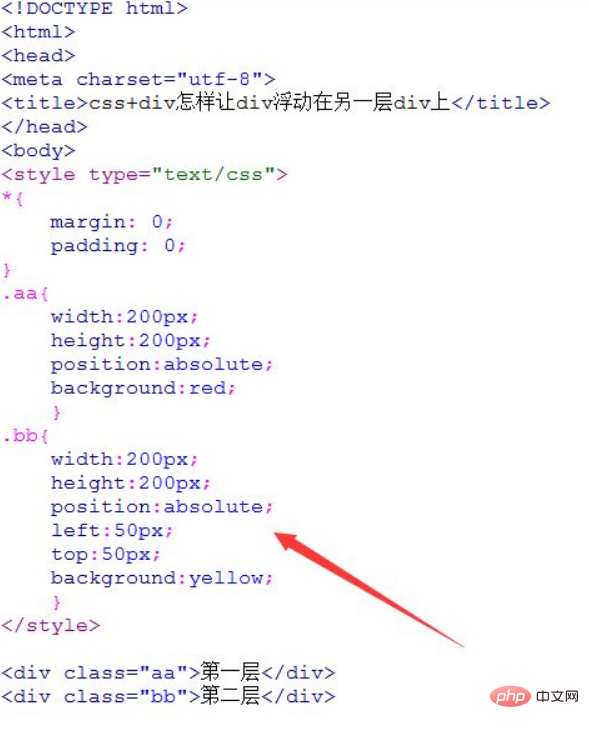
的非标准行为与浏览器错误恢复” />
的非标准行为与浏览器错误恢复” />
`/ >`并非html标准中有效的自闭合标签。其内部的斜杠字符被html解析器视为错误并忽略,导致“实际上被解析为普通的“开始标签。当这些“标签没有对应的结束标签时,现代浏览器会启动其健壮的错误恢复机制,在父元素闭合时自动补全缺失的“,从而在视觉上产生空span的效果。依赖此非标准行为不可取,建议使用html注释或`
在HTML开发中,为了提升源代码的可读性,开发者常会尝试在不影响页面渲染效果的前提下对代码进行格式化,例如在长文本行中插入换行符。一种常见的尝试是使用形如的结构来分割源代码行,期望它能作为一个不产生视觉输出的空元素。然而,这种做法的背后隐藏着HTML解析器的非标准行为和浏览器的错误恢复机制。本文将深入探讨为何会产生空span的视觉效果,并提供标准的替代方案。
非标准语法:的解析真相
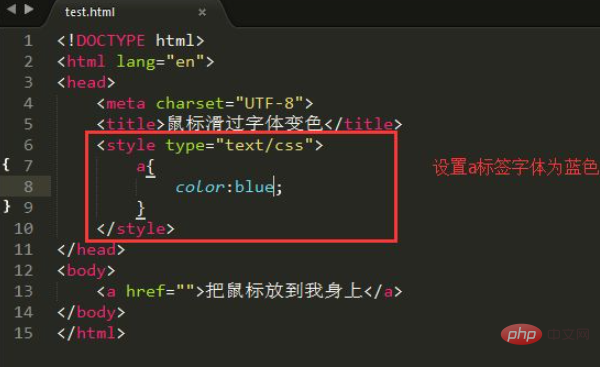
首先需要明确的是,并非HTML标准中定义的有效自闭合标签。在HTML中,只有一小部分元素被定义为空元素(void elements),它们不需要结束标签,例如、
、等。元素不属于空元素,它是一个内容模型为“短语内容”的非空元素,通常用于包裹文本或行内元素,并且必须有一个匹配的结束标签。
那么,为何在浏览器中会“正常”工作,表现为一个空span呢?这与HTML解析器的容错机制有关。根据HTML Living Standard的规定,当解析器处理标签时,如果遇到形如的结构,其中的斜杠/会被视为一个解析错误并被忽略。
具体来说,在解析一个标签的开始部分时,HTML解析器会尝试识别标签名和属性。HTML规范中的“获取属性(get an attribute)”算法规定,在解析属性时,如果遇到0x2F(/)字符,解析器会将其跳过并继续查找下一个字节。这意味着,对于,解析器会:
立即学习“前端免费学习笔记(深入)”;
识别到标签名 span。遇到 / 字符,将其作为无效字符跳过。遇到空格字符,跳过。遇到 > 字符,认为标签结束。
因此,最终被解析器处理为普通的开始标签,而不是一个自闭合标签。
示例:原始HTML片段
Spanintheplacewhereyoulive.
在浏览器内部,中的每个实例都会被解析为。
浏览器错误恢复:缺失结束标签的处理
既然被解析为,而是一个非空元素,它就要求一个匹配的结束标签。然而,在上述示例中,我们并没有提供这些结束标签。这时,现代浏览器强大的错误恢复机制就会介入。
HTML解析器在构建DOM树时,如果发现某些非空元素缺少了对应的结束标签,它不会直接报错或停止渲染。相反,它会尝试“猜测”并插入缺失的标签以形成一个合法的DOM结构。这种行为在HTML Living Standard中也有明确的规定,例如在“关闭p元素(close a p element)”的规则中提到:
生成隐含的结束标签,p元素除外。如果当前节点不是p元素,则这是一个解析错误。从开放元素栈中弹出元素,直到p元素被弹出。
这意味着,当解析器遇到父元素(如
)的结束标签
时,它会检查其内部是否有未闭合的非空元素。在这种情况下,所有的标签都会被自动推断并插入结束标签,从而形成一个嵌套的、结构完整的DOM。
解析后的规范化HTML结构(概念性):
Spanintheplacewhereyoulive.
正是这种解析错误忽略和自动补全结束标签的组合行为,使得在视觉上产生了空span的效果,并且不引入额外的空格。
不推荐的实践与标准替代方案
尽管这种方式在某些浏览器中看似有效,但强烈不建议依赖这种非标准的解析行为。原因如下:
跨浏览器兼容性风险: 尽管主流浏览器在错误恢复方面趋于一致,但不同浏览器、不同版本或未来标准更新可能导致行为差异,从而引入难以调试的问题。代码可维护性差: 依赖非标准行为会使代码难以理解,增加维护成本,并可能误导其他开发者。语义不明确: 使用不符合其语义的标签来解决格式问题,会损害HTML的语义结构。
为了实现源代码格式化而不影响页面渲染,或为了在不引入空格的情况下允许文本断行,应采用以下标准且语义明确的替代方案:
1. 源代码格式化:使用HTML注释
如果仅仅是为了在HTML源代码中进行换行,以提高可读性,而不希望在渲染结果中产生任何影响(包括空格),最标准且推荐的做法是使用HTML注释。注释在解析时会被完全忽略,不会对DOM结构和渲染结果产生任何影响。
示例:使用HTML注释进行源代码换行
Spanintheplacewhereyoulive.
渲染结果:Spanintheplacewhereyoulive.
2. 文本断词:使用元素
如果你的目标是在长单词或长路径中提供浏览器一个可选的换行点,而不引入额外的空格,应使用
示例:使用
Continuous
/this/is/a/path/that/seems/not/to/end/it/goes/on/and/on/my/friend/someone/started/typing/it/not/knowing/what/it/was/and/they/will/continue/typing/a/long/time/because
Broken Up
/this/
is/a/ path/ that/ seems/ not/to/ end/ it/goes/ on/and/ on/my/ friend/ someone/ started/ typing/ it/ not/ knowing/ what/ it/was/ and/ they/ will/ continue/ typing/a/ long/ time/ because/
在这个例子中,
总结
之所以能在浏览器中“工作”,是HTML解析器处理非标准语法和浏览器健壮的错误恢复机制共同作用的结果。解析器会忽略标签内的斜杠,将其视为普通的开始标签,随后浏览器会自动补全缺失的结束标签。然而,依赖这种非标准行为是不可取的。为了确保代码的健壮性、可维护性和跨浏览器兼容性,开发者应始终遵循HTML标准,使用HTML注释进行源代码格式化,或使用
以上就是HTML解析机制详解:的非标准行为与浏览器错误恢复的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1585728.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫