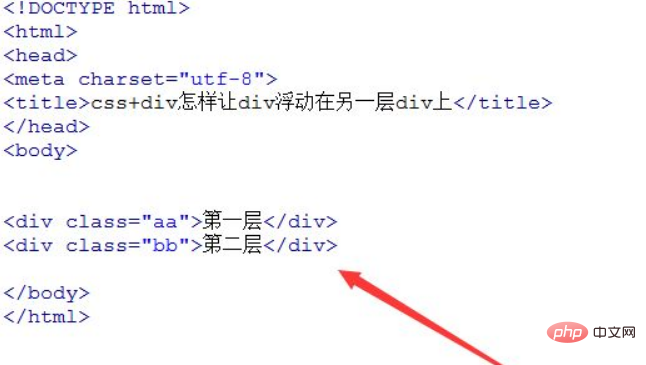
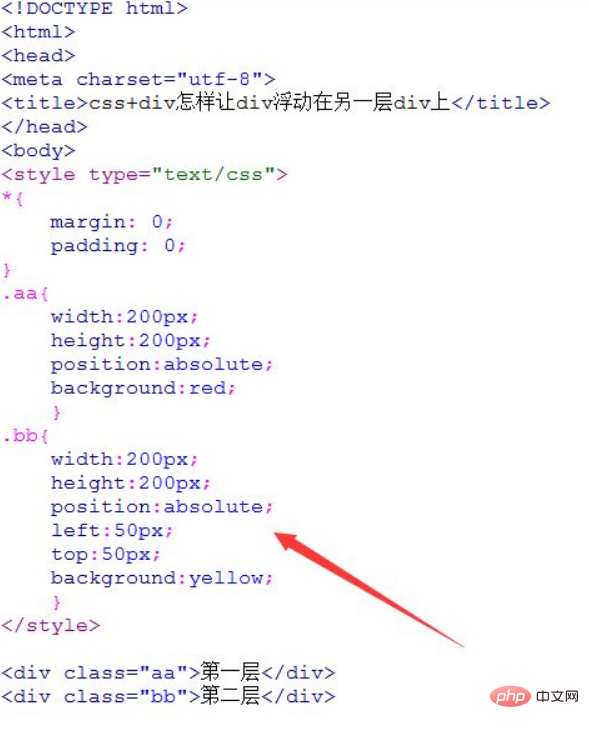
答案:构建分布式HTML采集系统需整合任务调度、去重、存储与监控模块,以Redis为核心协调任务分发与去重,通过消息队列实现负载均衡,结合布隆过滤器减少重复抓取,利用无状态工作节点支持弹性扩展,依托ZooKeeper保障高可用,并集成反爬适配与请求控制机制,确保系统稳定高效运行。

要实现HTML数据的分布式采集,核心是构建一个高效、可扩展且稳定的分布式爬虫系统。这类系统能将抓取任务分散到多个节点,提升采集速度、降低单点压力,并具备容错能力。以下是关键设计思路与架构组成。
分布式爬虫的核心组件
一个典型的分布式HTML爬虫包含以下几个核心模块:
任务调度中心(Task Manager):负责管理待抓取的URL队列,分配任务给工作节点,通常使用消息队列或分布式缓存(如Redis)实现统一调度。 爬虫工作节点(Worker Nodes):多个分布在不同机器上的采集程序,从任务队列中获取URL,发送HTTP请求,解析HTML内容并提取所需数据。 去重与指纹机制(Deduplication):通过URL哈希或内容指纹避免重复抓取,通常将已抓取的URL存储在Redis或布隆过滤器中。 数据存储层(Storage):将采集到的结构化数据写入数据库(如MySQL、MongoDB)或文件系统(如HDFS),支持后续分析处理。 监控与日志系统:实时监控各节点状态、任务进度和异常情况,便于调试与运维。
基于消息队列的任务分发机制
为实现任务的高效分发与负载均衡,推荐使用消息中间件进行解耦:
使用Redis的List或Sorted Set作为待抓取URL队列,支持多消费者并发读取。 采用RabbitMQ或Kafka适用于大规模、高吞吐场景,提供更完善的消息确认与持久化机制。 每个工作节点启动后连接队列,拉取任务执行,完成后提交结果并反馈状态。
去重与协同控制策略
在分布式环境下,多个节点可能同时抓取相同页面,需有效防止资源浪费:
立即学习“前端免费学习笔记(深入)”;
利用Redis的SET或HyperLogLog结构存储已抓取URL的MD5或SHA1指纹。 引入布隆过滤器(Bloom Filter)在本地快速判断URL是否可能已存在,减少对中心存储的查询压力。 设置合理的URL规范规则(如去除参数顺序、统一大小写),提高去重准确率。
弹性扩展与故障恢复设计
系统应具备良好的伸缩性与容错能力:
工作节点无状态设计,可随时增减实例,由调度中心动态分配任务。 任务执行失败时自动重试,并记录错误日志供排查。 使用ZooKeeper或etcd实现节点健康检测与主控选举,保障调度中心高可用。 定期持久化任务队列和去重表,防止系统崩溃导致数据丢失。
基本上就这些。只要把任务分发、去重、存储和监控几个环节打通,用Redis做中枢协调,再部署多个爬虫客户端,就能搭建出一个稳定运行的分布式HTML采集系统。不复杂但容易忽略细节,比如反爬策略适配和请求频率控制,也得同步考虑进去。
以上就是HTML数据如何实现分布式采集 HTML数据分布式爬虫的架构设计的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1587574.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫