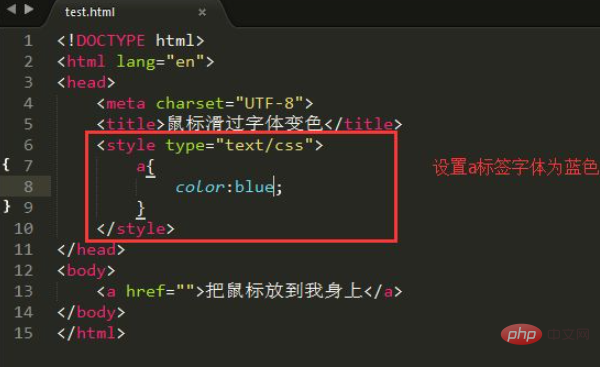
核心目标是将HTML转化为结构化特征,需提取标签层级、文本语义、属性交互信息,并通过向量化与降维构建模型输入,结合任务需求进行特征选择与噪声清洗。

处理HTML数据进行特征提取时,核心目标是将非结构化的网页内容转化为可用于机器学习模型的结构化特征。由于HTML本身包含标签、属性、嵌套结构和文本内容,直接使用原始HTML不利于建模,因此需要系统性地进行特征工程。
1. 提取标签结构与层级信息
HTML文档具有明显的树状结构,利用这一点可以提取出反映页面布局的特征:
标签类型统计:统计页面中不同标签(如
、、)出现的频次,作为页面内容类型的粗略判断依据。 标签嵌套深度:通过解析DOM树,计算最大嵌套层级或平均深度,有助于识别复杂布局或广告区块。 父子节点关系比例:例如统计下的数量,可帮助识别列表类内容。 标签路径频率:提取常见XPATH路径(如/html/body/div[2]/p),用于捕捉模板化结构。
2. 文本内容与语义特征提取
HTML中的可见文本往往携带关键信息,需从标签包裹的内容中提取语义特征:
去标签提取纯文本:使用BeautifulSoup或lxml去除脚本、样式等非展示内容,保留用户可见文本。 关键词与TF-IDF向量化:对提取的文本进行分词后,使用TF-IDF生成文本向量,作为分类或聚类输入。 标题与元信息提取:抓取
–
标签内容,这些通常是页面主题的核心表达。 链接密度与锚文本分析:计算单位面积内超链接数量,以及锚文本的词汇分布,用于判断是否为导航页或垃圾页面。
3. 属性与交互特征挖掘
HTML标签的属性字段常隐含重要行为线索:
立即学习“前端免费学习笔记(深入)”;
class/id命名模式分析:统计常用class前缀(如btn-、nav-),或使用NLP方法对class值做embedding表示。 事件监听属性检测:查找onclick、onload等属性,判断元素是否具备交互性。 资源引用特征:提取src(图片、脚本)、href(外部链接)的数量与域名分布,辅助判断页面可信度或媒体丰富度。
4. 结构化向量构造与降维技巧
原始提取的特征维度可能很高,需合理整合:
One-Hot编码高频标签与class:对出现频次前N的标签或class类别进行独热编码。 聚合统计特征:如“总标签数”、“表单数量”、“图片占比”等简单但有效的数值型特征。 使用预训练模型嵌入:将页面文本送入Sentence-BERT等模型生成整体语义向量,融合结构特征提升效果。 主成分分析(PCA)或自编码器:当特征维度过高时,可对稀疏向量进行降维压缩。
基本上就这些。实际应用中建议结合具体任务(如网页分类、反爬虫、内容去重)选择重点特征方向,避免过度工程化。关键是把HTML从“文档”视角转为“结构+内容+行为”的多维表示。不复杂但容易忽略的是清洗环节——务必剔除广告、页脚、导航栏等噪声区域,才能让特征更有判别力。
以上就是HTML数据怎样进行特征提取 HTML数据特征工程的实践技巧的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/1594310.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫