
1. sql中 union 和 union all 的用法
如果我们需要将两个 select 语句的结果作为一个整体显示出来,我们就需要用到 union 或者 union all 关键字。union (或称为联合)的作用是将多个结果合并在一起显示出来。
union 和 union all 的区别是,union 会自动压缩多个结果集合中的重复结果,而 union all 则将所有的结果全部显示出来,不管是不是重复。
union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;union 在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表 union。
如下sql:
SELECT create_time FROM `e_msku_sku` WHERE msku = '21-BQLEDNL120W-BK'UNIONSELECT create_time FROM `e_msku_sku` WHERE msku = '21-BQLEDNL120W-BK'
结果:
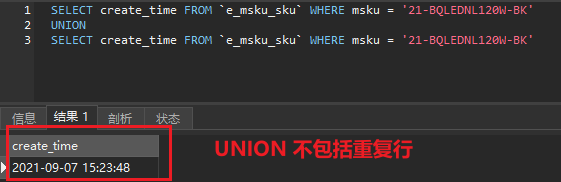
union all:对两个结果集进行并集操作,包括重复行,不进行排序; 如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
如下sql:
SELECT create_time FROM `e_msku_sku` WHERE msku = '21-BQLEDNL120W-BK'UNION ALLSELECT create_time FROM `e_msku_sku` WHERE msku = '21-BQLEDNL120W-BK'
结果:
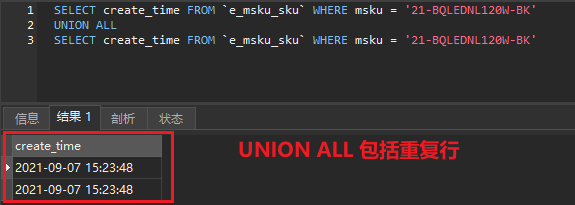
2. 注意事项
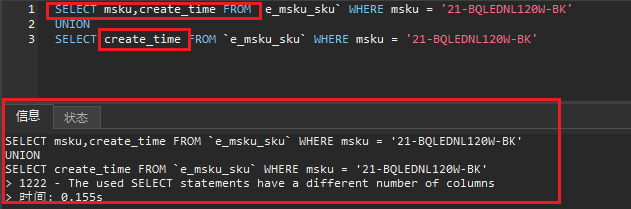
2.1、UNION 和 UNION ALL 内部的 SELECT 语句必须拥有相同数量的列
2.2、每条 SELECT 语句中列的顺序必须相同
先来说下,如果顺序不同,会是什么结果?
答:结果字段的顺序以union all 前面的表字段顺序为准。
union all 后面的表的数据会按照顺序依次附在后面。注意:按照字段顺序匹配,而不是按照字段名称匹配。
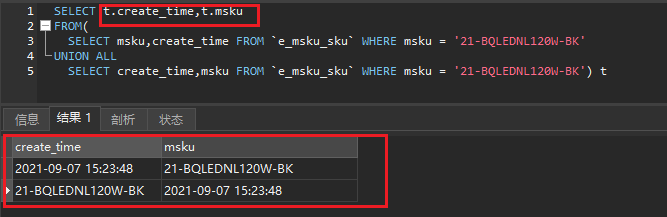
sql如下:顺序对结果的影响
SELECT * FROM(SELECT msku,create_time FROM `e_msku_sku` WHERE msku = '21-BQLEDNL120W-BK'UNION ALLSELECT create_time,msku FROM `e_msku_sku` WHERE msku = '21-BQLEDNL120W-BK') t
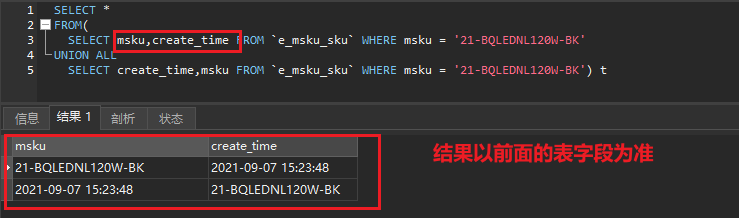
综上:
union all 结果字段的顺序以 union all 前面的表字段顺序为准。union all 后面的表的数据会按照字段顺序依次附在后面,而不是按照字段名称匹配。
我们上面以*来表示顺序的不同,其实你写成不同顺序的字段结果一致。
3. union all 使用场景
sql 中的组合in,可用 union all 来代替,提高查询效率
修改前:组合in sql
SELECT ***, ***, ***, ***, ***FROM e_rating_info WHERE rating_quantity 0 AND (***, ***) IN (('***', '***'), ('***', '***'), ('***', '***'), ('***', '***'), ('***', '***'), ('***', '***'), ('***', '***'), ('***', '***'), ('***', '***'), ('***', '***')) ORDER BY *** DESC
修改后:UNION ALL sql
SELECT ***, ***, ***, ***, *** FROM e_rating_info WHERE rating_quantity 0 AND country_code = #{item.***} AND asin = #{item.***} ORDER BY *** DESC;
另外,如果系统中进行了分表,一定要保证各个表的字段顺序一致。特别是修改的时候。亲身经历告诉我,如果使用 * 来汇总查询结果,一定会有问题。
补充:mysql中union和union all的区别
一、区别1:取结果的交集
1、union: 对两个结果集进行并集操作, 不包括重复行,相当于distinct, 同时进行默认规则的排序;
2、union all: 对两个结果集进行并集操作, 包括重复行, 即所有的结果全部显示, 不管是不是重复;
二、区别2:获取结果后的操作
1、union: 会对获取的结果进行排序操作
2、union all: 不会对获取的结果进行排序操作
三、区别3:
1、union看到结果中ID=3的只有一条
select * from student2 where id 2 and id < 6
2、union all 结果中ID=3的结果有两个
select * from student2 where id 2 and id < 6
以上就是mysql中union和union all如何使用及注意事项是什么的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/162609.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



















