
近期,deepseek r1推理模型在全球社交媒体引发热议,其类人的深度思考能力令人瞩目。然而,deepseek r1、openai o1和o3等模型在一些高难度基准测试中表现欠佳,例如国际数学奥林匹克竞赛(imo)组合问题、抽象推理语料库(arc)难题和人类的最后考试(hle)问题(论文链接)。例如,在hle测试中,主流推理模型的准确率普遍低于10%。
为提升模型在这些挑战性基准上的表现,波士顿大学、NotBadMath.AI和谷歌等机构的研究人员提出了一种创新的多元推理方法,该方法在测试阶段整合多种模型和技术。实验结果表明,该方法在验证数学和编码问题以及其他问题的拒绝采样中高效便捷。
具体而言,研究人员利用交互式定理证明器Lean自动验证IMO问题的答案正确性,通过代码自动验证ARC谜题,并采用best-of-N算法有效解答HLE问题。实验结果显示,该方法将IMO组合问题的准确率从33.3%提升至77.8%,HLE问题的准确率从8%提升至37%,并成功解决了948名人类无法解答的80% ARC谜题以及o3 high模型无法解答的26.5%的ARC谜题。
研究人员指出,通过优化代理图表示、调整提示词、代码和数据集,以及运用测试时模拟、强化学习和具有推理反馈的元学习等技术,可以进一步增强推理模型的泛化能力。此外,他们还发现了基础语言模型的第三个经验性扩展规律:多种模型和方法的数量与可验证问题性能之间存在正相关关系。前两个规律分别为:模型大小、数据大小与损失之间的关系;模型性能与测试时算力之间的关系。
方法概述
研究人员的主要贡献包括:
多元推理 (diverse inference): 测试时,该方法整合多个模型、方法和代理,而非依赖单一模型。任何正确的解决方案都将经过自动验证。具体方法包括:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 喵记多
喵记多
喵记多 – 自带助理的 AI 笔记
 27 查看详情
27 查看详情  IMO:采用8种不同方法(LEAP、Z3、RTO、BoN、SC、MoA、MCTS、PV),并将英语题目自动形式化为Lean进行验证。ARC:合成代码解决方案作为单元测试进行验证。HLE:使用best-of-N作为不完美验证器。
IMO:采用8种不同方法(LEAP、Z3、RTO、BoN、SC、MoA、MCTS、PV),并将英语题目自动形式化为Lean进行验证。ARC:合成代码解决方案作为单元测试进行验证。HLE:使用best-of-N作为不完美验证器。
测试时模拟和强化学习: 推理过程中生成额外的特定问题信息:
IMO:将组合问题转化为交互式游戏环境,利用组合搜索或深度强化学习寻找部分结果或边界。ARC:通过合成代码探索谜题转换,去除错误解决方案并优化候选方案。
研究人员发现,使用训练好的验证器进行搜索通常优于监督微调,这促使他们通过测试时模拟和强化学习生成额外数据,从而成功证明2024年IMO组合题并解决困难的ARC谜题。下图1展示了求解IMO组合题的方法架构,包含编码、模拟、深度强化学习和解码四个阶段。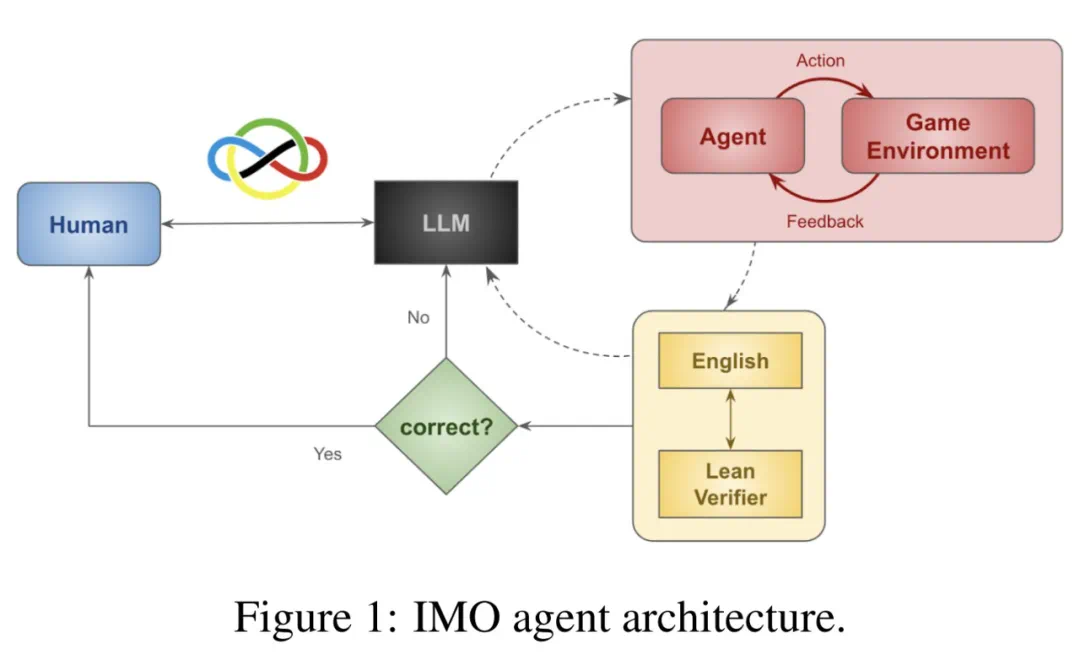
代码图的元学习: 利用LLM和其他工具追踪pipeline运行,生成超参数、提示词、代码标题和数据的A/B测试,并自适应地修改代理图。
实验结果
研究人员对IMO组合问题、ARC谜题和HLE问题进行了广泛评估。结果表明,多元推理方法显著提升了模型在这些难题上的准确率。具体结果见文中图表。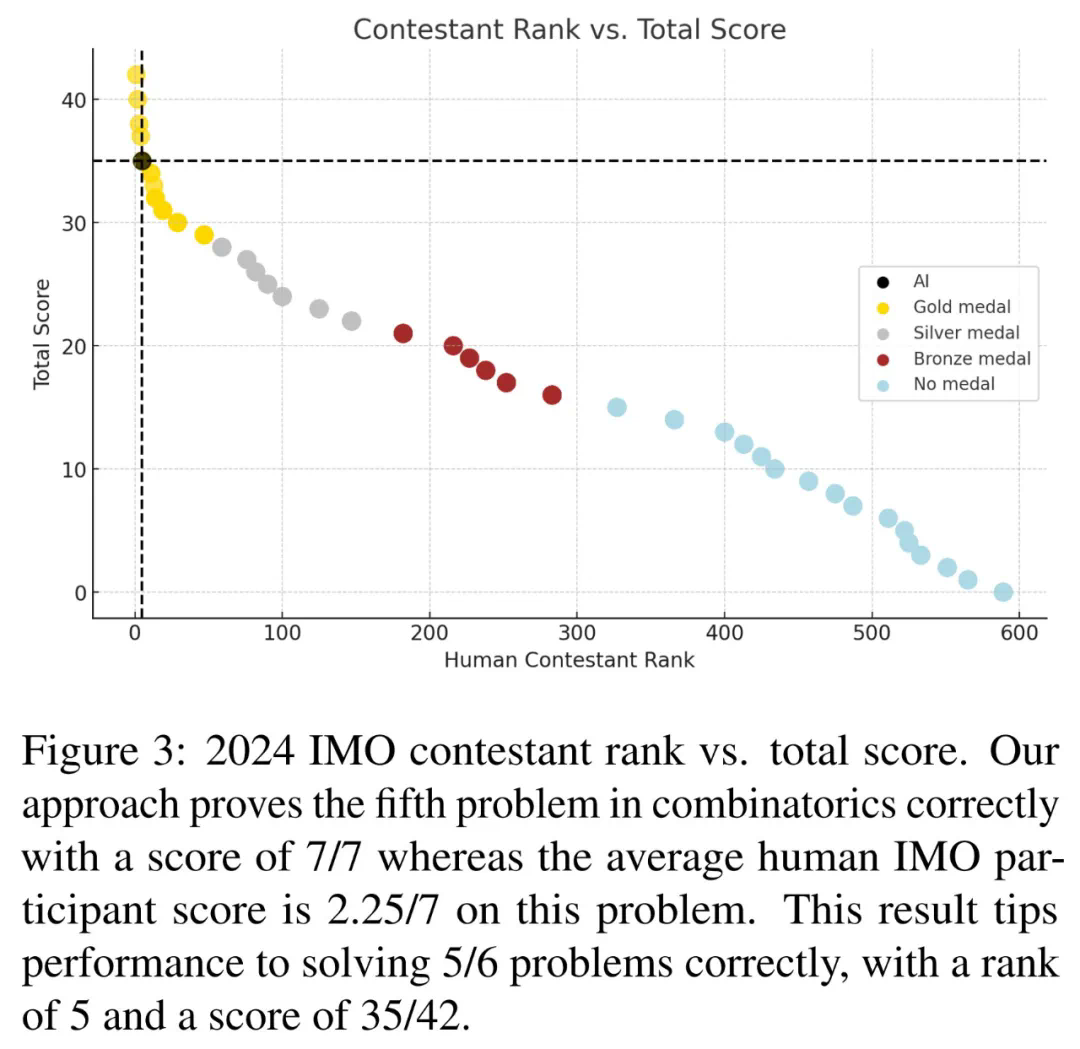




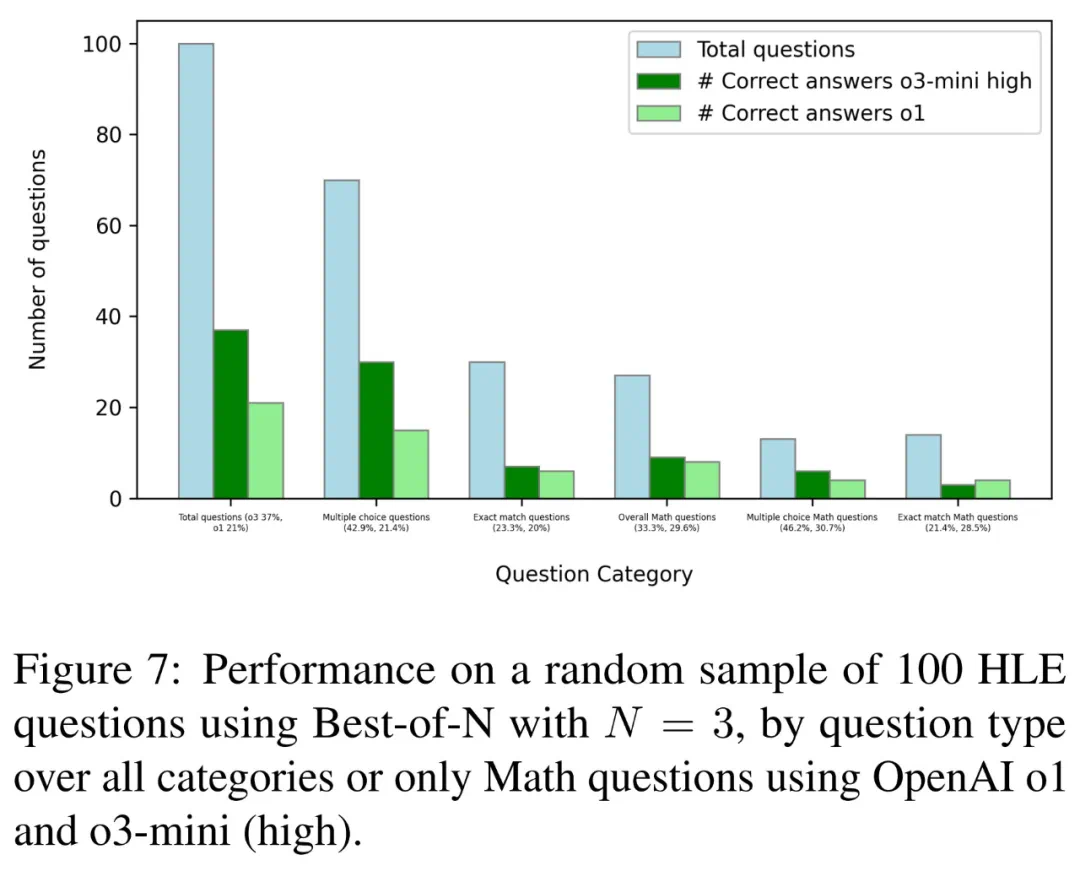 更多细节请参考论文。
更多细节请参考论文。
以上就是多元推理刷新「人类的最后考试」记录,o3-mini(high)准确率最高飙升到37%的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/168460.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















