
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 阿里翻译
阿里翻译
阿里巴巴提供的多语种在线实时翻译网站,支持文档、图片、视频、语音等多模态翻译
 170 查看详情
170 查看详情 
AnyI2V是什么
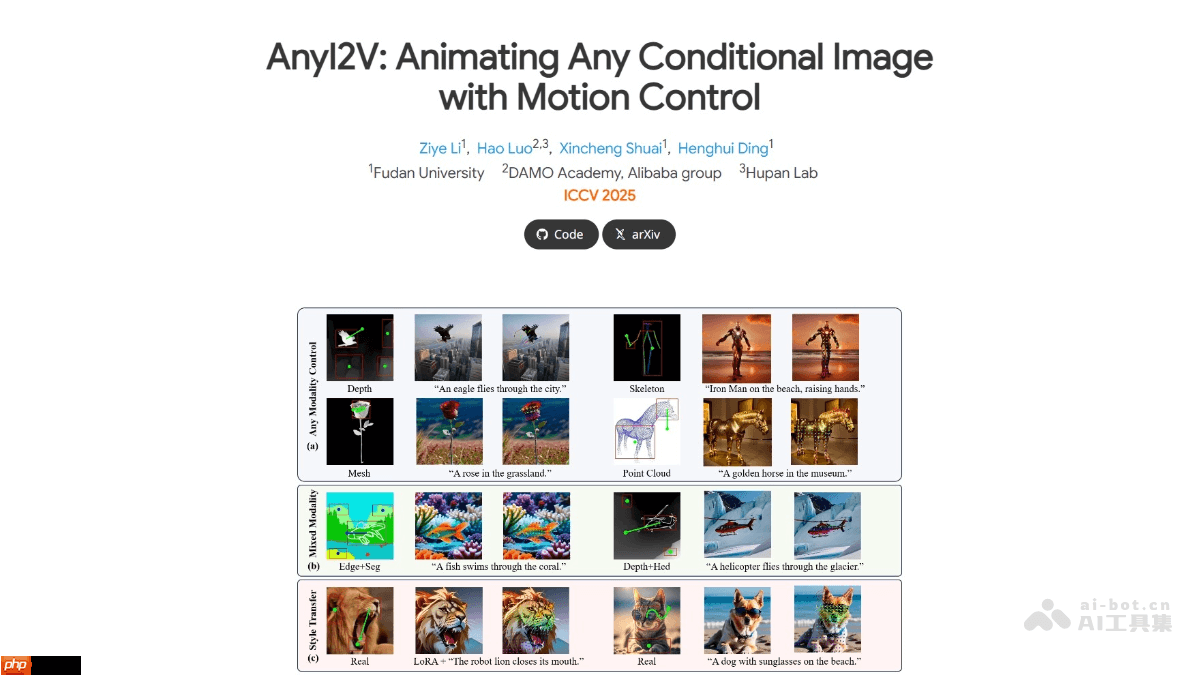
anyi2v是由复旦大学、阿里巴巴达摩院以及湖畔实验室共同研发的一种先进的图像到视频生成框架。该技术无需依赖大规模训练数据,能够将静态的条件图像(如网格图、点云等)高效转化为动态视频,并支持用户自定义运动路径。anyi2v具备多模态输入能力,结合lora和文本提示实现灵活编辑,在空间控制与动作控制方面表现优异,为图像动画化提供了高效且可定制的新解决方案。
 AnyI2V的主要功能
AnyI2V的主要功能
多模态兼容性:支持多种难以获取成对训练样本的输入形式,例如三维网格、点云等。混合输入机制:可同时处理不同类型条件信号的组合输入,显著提升使用灵活性。内容可编辑性:通过LoRA微调或更改文本描述,实现风格迁移、细节调整等图像编辑操作。精准运动控制:允许用户设定具体的运动轨迹,精确引导视频中对象的动态行为。零训练需求:无需额外训练过程或大量标注数据,开箱即用,大幅降低应用门槛。
AnyI2V的技术原理
DDIM反演技术:采用DDIM(去噪扩散隐式模型)对输入的条件图像进行反演处理。该方法通过逆向扩散过程从图像中恢复潜在特征,用于后续视频生成。特征提取与重构:在特征提取阶段,移除3D U-Net中的时间自注意力模块(因输入仅为静态图像,不含时间维度),仅保留并提取空间块中的特征信息,并在特定扩散步长保存这些特征。潜在空间优化:将提取出的空间特征重新注入3D U-Net,在潜在空间中进行优化。利用自动生成的语义掩码限制优化区域,确保修改仅作用于相关部分,提升生成质量与一致性。运动轨迹驱动:用户提供的运动路径作为控制信号输入系统,结合优化后的潜在表示,生成符合指定运动逻辑的连贯视频序列,实现高度可控的动画输出。
AnyI2V的项目地址
官方主页:https://www.php.cn/link/89242c1e4610507f79f8a7b192880778 GitHub代码库:https://www.php.cn/link/1f239457a5b2fb11ddafc392ffd18e1f 论文链接(arXiv):https://www.php.cn/link/16fe58fde1b4617fa7148321b3c0c3c9
AnyI2V的应用场景
动画创作:帮助动画师快速将草图或结构化图像转化为动态预览视频,加速原型设计流程。影视特效:应用于电影与电视剧制作,将静态场景转为动态背景,或为角色添加自然动作效果,增强画面表现力。游戏开发:协助开发者生成角色动画与环境动态元素,提升游戏视觉沉浸感。广告创意:让设计师轻松将平面广告升级为富有动感的短视频内容,提高观众吸引力。社交内容生产:赋能品牌方与内容创作者制作高传播性的动态内容,增强社交媒体互动与曝光效果。
以上就是AnyI2V— 复旦联合阿里达摩院等推出的图像动画生成框架的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/16908.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















