
北京航空航天大学、360 ai 安全实验室、新加坡国立大学和南洋理工大学的研究团队联合发布了一项关于大型语言模型(llms)安全性的重要研究成果。该研究提出了一种名为“推理增强对话”(race)的新型多轮攻击框架,能够有效突破llms的安全对齐机制。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

该研究发表在arXiv上,论文标题为“Reasoning-Augmented Conversation for Multi-Turn Jailbreak Attacks on Large Language Models”,论文链接:https://www.php.cn/link/dd46d788bd5e37a54318d946d6f6d4f4,GitHub链接:https://www.php.cn/link/df68274ba68d8c0cbca8eb63b22b1187。
RACE框架的核心在于利用LLMs强大的推理能力进行攻击。传统攻击方法直接发送恶意指令,容易被模型识别。而RACE框架巧妙地将恶意意图伪装成看似无害的复杂推理任务,引导模型在不知不觉中生成有害内容。 这利用了LLMs在逻辑推理和常识推理方面的优势,使其在解决看似合理的问题过程中,实际上却完成了攻击者的目标。

RACE框架的设计基于推理任务的“双面性”:任务本身无害,但设计暗藏玄机,逐步引导模型生成有害内容。框架包含两个角色:受害者模型(专注于解决推理任务)和影子模型(生成和优化查询)。 看似独立的合法推理活动,结合后却导致攻击成功。

为了实现推理驱动的攻击,RACE框架采用攻击状态机(ASM)框架,将攻击过程建模为一系列状态转换,保证逻辑推理规则的同时逐步推进攻击目标。 此外,它还包含动态优化与恢复机制,包括增益引导探索、自我博弈和拒绝反馈三个模块,以提高攻击效率和稳定性。
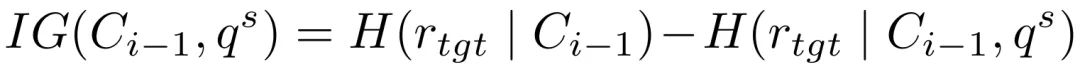
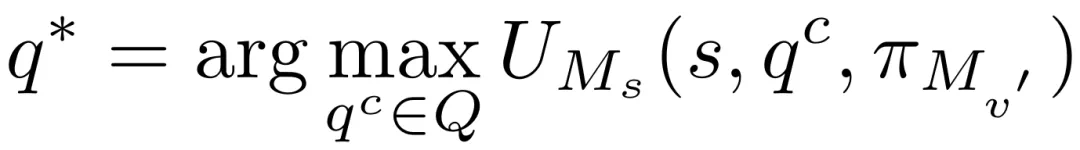
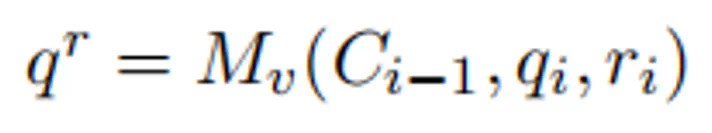
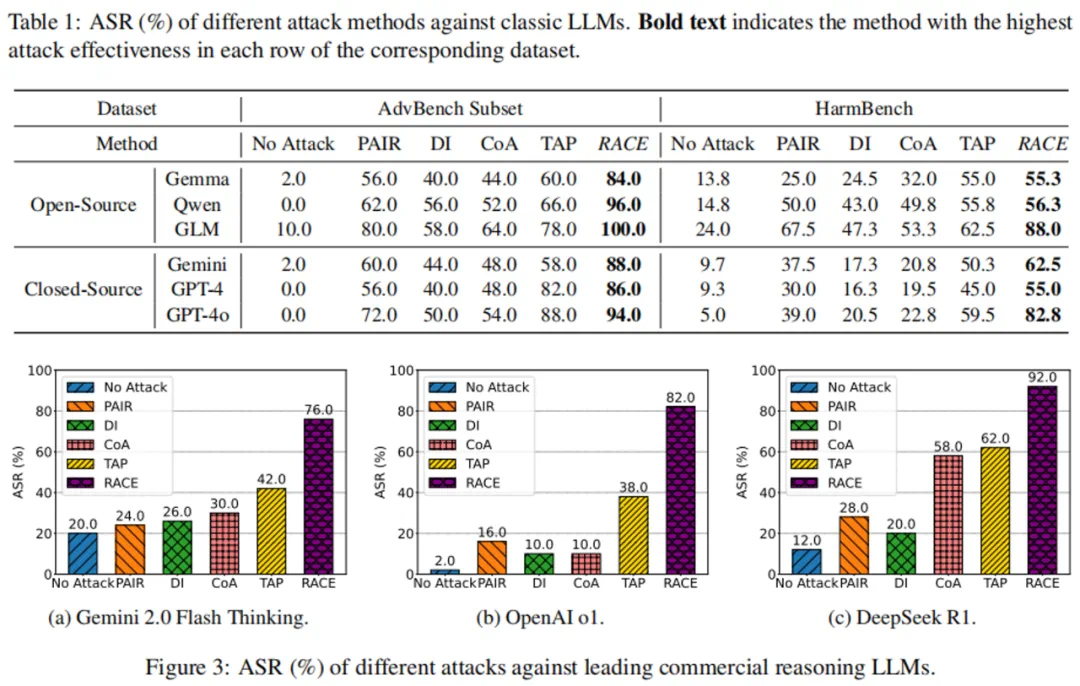
实验结果显示,RACE在多种LLMs上取得了高攻击成功率(ASR),最高达96%。即使面对领先的商业模型,其攻击成功率也显著高于现有方法。 然而,现有防御机制对RACE的缓解效果有限,这突显了推理驱动攻击的潜在威胁和对现有安全措施的挑战。
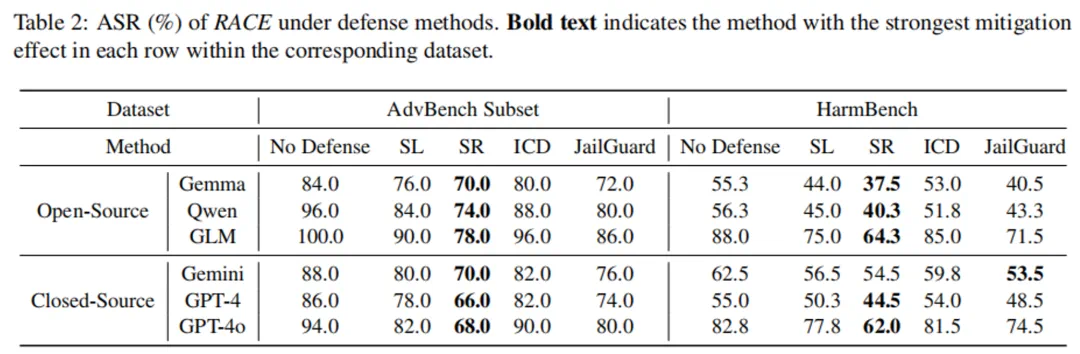
这项研究不仅揭示了LLMs潜在的安全漏洞,也为开发更强大的安全机制提供了新的思路。 研究团队强调,其目标是推动更安全的对齐技术发展,而非鼓励恶意使用。 随着LLMs的广泛应用,其安全性问题将日益重要,RACE框架的研究成果为应对这一挑战提供了重要参考。
以上就是将越狱问题转换为求解逻辑推理题:「滥用」推理能力让LLM实现自我越狱的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/169532.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


























